【泡泡机器人新闻社】来一篇综述,视觉地点识别(上篇)
选文| 胡琪 翻译| 叶培楚 徐礼达 张晨 胡琪 周艺
校对| 周艺 编辑| 周艺
素材来源:Lowry S, Sünderhauf N, Newman P, et al. Visual Place Recognition: A Survey[J]. IEEE Transactions on Robotics, 2016, 32(1):1-19.
泡泡机器人推广内容组编译作品
01
给定一张某个地点的图片,人、动物、计算机或者机器人能否判断之前看过?要解决这个问题,首先,必须有环境的内在表示——即一张地图,用于与输入数据作比较;第二,地点识别系统必须给出当前输入的视觉信息在地图中是否以及在哪个地点出现。同时,视觉地点识别实施面临着很多难题:比如环境外观发生剧烈变化,相似的外观,感知偏差,以及观察视角的变化。

图1 视觉地点识别系统必须做到(a)在不同环境下成功识别同一地点(b)区分相似的不同地点
这篇文章对视觉地点识别及其应用领域包括SLAM,定位,建图和识别进行一个总览,并特别关注了如今很热门的机器人进行长期视觉地点识别这样一个问题。
02
导航和地点识别在心理学和神经科学领域一直是个重要的问题。认知地图的概念在心理学,神经科学,乃至城市规划等领域有着影响力。Lynch [23]提出认知地图的要素包括路径,边缘,节点,区域和地标。在机器人领域,建立地图的方法受到认知地图[24] [25]其后继者空间语义层级结构[26]的影响。
随着记录动物大脑神经活动的技术的发展[27],由O'Keefe和Dostrovsky [28]鉴定出鼠脑海马中的地点细胞[28]。 当老鼠在环境中的特定地点时,地点细胞就会活动[参见图2(a)],并且地点细胞群会覆盖整个环境[29] [30]。网格细胞则映射环境中多个位置,从而形成网格。根据地点细胞的触发机制,地点识别由感官线索和自身的运动信息触发[29]。通过老鼠的研究表明,地点细胞最初是基于自身运动触发,但是如果环境发生变化,例如改变起始和终点目标之间的距离,地点细胞将根据外部视觉信息更新地标[35][36]。
图 2 (a)地点细胞(b)网格。
许多相同的概念出现在机器人技术中。大多数机器人可以获得外部观测数据以及自己的运动信息。地点之间的拓扑和度量关系与感官信息结合使用,从而确定最可能的地点,与地点神经元的机理类似。图3是视觉地点识别系统的示意图。 视觉地点识别系统包含三个关键元素:用于解释视觉数据的图像处理模块,存储机器人对世界知识的图像地图,以及综合传感器数据与地图信息从而做出决定的置信模块。地点识别系统的置信模块也可使用运动信息。此外,大多数位置识别系统被设计为在线操作,因此必须相应地更新地图。
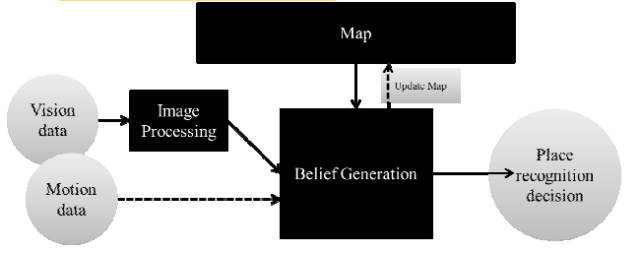
图 3 视觉识别系统示意图。
03
在机器人学里,地点的概念是从机器人导航和建图这个问题中引出来的。在实际的机器人控制中传感器和执行机构并不精确,所以在建立度量世界的精确地图和定位时,会有很大的挑战。而结合这些问题的研究,即SLAM[37]-[41],会更加难以实现。
文献[40]提出了一种代替的方法是使用“关系图”,而不是单纯地试图将观测值放在二维坐标系中。这种拓扑图的概念类似于生物学概念中的认知地图,使用节点来表示空间中可能的地点,边沿来表示地点间可能存在的路径。机器人导航的问题从而转变为沿着节点间的边缘移动,而地点被定义为关键交叉点或者路径间决策点以及目标点[42][43]。
