【CNN调参】图像分类算法优化技巧(实用性很高)
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转载自:GiantPandaCV
★这篇论文整理了CNN分类任务中一些常用的Tricks,如改善模型结构,训练过程中的一些Refinements如修改损失函数,数据预处理等,有较大工程意义。
”
1. 前言
这篇论文的全名是:Bag of Tricks for Image Classification with Convolutional Neural Networks 。论文地址见附录。这篇论文是亚马逊团队对CNN网络调优的经验总结,实验基本是在分类网络实验上做的。目前,论文的复现结果都可以在GluonCV找到,地址为:https://github.com/dmlc/gluon-cv。可以将这篇论文理解为一堆经验丰富的工程师的调参技巧汇总,无论你是在做比赛,做学术,还是已经工作的AI开发者,相信都能从中受益。
2. 成果
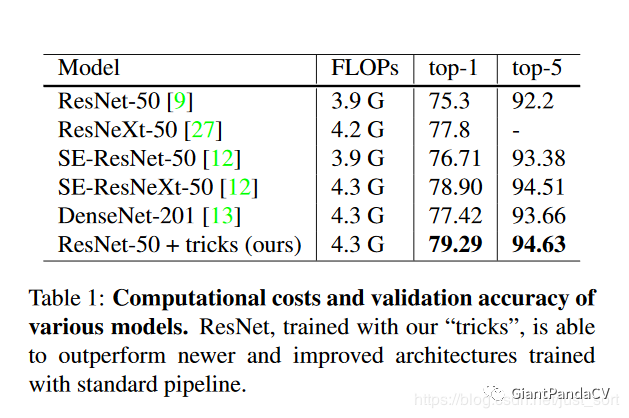
下面的Table1展示了本文的一系列Tricks被用在ResNet50网络做分类任务上获得的结果。
2. BaseLine
既然涉及到调参,那么第一步就得有一个BaseLine的结果作为参考,这一BaseLine并非直接截取之前对应的论文的结果,而是作者基于GluonCV复现的。关于复现的细节作者在论文2.1节中说的很清楚,包括数据预处理的方式和顺序,网络层的初始化方法,迭代次数,学习率变化策略等等。
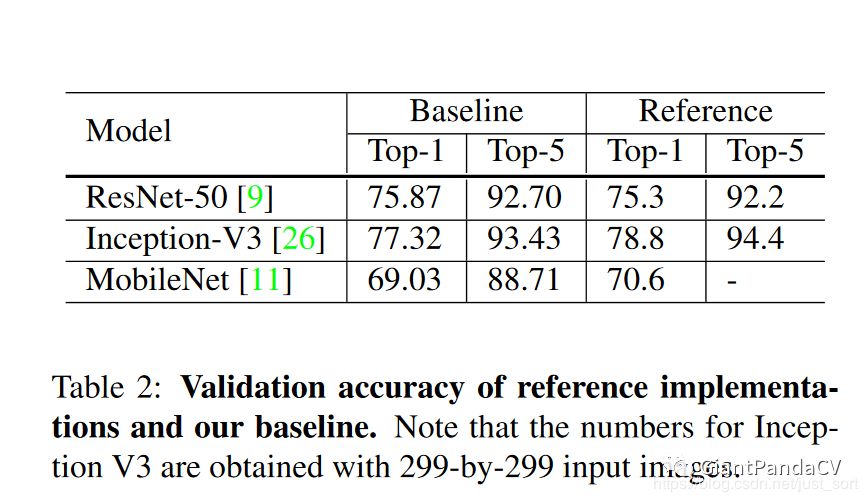
下面的Table2展示了作者复现的ResNet-50,Inception-V3,MobileNet三个BaseLine。
3. 训练调参经验
介绍完BaseLine,接下来就来看看作者的优化方法。论文从加快模型训练,网络结构优化以及训练参数调优三个部分分别介绍如何提升模型的效果。
