虚拟主播上线!多模态将改变人机交互的未来

因此,视频平台如果能够提高观众的观看体验,自然能够吸引更多观众。爱奇艺便是众多试图利用技术改善用户服务和体验的在线视频平台之一,他们采用的一项技术,就是今天这篇文章的主题——多模态技术。视频中最重要的信息,包括音频信息和视频帧信息,单独利用某一个模态的信息,会比较局限,难以全面的对视频内容进行理解,而多模态能够综合多模态信息,让视频服务和功能更贴近人类真实生活习惯,对于视频内容理解非常必要。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
2016 年,爱奇艺在世界竞赛 emotioW 视频人脸表情识别国际竞赛中,综合利用人脸和音频的多模态信息获得比赛第一名,在这一契机下,爱奇艺从此开始进行多模态方面更加深入的研究。
为了促进多模态技术研发,爱奇艺在 2018 年举办了爱奇艺多模态视频人物识别挑战赛,发布了当时全球首个最大明星数据集(iQIYI-VID)。目前,2019 年爱奇艺视频人物识别挑战赛已经启动,3 月 18 日爱奇艺开源了最接近实际媒体应用场景的视频人物数据集(iQIYI-VID-2019)。与 2018 年的数据集相比,这个数据集更具有挑战性,总共包含 10000 个明星人物、200 个小时、20 万影视剧与短视频人物数据集,全部采用人工标注。相对于 iQIYI-VID,iQIYI-VID-2019 增加了 5000 个明星艺人,新增人物主要来自短视频,包括化妆、特效、不同场景的动作等。
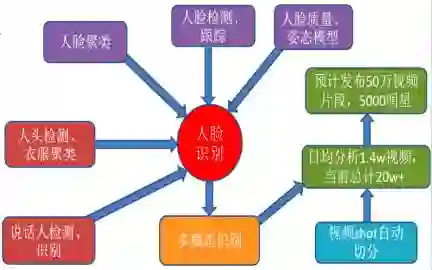
iQIYI-VID 数据库生产流程

iQIYI-VID 视频人物库样本实例
iQIYI-VID-2018 数据集链接:http://challenge.ai.iqiyi.com/detail?raceId=5b1129e42a360316a898ff4f
iQIYI-VID-2019 数据集下载链接:http://challenge.ai.iqiyi.com/detail?raceId=5c767dc41a6fa0ccf53922e7
这些数据集,是爱奇艺在业务中落地多媒体技术的基础,有了这些数据,才让展开各种实践成为可能。
爱奇艺已经将视频识别技术应用于实际业务中,上线了一系列基于 AI 技术的产品,如只看 TA、电视端 AI 雷达、Starworks 智能生产、爱创媒资系统、艺汇选角、广告创可贴点位、智能审核系统等。这些基于 AI 的技术可以帮助爱奇艺提升人物识别精准度,优化爱奇艺生态系统,以下为多模态技术在爱奇艺实际业务场景中的一些应用实例及其技术详解:
在爱奇艺 APP 中,只看 TA 这个功能可以使得用户在观看视频的时候,可以选择只看某个演员或只看某对 CP 的功能,这是 AI 人物识别技术在爱奇艺的一个典型应用。目前,只看 TA 已经实现完全自动化的分析,该功能已经在爱奇艺 APP 移动端上线。

