本
文对华南理工大学和联想研究院共同完成,
被AAAI-20录用的
论文
《Decoupled Attention Network for Text Recognition》进行解读。
![]()
论文下载地址:https://arxiv.org/abs/1912.10205
伴随着深度学习的快速发展,近些年文本识别领域出现了许多新方法。注意力机制是当前文本识别最先进的方法之一,其在场景文本识别任务上取得了尤为出色的效果。
然而,当前注意力机制的对齐操作依赖于上一步的解码信息,这就导致了一旦上一步解码出错或具有迷惑性,注意力机制的对齐将产生错误,且此错误会累积传播。这一问题在较长的手写文本上体现得较为明显。
为了解决这种情况,本文提出了一种去耦注意力网络(DAN),该网络将注意力的对齐阶段从解码器中解耦出来,即进行对齐时不再依赖于上一步的解码信息。实验表明,DAN在有效缓解了注意力机制的对齐错误问题,并在手写和场景两种文本识别场景上取得了SOTA或相当的效果。
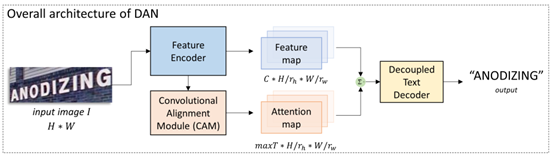
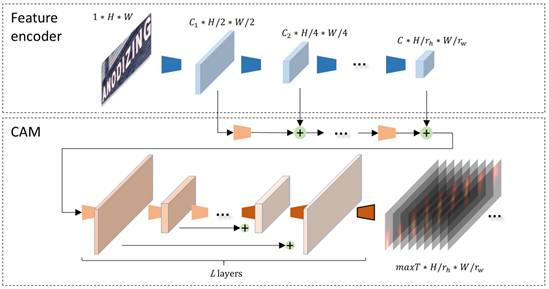
DAN由三个模块组成:特征提取器(FE)、卷积对齐模块(CAM)、去耦解码器(DTD)。FE对输入图片提取多个尺度的特征图;CAM接收特征提取器中的多尺度特征,采用全卷积结构,输出与特征图等尺寸的attention map;最后DTD解码出识别结果。
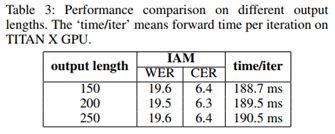
卷积对齐模块采用一个全卷积结构,由L层卷积组成。模块的输入融合了特征提取过程中各个尺度的特征,在反卷积阶段,每层特征会与卷积阶段相应特征进行加和。模块的输出是经过sigmoid函数激活后的maxT张attention map。之后每张attention map经过归一化。maxT是解码的最长时间步,即文本的最大字符数。在手写长文本识别任务中,maxT的值可以设置为150、200;在单词级别场景文本识别任务中,maxT的值可以设置为25。
通过改变FE和CAM中卷积操作的步长,DAN可以在一维和二维形式之间灵活切换,以应对不同的应用场景。FE输出特征图高度被压为1,即一维识别形式时,DAN适用于规则的手写长文本识别;在进行二维形式时,DAN适用于不规则的场景文本识别。在不同应用场景中,DAN灵活而高效,均取得了SOTA或相当的效果。
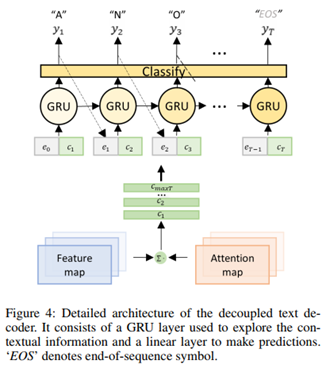
去耦解码器与其他注意力解码器运算过程相似,将高维特征图与attention map进行加权求和后,对每个字符依次进行解码。同时上一步的解码结果会经过embedding,参与当前步解码中,以加强语义学习。DAN的训练仅需要字符类别标注,不需要每个字符的位置信息。
1.脱机手写文本,在脱机手写文本识别任务中,本文选择了IAM和RIMES两个数据集进行实验。
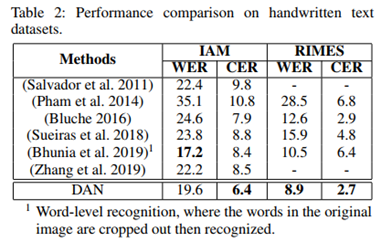