3.1 模型训练加速
关于模型训练加速,论文提到了2点,一是使用更大的Batch Size,二是使用低精度(如FP16)进行训练(也是我们常说的混合精度训练)。关于使用更大的Batch Size进行训练加速,作者指出一般只增加Batch Size的话,效果不会太理想,例如FaceBook这篇大名鼎鼎的论文有证明:
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
然后本文总结了几个重要要的调参方案,如下:
-
增大学习率。因为更大的Batch Size意味着每个Batch数据计算得到的梯度更加贴近整个数据集,从数学上来说就是方差更小,因此当更新方向更加准确之后,迈的步子也可以更大,一般来说Batch Size变成原始几倍,学习率就增加几倍。 -
Warm up。Warm up指的是用一个小的学习率先训练几个epoch,这是因为网络的参数是随机初始化的,假如一开始就采用较大的学习率容易出现数值不稳定,这也是为什么要使用Warm up。然后等到训练过程基本上稳定了就可以使用原始的初始学习率进行训练了。作者在使用Warm up的过程中使用线性增加的策略。举个例子假如Warm up阶段的初始学习率是0,warmup阶段共需要训练m个batch的数据(论文实现中m个batch共5个 epoch),假设训练阶段的初始学习率是L,那么在第 个batch的学习率就设置为 。 -
每一个残差块后的最后一个BN层的 参数初始化为0。我们知道BN层的 , 参数是用来对标注化后的数据做线性变换的,公式表示为: ,其中我们一般会把 设为1,而这篇论文提出初始化为 则更容易训练。 -
不对Bias参数做权重惩罚。但是对权重还是要做的。。
接下来作者提到了使用低精度(16-Bit浮点型)来做训练加速,也即是我们常说的混合精度训练。但不是所有的NVIDIA GPU都支持FP16,我大概只知道V100和2080 Ti是支持混合精度训练的。
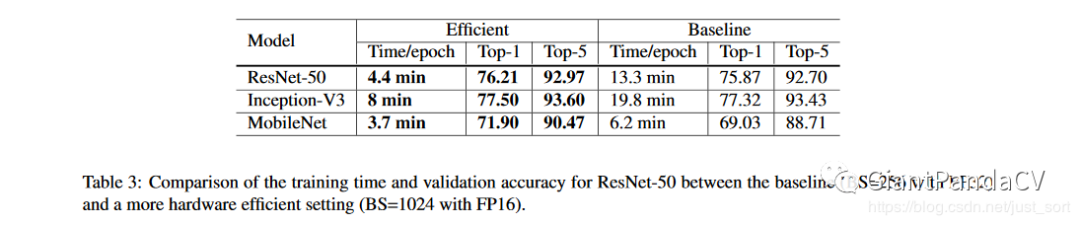