爱奇艺 APP 端的只看 TA 功能:只看吴谨言的片段,只播放进度条中绿色为吴谨言片段
只看 TA 背后的技术设计利用人脸识别、人体识别及场景识别等信息,可更精确地捕捉视频画面,打破单模态的局限,为用户带来更为个性化的观看体验,并保证人物只看 TA 信息的剧情的完整性。
爱奇艺 TV 端的银河奇异果 -AI 雷达这个功能让用户在看电视时可以通过按遥控器上健来识别画面中的人物,背后的身份识别技术也用到了多模态,比如为了保证只看 TA 人物片段的剧情完整性,除了人脸识别技术,还需要结合场景识别、音频分析技术。
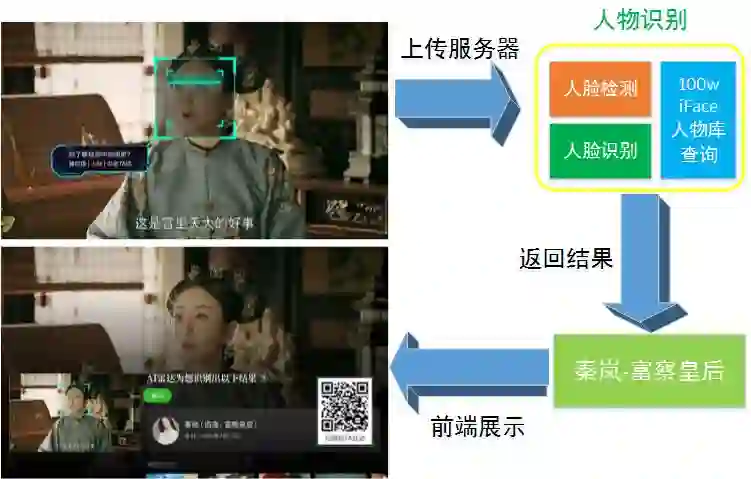
AI 雷达 - 电视中的人物角色瞬间可知
聊天斗图、看剧追星、搞笑沙雕,你的聊天页面永远缺一个有趣的表情包!爱奇艺基于日益增长的表情分发需求及场景,结合 AI 技术和爱奇艺 IP 视频资源,设计了一款通过 AI 生产动图 + 人工运营 +IP 设计模式的表情分发产品——逗芽表情小程序。逗芽表情不仅可以通过 AI 技术自动识别视频中的人物表情并截取生成动图,还根据识别出的人物情绪自动匹配上相同情感的文字。目前逗芽表情日均可更新 5000 张高质量动图,并实时追踪热点,保证了动图的新鲜度和丰富度。