这种基于拓扑方法的导航并非没有困难。机器人必须将抽象的路径和地点与物理路径和地点联系起来,并且需要处理传感器,控制,拓扑地图和度量地图之间的复杂关系[26]。另一个问题是机器人该如何生成拓扑地图。如果机器人可以使用周围环境的度量的格图,用它可以提取拓扑信息,得到一些可用于导航的相对信息,例如开放的空间和通道[44]。除此之外,拓扑图也可以从视觉和运动信息中生成。
地点的定义取决于机器人导航的需求,既可以被看作是一个精确的位置——“环境中一个地点抽象成的一个点”(Kuipers,[26]),也可以作为一个更大的区域——“一个区域的抽象描述”,其中区域定义为抽象出的二维子集来代表(Kuipers,[26])。一个地点可以是相当大的二维空间,例如,建筑物中的一个房间可能单独作为一个地点,也可能被看成是很多不同地点的集合。根据环境或机器人的需求,一个区域还可以被定义为一个三维区域。不同于机器人姿态,地点是没有方向的,因此一直以来,地点识别的一个挑战是姿态的不变性问题,即不论机器人在这个地点的哪个朝向都能确保被识别。
每个地点的位置可以根据空间密度或者时间密度选择。在这种方法中,每隔一个特定的时间步长或者是当机器人运动了一定的距离时,记录一个新的地点。除此之外,也可以根据外观来定义地点。Kuipers和 Byun[25]根据附近场景中的传感数据,即所谓的地点指纹,来进行地点定义。一个拓补意义的地点定义为有着特殊的外观[45][46],当外观发生显著变化时,则可以用物理边界,即“网关(gateway)”[47],来定义。
拓扑地点的概念需要量化 ,也就是说,地点识别系统如何将世界划分为不同的地点? Ranganathan指出这与视频分割中的变化点检测(change-point detection)问题有相似之处[49][50],使用诸如Bayesian Surprise [50]和分段回归(segmented regression)[51]来定义拓扑图中的位置[48][52]。当观测到的外观与当前的环境模型完全不匹配时,这些方法会创造了一个新的地点,因此需要一个新的模型(图4)。同样,Korrapati,Courbon等人[53]使用图像排序分区(ISP)技术将视觉相似的图像组合为拓扑图结点,而Chapoulie,Rives等人[54]将卡尔曼滤波与Neyman-Pearson引理组合。 Murphy和Sibley[55]结合动态词汇建构[56](dynamic vocabulary building)和增量主题建模[57](incremental topic modelling),在环境中不断学习新的拓扑地点。而Volkov,Rosman等人[58]使用了核心集[59](coresets)来分割环境。主题建模,核心集和Bayesian Surprise技术也可用于机器人导航的其他方面,例如总结机器人过去的经历[60]-[62]或确定探索策略[63]。
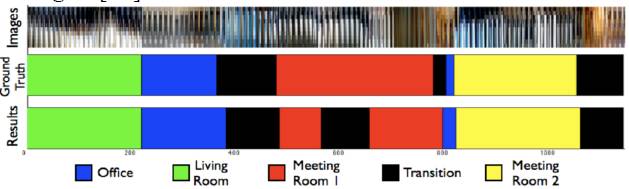
图 4 根据视觉信息,拓扑地点识别系统将图像流分割到对应的位置。当观察到明显变化时,一个新的位置将被创建。在该示例中,输入图像流(顶行)是基于检测到位置点的改变来分割的。检测到的位置(底行)与实际位置(中间行)大体上一致。
基于外观和基于密度的地点选择方法是可以实现的,这是因为他们依赖于一些可测量的量,比如距离,时间或者传感器值[64]。目前所面临的挑战是如何通过语义标签例如“门”或“交叉点”来地点。地点识别与物体识别是相辅相成的——即地点识别可以为物体识别提供预激并为物体定位提供先验条件[66];目标识别也可以帮助更好的进行地点识别[67]-[70],特别是在室内场合,例如可以从房间中的物品来判断“厨房”或“办公室”,并于从标记的语义地图中推断位置[71]。
04