作者将上面的Tricks结合在一起进行训练,下面的Table3展示了使用更大的Batch Size和16位浮点型进行训练的结果,可以看到这俩Tricks相比于BaseLine训练速度提升了许多,并且精度也更好了。
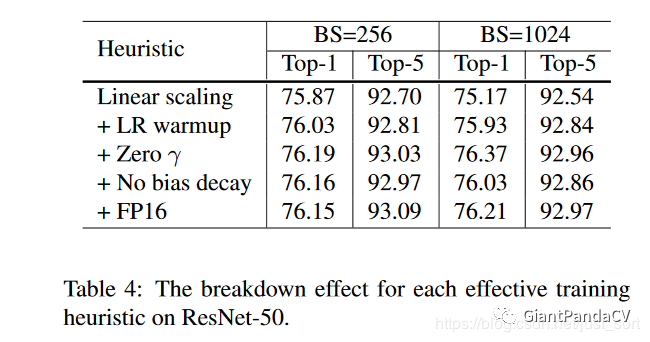
而下面的Table4则进一步展示了这些Tricks的消融实验,证明确实是有效的。
3.2 网络结构调优
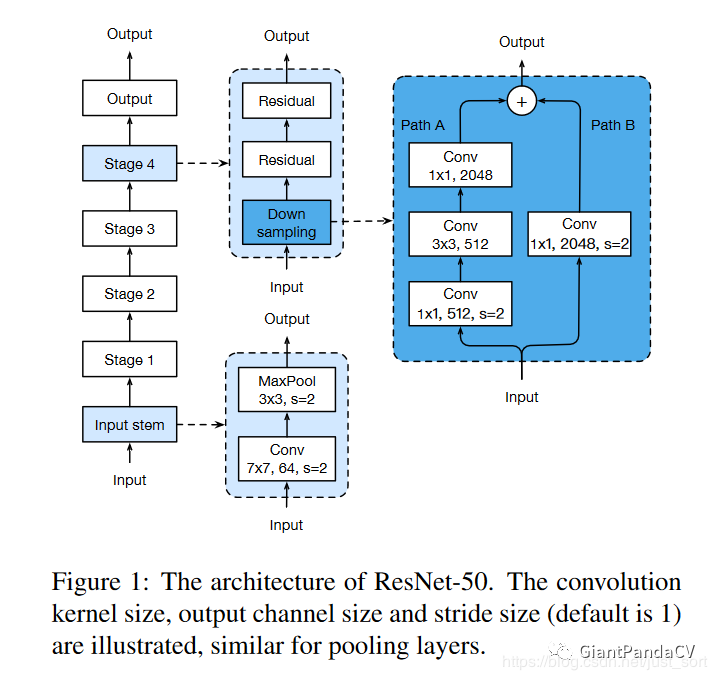
这一小节以ResNet-50为例子展开,下面的Figure1表示ResNet网络的原始结构图,简单来说就是一个输入流加4个stage和一个输出流。其中输入流和每个stage的详细结构在Figure1中间那一列显示,而残差结构则在Figure1中最右边进行显示。
论文在网络结构部分进行改进获得的3种结构如Figure2(a),(b),(c)所示:
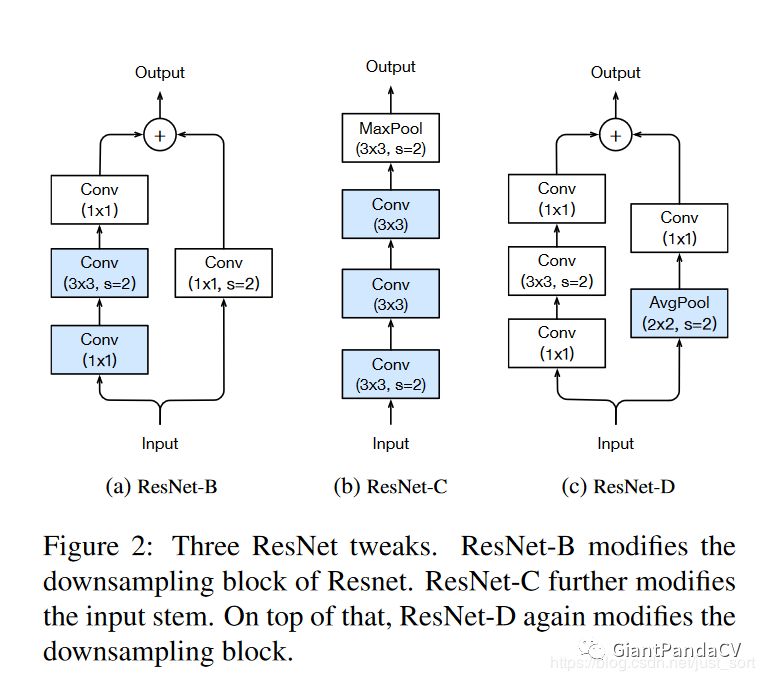
-
ResNet-B。ResNet-B改进的地方就是将4个Stage中做下采样的残差模块的下采样操作从第一个卷积层换到第三个卷积层,如果下采样操作放在 的 卷积层,那么会丢失比较多的特征信息(通道缩减默认是 ,所以会丢失 ),而将下采样操作放在第 个卷积层则可以减少这种损失,因为即便 ,但是卷积核尺寸更大,保留有效信息更多。 -
ResNet-C。ResNet-C改进的地方是将Figure1中的输入流部分的 卷积用两个 卷积来替换,这部分借鉴了Inception V2的思想,主要是为了减少运算量。但很遗憾,从后面的Table5可以看出 个 卷积的FLOPS比原始的 + 卷积的FLOPS还多。。 -
ResNet-D。ResNet-D改进的地方是将Stage部分做下采样的残差模块的支路从 的 卷积层换成 的卷积层,并在前面添加一个p平均池化层来做下采样。个人猜测这可以减少信息损失?