逗芽表情及文案生成
在追星族中,盛行着剪辑爱豆视频的风气,有才华粉丝不但会想方设法把所有关于爱豆的镜头剪辑到视频中,甚至会把素材自编自导成有故事有情节的小剧场,被称为“剪刀手”。但是,剪辑爱豆视频是一个痛并快乐着的过程,在浩如烟海的视频中找到并剪辑关于爱豆的镜头非常耗时耗力,煞费心血。现在,爱奇艺基于多媒体技术的明星视频混剪 Starworks,就可以让这些“剪刀手下岗”了。
Starworks 可以实现根据剧本自动搜索素材,智能生成符合某个话题的视频集锦,支持不同画面的不同输出方式,如横竖屏效果、自动卡点配乐、台词集锦、CP 等。如漫威老爷子,在他的 100 部大片中,他均有几秒钟的客串镜头,如果有人在他去世的时候想剪辑出只有他出现的镜头并拼接成短视频来纪念他,纯人工的工作量有多大可想而知。但是,Starworks 可以在不到 1 分钟内完成。
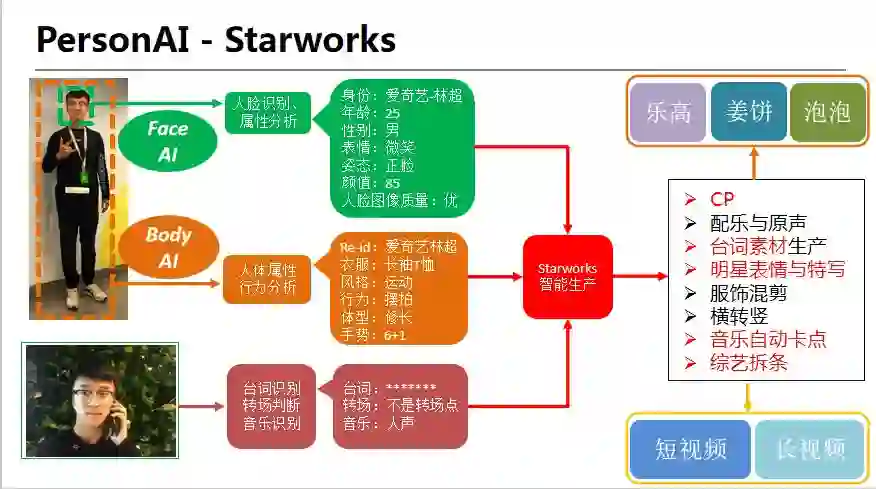
Starworks 智能生产流程图
以此为例来说明一下,Starworks 是如何做到在一分钟之内完成只看 TA。
首先,爱奇艺长视频中所有的人物,都已经用人脸识别技术打上了明星的点位信息,爱奇艺拥有百万级的明星人物库,使得人脸识别可以识别出从一线到十八线的相关明星艺人;然后,人工需要设置视频时长、人物、剪辑模式、配乐与否等信息,AI 根据这些设置参数,直接输出该明星的视频。也就是说 Starworks 自动生产视频,其实分为两步,一是给视频打点,二是镜头合成策略。合成策略里会分为好多子模块,就像一个剪辑师有自己的素材库、音乐库、特效库、花字库一样,AI 这里除了有这些库以外,还有不少算法来模仿剪辑师的行为,如音乐分类、节拍点检测等算法,来完成镜头与音乐的匹配合拍等。
Starworks 还可以利用台词搜索,实现相同或相关台词的集锦。比如《延禧攻略》这个巨火的宫斗剧,你知道有多少人骂魏璎珞“疯了”吗?有多少人嫉恨魏璎珞,歇斯底里地骂她“贱人”吗?Starworks 根据台词索引,可以马上把相关片段找出来,是不是很疯狂?
这个功能涉及到的技术主要包括人脸识别、人脸表情等属性识别、场景识别、服饰和职业识别、台词 OCR、NLP、声音和音乐检测、音乐节拍点提取、镜头切分、专场特效、视频滤镜等模态。
Starworks 还可以人脸表情识别,如吴亦凡是不是很酷?很少见他笑?Starworks 可以根据表情搜索,找到所有吴亦凡的笑的镜头。
在人脸识别方面的进步得益于爱奇艺创建的明星人物库,收录了 100 万多知名明星或不太知名的艺人,同时,爱奇艺 AI 技术会监听热搜、播放 VV 等多方数据,将大家感兴趣的明星人物自动同步到爱奇艺明星人物库,完成人脸识别模型的快速更新。
此外,爱奇艺的人脸识别技术不仅支持真人识别,还支持卡通角色识别。爱奇艺的卡通角色库已经支持热剧中 2 万多卡通角色,是目前已知的最大规模卡通角色库,也是爱奇艺 AI 技术独有的虚拟形象识别。
在爱奇艺科学家、PersonAI 团队负责人路菊香看来,要实现完美的情绪识别和分析、视觉语义化,我们还有很长的一段路要走。人和机器最大的区别在于,人有感情,而机器没有,这就是机器人在现在和未来永远都不可能取代人类的原因之一。识别人的情绪,人机交互才能进行得更加顺畅,让人更有代入感,但目前在情绪识别和分析这一方面,AI 技术还任重而道远。
路菊香表示,所谓的情感识别,在 AI 里就是转换成某种行为的标签,比如对于爱情,AI 可以识别 CP 同框,以及两人是否拥抱、接吻、牵手、微笑等,但是并不知道两个人是否真的相爱。所以,AI 识别情感,只能从这些标签中抽象,但有时候,仅从标签中无法抽象出来一些感情的。目前,AI 情绪识别主要用于识别表情、声音、台词等标签,爱奇艺在这些方面均有应用,如 Starworks 生产符合某个主题的视频,需要综合利用多种标签。