基于视觉的地点描述方法可以分为两大类:基于提取关键点的方法,以及对整张图片进行描述的方法。对于第一类方法,一些常用的特征点有SIFT [72] 以及SURF [73]。对于第二种方法,常见的全局描述因子有Gist [74] [75]。

图 5 视觉地点识别技术分为两大类:(a)关键点被提取,描述,存储。红色圆圈中的点为SURF特征点。(b)全图的描述子,比如Gist,把图片分为区块,忽略其内容直接处理每个块
A.局部特征描述因子
尺度不变的特征点选取方法广泛运用于地点识别 [76]–[83]。一些其他的局部特征识别方法也被用于基于视觉的定位以及地点识别问题。例如,Harris仿射区域方法[85], SURF [73], CenSurE [88] 的方法。由于选取特征点要基于两步,先提取关键点后并计算描述因子,混合两种不同的方法并不奇怪。比如,Mei,Sibley [89]等人运用FAST [90]方法选取图中的关键点,然后用SIFT方法去描述。Churchill和Newman [15]用FAST提取并用BRIEF [91]描述
每张图片可能包含上百个特征点,直接进行暴力匹配是很低效的做法。词袋模型把特征转化为可以比较的词从而提高效率。对于每张图片,每个特征被分配一个特定的词,忽略其几何或空间结构,从而使图片退化为二值字符串或柱状图

图 6 词袋模型把相似的特征分类到了同一个视觉词汇从而使识别变的高效直观。该图中的图块均可以用窗户边框这个词来代表。
运用词袋模型描述的图像可以根据Hamming距离或者Histogram进行高效的比较。对于大规模的地点识别,词树更加高效。词树最初用于物体识别,他运用了一个层级模型定义词,从而实现快速查询并使大型词的运用成为可能。运用词袋方法做定位的例子有很多,例如[82], [84], [87], [96], [97]。
由于词袋模型忽略了地点的几何结构,其得到的地点描述是与位姿无关的,也就是说,机器人该地点的任何位置上都可以进行识别。但是,运用地点的几何信息可以增加算法的鲁棒性,尤其是在环境发生改变时[14], [87], [98]–[100]。这些系统可能假设可以运用激光获得3D信息[98],运用立体视觉[14],极线约束[100], [101],或者根据图片内元素的位置来定义场景的几何结构[102], [103]。但是两个不变的妥协问题:位姿不变,即识别地点与机器人的方向无关;条件不变,即在视觉环境发生变化的情况下识别地点,还尚未解决,这也是当前地点识别研究的挑战。
词袋模型一般根据从训练集提取的特征点进行预定义。这种方法获得的模型与环境相关,如果机器进入了新环境,需要重新训练。Nicosevici和Garciat提出了一种在线方法根据观察持续更新词汇,并且可以匹配现在以及未来的观测。因此,词袋模型并不需要预训练阶段,并且可以适应环境,在性能上超过了预训练的模型,尽管需要一些少量的先验知识。
B.全局描述因子
全局地点描述因子用于在早期的定位系统中,其包括颜色直方图[5]和基于主元素分析的描述因子[104]。Lamon等人综合各种图像特征,例如边,角和颜色,形成了地点的“指纹”。记录0-360度各个方向的特征形成特征序列,从而把地点识别转化为字符串的比较问题。这种系统运用全角度的照相机从而保证每个方向的特征均可记录下来,实现旋转不变。
通过预先确定图像中的关键点,全局描述因子可以从局部特征描述因子中生成。Badino [108]等人对整张图片计算基于SURF的描述因子,这种方法被称为WI-SURF,BRIEFGist[109]对整张图片计算基于BRIEF [91]的描述因子。