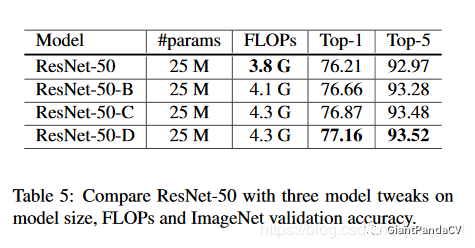
最终关于这些改进的网络结构的效果如Table5所示,可以看到效果提升还是有的。
3.3 模型训练调参
这部分作者提到了4个调参技巧:
-
学习率衰减策略采用cosine函数。这部分的实验结果可以看Figure3,其中Figure3 表示 cosine decay和 step decay的示意图,其中 step decay的定义可以看我这篇推文: 添卷积神经网络学习路线(五)| 卷积神经网络参数设置,提高泛化能力?。而cosine衰减的公式为:
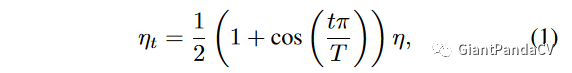
而Figure3(b)则表示2种学习率衰减策略在效果上的对比。
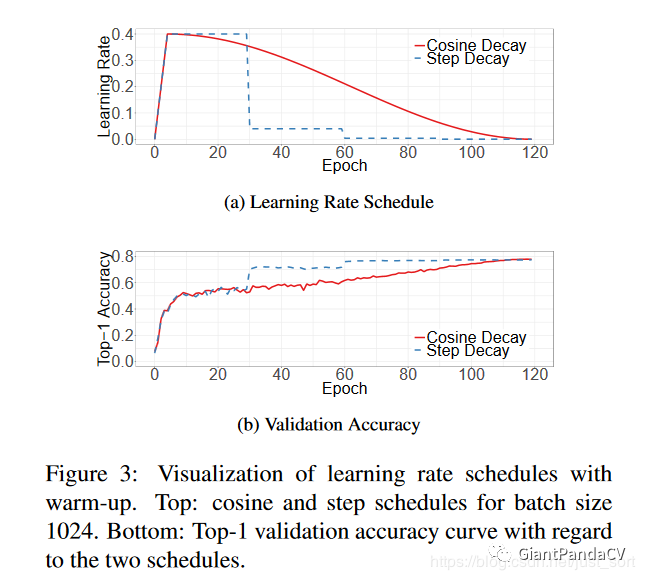
-
使用标签平滑(label smooth)。这部分是把原始的one-hot类型标签做软化,这样可以在计算损失时一定程度的减小过拟合。从交叉熵损失函数可以看出,只有真实标签对应的类别概率才会对损失值计算有所帮助,因此标签平滑相当于减少真实标签的类别概率在计算损失值时的权重,同时增加其他类别的预测概率在最终损失函数中的权重。 这样真实类别概率和其他类别的概率均值之间的gap(倍数)就会下降一些,Lable Smooth实际的公式如下:
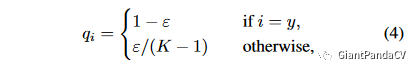
代码实现可以简单表示为:
new_labels = (1.0 - label_smoothing) * one_hot_labels + label_smoothing / num_classes
完整的Pytorch代码如下:
import torch
import torch.nn as nn
class LabelSmoothing(nn.Module):
"""
NLL loss with label smoothing.