另一方面,人类接收信息的方式多种多样,包括听觉、触觉、嗅觉等,但是最重要的方式还是视觉,因此,视觉语义化对人类来说是一个具有重要意义的应用方向。
路菊香介绍道,从多模态学习到视觉语义,一般有两种方式:一种是输入多模态特征,输出高层语义,直接训练,即端到端的黑盒模式;另外一种是输入单个模态的特征,提取单模态的标签,再从这些标签中抽象出高层语义。现实应用中往往根据具体问题,多种策略并用。
目前,视觉语义化已经可以结合人脸、表情、行为、台词等方式进行视频内容的简单描述,并进行检索人物情感分析,而这些从单一模态难以获得准确的结果。因为人的表达是通过表情、声调、语言三个方面来综合进行的,所以多模态信息的利用是最准确的解决方案,在多个维度上建立视频的标签 gragh,节点表示不同模态的标签输出,节点的连接表示标签的关联,实现语义化的推理,视频人物表情识别。
但是,利用视觉语义化完成更多日常任务,业界仍在努力。
将多模态技术应用于视频业务场景中不是一件容易的事。路香菊表示,多模态技术应用的主要难点在于,多模态信息不能生搬硬凑,需要探索高效整合的方式,挖掘各模态之间的信息关联性和可迁移性,采用模型学习和人工先验结合的方式进行多模态信息整合,其中,文本的抽象内容标签和图片、音频的具体标签的对应关系是最困难的,简单来说,就是多模态信息融合策略、如何加速的问题。
路香菊建议应该具体问题具体分析,主要难点在于各个模态的关联表达与融合,如在人物识别时,声纹特征与身体特征有时都可以有效地表示人的身份,但是,两者加起来,并不一定会达到更好的效果,如何将两者有效地结合在一起,如何把人的身份信息综合在一个超维度上表达,是非常有挑战的。
在国内,多模态研究相对国外来说起步较晚,目前还是集中在诸如情感识别、人物识别、音视频语音识别、事件检测等比较传统的方向。
但是,国内多模态研究的发展速度非常快,目前在一些主流的学术数据库上已经达到了世界领先的水平,比如爱奇艺在 2016 年的 EmotioW 情感识别竞赛上取得了第一名,超过了英特尔和微软;在在 iQIYI-VID 多模态人物识别数据集上,爱奇艺利用多模态技术也取得了最高的精度。
在应用方面,国内的多模态技术已经基本实现了和国际同步,爱奇艺在视频智能生产的多个项目中都采用了多模态技术,如视频说话人身份识别,爱奇艺使用了人脸、台词、声纹来精确判断哪句台词是谁说的,这是视频理解当中的一个最核心问题;另外,爱奇艺还实现了视频和表情包的自动配乐,音乐节拍提取和明星精彩片段切分来实现明星的视频混剪,都实现了业务落地。
在路菊香看来,爱奇艺的手语主播,以及有些公司推出的虚拟主持人,都是今年来多模态应用的一个里程碑。虚拟人物形象的出现,代表多模态已经可以简单模仿人的行为,完成特定的使命。
多模态未来的应用前景广阔,比如表情包自动配文案算法,采用的就是多模态内容迁移来实现表情包的自动生成。另外,学术上也一直有一些很活跃的方向,如看图说话、跨模态内容检索、视觉问答等。
路菊香表示,多模态技术未来发展的方向,会越来越打破单模态输入输出限制,从而更贴近人类真实使用习惯,因为在人类的实际生活中,多模态是无处不在的。在人类日常生活当中,综合利用多模态信息可以帮助我们更准确的理解人类行为,如学生上课状态监控、健康监护等。

路香菊博士,爱奇艺科学家,PersonAI 团队负责人,专注人物识别及视频分析,创建百万人物库及两万卡通库。组织创办“爱奇艺多模态视频人物识别赛”,开放全球首个影视视频人物数据库 iQIYI-VID。
今日荐文
点击下方图片即可阅读

微软亚洲研究院周明:NLP进步将如何改变搜索体验
人工智能成了新时代的必修课,但它包含的内容浩然入海,如何应对复杂的模型和算法?大数据如何驱动人工智能?是否要有数学基础和工程经验?所涉及领域之多让人望而却步。
2019年超100位技术大牛将结合自己的积累和思考,分享他们的进阶秘籍,还有架构、前端等领域的干货内容,通过极客时间企业账号为团队制定学习计划还有福利。


你也「在看」吗?👇