(1)结果对比。从Table2可以看到DAN在两个数据集上都效果出色。
(2)消融实验。本文对CAM模块设计进行了讨论,得到两个结论:1. CAM的层数应该足够深,才能达到较好的效果。2. 只要设置合理,输出通道数maxT的大小对识别结果几乎无影响。
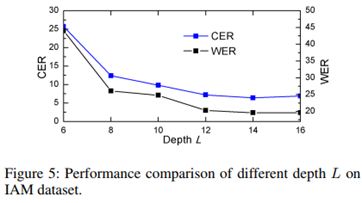
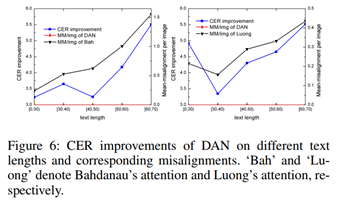
(3)对消除对齐错误的深入分析。本文选择了两种经典的attention结构:Bahdanau’s attention和Luong’s attention,在IAM数据集上进行了进一步对齐效果分析。从Figure 6可以看出,DAN有效缓解了长文本上的对齐问题。
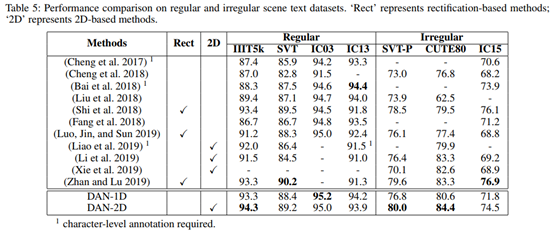
2.场景文本识别,在该任务中,本文采用规则/不规则文本的七个数据集进行实验,在实验时使用了双向解码器。
结果对比如Table 5所示。可以看出,DAN在大部分数据集上取得了SOTA或相当的效果,同时,二维识别在不规则文本数据集上的识别效果明显好于一维识别。
本文提出了一种去耦注意力网络(DAN),用于解决注意力机制中由解码问题造成的对齐错误累积传播。DAN在手写文本识别和场景文本识别两种应用场景中均表现出了优越的效果。与之前的注意力机制识别方法相比,DAN更加灵活鲁棒。
另外,值得一提的是,论文作者所在的研究团队将本模型作为其中一个关键技术模块,与别的识别技术进行集成,参加了今年ICDAR街景中英文招牌场景文字识别(ICDAR 2019-ReCTS)国际比赛,并荣获了ICDAR 2019-ReCTS识别任务冠军。
https://arxiv.org/abs/1912.10205
https://github.com/Wang-Tianwei/Decoupled-attention-network
更多AAAI 2020信息,将在「AAAI 2020 交流群」中进行,加群方式:添加AI研习社顶会小助手(AIyanxishe2),备注「AAAI」,邀请入群。
![]()
AAAI 2020 论文解读系列:
13. [中科院自动化所] 通过解纠缠模型探测语义和语法的大脑表征机制
14. [中科院自动化所] 多模态基准指导的生成式多模态自动文摘
15. [南京大学] 利用多头注意力机制生成多样性翻译
16. [UCSB 王威廉组] 零样本学习,来扩充知识图谱(视频解读)
17. [上海交大] 基于图像查询的视频检索,代码已开源!
18. [奥卢大学] 基于 NAS 的 GCN 网络设计(视频解读)
19. [中科大] 智能教育系统中的神经认知诊断,从数据中学习交互函数
20. [北京大学] 图卷积中的多阶段自监督学习算法
21. [清华大学] 全新模型,对话生成更流畅、更具个性化(视频解读,附PPT)
![]()
![]()
![]()
![]() 点击“阅读原文” 前往 AAAI 2020 专题页
点击“阅读原文” 前往 AAAI 2020 专题页