"""
def __init__(self, smoothing=0.0):
"""
Constructor for the LabelSmoothing module.
:param smoothing: label smoothing factor
"""
super(LabelSmoothing, self).__init__()
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
def forward(self, x, target):
logprobs = torch.nn.functional.log_softmax(x, dim=-1)
nll_loss = -logprobs.gather(dim=-1, index=target.unsqueeze(1))
nll_loss = nll_loss.squeeze(1)
smooth_loss = -logprobs.mean(dim=-1)
loss = self.confidence * nll_loss + self.smoothing * smooth_loss
return loss.mean()
具体细节和公式可以再阅读原文,这里展示一下Lable Smooth的效果。
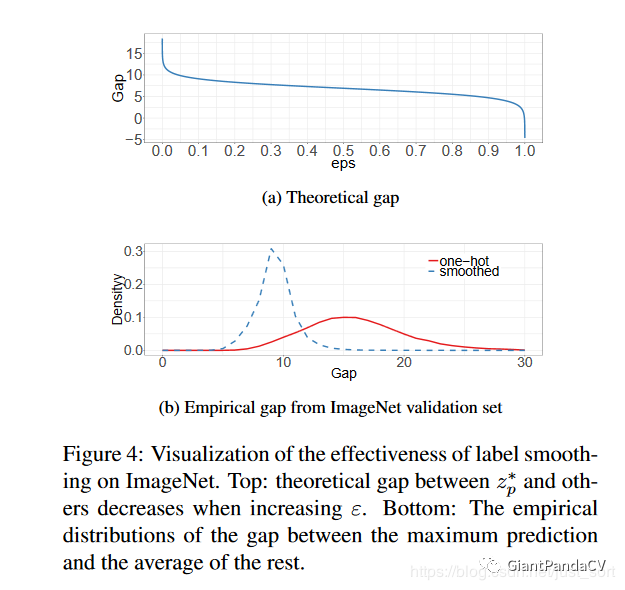
总结就一句话,one-hot编码会自驱的向正类和负类的差值扩大的方向学习(过度的信任标签为1的为正类),在训练数据不足的情况容易过拟合,所以使用Label Smooth来软化一下,使得没那么容易过拟合。
-
知识蒸馏(knowledge distillation)。知识蒸馏时模型压缩领域的一个重要分支,即采用一个效果更好的 teacher model训练 student model,使得 student model在模型结构不改变的情况下提升效果。这篇论文使用ResNet-152作为 teacher model,用ResNet-50作 student model。代码实现细节上,通过在ResNet网络后添加一个蒸馏损失函数实现,这个损失函数用来评价 teacher model输出和 student model输出的差异,因此整体的损失函数原损失函数和蒸馏损失函数的结合,如公式(6)所示:
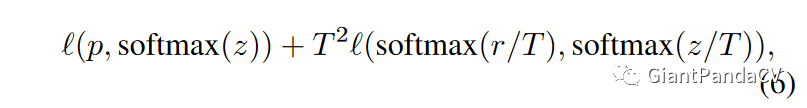
注意, 代表真实概率, 和 表示studnet model和techer model的最后一个全连接层的输出, 是超参数,用来平滑softmax函数的输出。
-
Mixup。论文还引入了Mixup这种数据增强方式,如果使用了Mixup数据增强来进行训练,那么每次需要读取2张输入图像,这里用 , 来表示,那么通过下面的公式就可以合成获得一张新的图像和标签 ,然后使用这张新图像和新标签进行训练,需要注意的是采用这种方式训练模型时要训更多 epoch。式子中的 是一个超参数,用来调节合成的比重,取值范围是 。
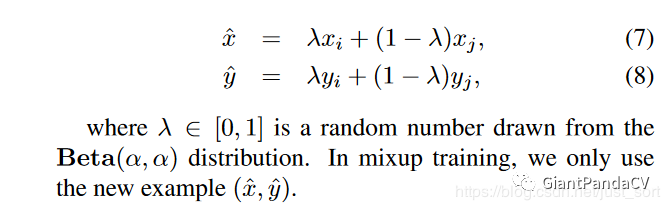
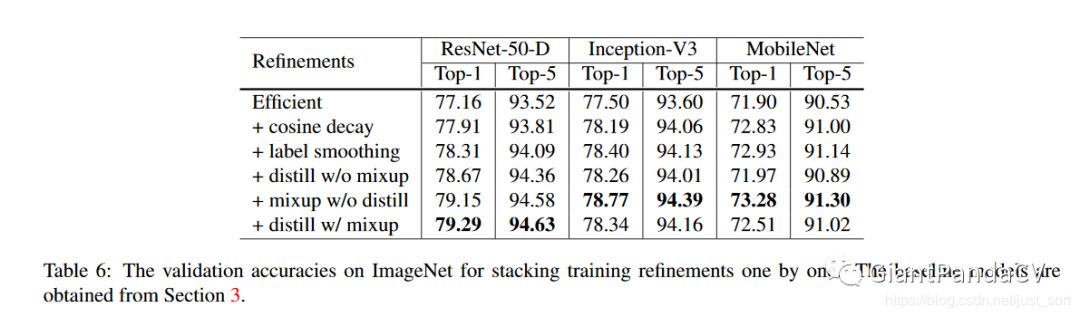
最终,在使用了这4个Tricks后的消融实验结果如Table6所示。
4. 迁移学习
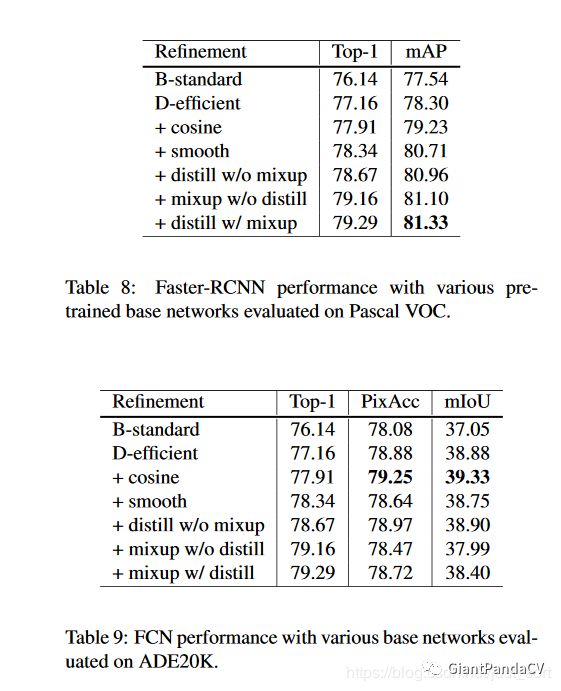
当把上面的Tricks迁移到目标检测和语义分割任务同样是有效的,实验结果如Table8和Table9所示。
5. 结论
总的来说,这篇论文给了我们非常多的炼丹技巧,我们可以将这些技巧放迁移到我们自己的数据集上获得效果提升,是非常实用的一篇论文了。
6. 参考
-
论文原文:https://arxiv.org/abs/1812.01187 -
https://blog.csdn.net/u014380165/article/details/85268719 -
https://blog.csdn.net/qq_33229912/article/details/100113850
推荐阅读
2020年AI算法岗求职群来了(含准备攻略、面试经验、内推和学习资料等)
重磅!CVer-学术微信交流群已成立
扫码添加CVer助手,可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、TensorFlow、PyTorch、图神经网络等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!