Gist是一种很流行的全图的描述因子,他被用于各类地点识别问题[110]–[113]。Gist运用Gabor滤波器提取图像信息。对其计算结果取均值从而生产一个描述场景“要点”的向量。
C.运用局部与全局方法描述地点
局部与全局方法二者各有优缺点:局部特征描述子并不局限于仅定义机器人先前的位姿,而是可以重新组合以创建未被访问过的新位置。例如,Mei, Sibley等人在 [114] 中提出,系统通过在landmark co-visibility map中发现单帧实时可见的地标,来进行优于基于标准图像的位置识别 [78]。Lynen,Bosse等人[115]则生成二维描述子投票空间,高投票数者为闭环检测候选。
[2][7][76]指出局部描述子同样可以将局部特征和度量信息相结合,来优化定位。但全局描述子则不具有这样的灵活性,相比于局部描述子更受回访时机器人姿态改变的影响,因为在其比较方法中假设回访时视角不变。这个问题可以通过在[116]中使用的circular shifts或[17][110]中联合BOW词袋模型和Gist的方法来改进。
虽然全局描述子比局部特征描述子更依赖于姿态,但[117]指出在光照改变的环境下局部描述子的表现很差,并且[118][119]说明了在变化情况下局部描述子的表现不及全局描述子。因此在图像分割块上使用全局描述因子或许不失为一种折中的方法,因为足够大的图像片段能表现出整张图片对环境变化的不变性,而足够小的图像片段具有局部特征对于观察姿态的不变性。 McManus, Upcroft等人在[120]中在图像块上使用全局描述子HOG来获取不随环境条件改变的场景签名;Sünderhauf, Shirazi等人则在[122]中使用Edge Boxes 物体提取方法 [123] 联合中层卷积神经网络特征[124]来确定和提取路标。

图 7 Edge Boxes method [123]——用于物体检测,也可以用来识别潜在的地标。其中彩色方框显示了两个视点之间已正确匹配的地标。
D.包含三维信息的地点描述
上述图像处理技术均基于视觉外观,但在度量定位系统中,基于外观的模型必须联合度量信息。尽管许多系统使用其他传感器,例如[98]的激光以及[127]–[129]的RGB-D相机,几何信息也可以借由传统的相机通过机器人位置的计算获得。
运用立体相机可以获得尺度信息[2][129]-[131],单目摄像机也可以利用Structure-from-Motion算法推断出度量信息[133],方法包括MonoSLAM [7], PTAM [134], DTAM [135], LSD-SLAM [136]以及ORB-SLAM [137]。度量信息可以是稀疏的:来源于特征点,比如MonoSLAM [7]的图像块,Se, Lowe [76]的SIFT,FrameSLAM [2]的CenSurE以及ORB-SLAM [137]的ORB [138]。度量信息也可以是稠密的:来源于像素点,DTAM存储了所有像素的稠密度量信息,LSD-SLAM也保存了包含结构和信息的半稠密的深度数据。稠密的度量数据使得机器人具有避障和度量规划以及建图和定位的功能,因此可以执行全自动视觉导航[16]。
RGB-D相机等新型传感器能够提供稠密的深度信息以及图像数据,从而极大地促进了稠密地图的发展[70], [127]–[129], [139], [140]。这些传感器还可以获得三维的目标信息从而辅助场景识别。SLAM++ [70]存储了一个三维物体模型数据库,并在导航期间执行物体识别,将其作为高级地点特征。与低级的地点特征比,这种做法不仅能提供丰富的语义信息,并且减少了内存需求(因为在地图中只需存储物体标签而不是完整的物体模型)。
#泡泡机器人新闻社-近期回顾#





