蘑菇街推荐算法之迷——Self Attention不如Traditional Attention?
作者 | 诗品算法
楔子
说好要经常更新,一定要坚持下来!前段时间在蘑菇街首页推荐视频流场景测试deep模型结构时,发现self attention的效果居然不如简单的traditional attention!问题出在哪里?
注意力机制
作为一种资源分配方案,将计算资源分配给最重要的任务。注意力是人类与生俱来不可或缺的认知功能。我们在日常生活中,会通过嗅觉、触觉、听觉、视觉感受到来自四面八方不同信息的鱼贯涌入,而我们却能在如此繁杂的信息轰炸中,区分主次,并挑选出最重要的信息进行加工处理,同时忽略其他不重要的信息。这种能力就是注意力。比如,查理.芒格可以做到专注地读书而不受到任何外界环境的干扰。这就是具有极强专注力的体现,相信多数读者在工作或阅读中也有此种体会。
self-attention回顾
在开始实践之前,有必要先简要回顾一下火遍宇宙的self-attention。下面是我迄今为止看到的最易懂的描述,参考邱锡鹏老师的《神经网络与深度学习》 。我会结合推荐系统的场景对其进行叙述。用 




注意力分布
为了从输入向量(历史序列) 
给定一个Query vector: 





其中, 
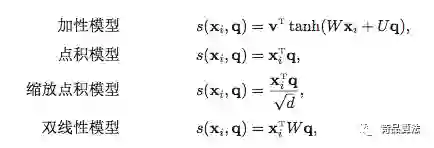
其中, 


但是,若输入向量的维度 


加权平均
注意力分布

由此可见,选择的信息是所有输入向量在注意力分布下的期望。
Attention
熟悉的图,熟悉的公式,熟悉的attention。当我们的打分函数为缩放点积模型时,attention如下:

公式与Google论文里一致。其中, 







self-attention
对于self-attention来讲, 
traditional attention

与self-attention相比,这个公式就简单多了。输入
推荐场景self attention/traditional attention实践
我们的输入序列是用户在蘑菇街首页的实时点击序列,按照点击发生时间进行排序,序列从左至右,对应着点击时间由近及远。我们使用wide & deep结构进行模型训练。target是待排视频id。target和用户侧序列分别经过self attention/traditional attention层,我们通过加减乘等操作将两侧的表达进行信息融合,最后再通过两层dense全连接,得到最终的概率值。
参数共享,指的是target目标与用户侧序列attention结构的trainable参数共享。
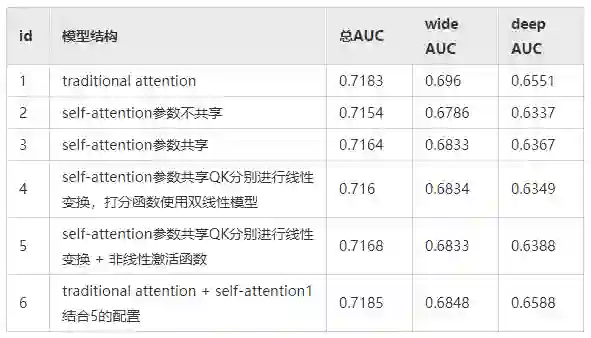
总结:
1、参数是否共享
2 VS 3,相比于两侧参数不共享的结构,共享时,整体AUC提升千分之一,deep侧AUC提升千分之三,且大大加速了训练过程。
2、改变打分函数(Q和K的融合方式)
我们的self_attention结构采用经典的QKV方式,QK的计算方式使用缩放点积模型。我们将缩放点积模型改成双线性模型,即分别对Q和K进行线性变换后,再计算点积。
3 VS 4,QK分别线性变换,整体AUC无差异,deep侧AUC下降千分之二。3 VS 5,QK分别线性变换 + 非线性激活,整体AUC表现无差,deep侧AUC提升千分之二。
3、traditional attention + self attention
将两种不同的attention结构进行merge,对两个结构的输出rep进行concat。1:traditional attention;5:self attention;9:1+5
merge 与 traditional attention的总体AUC无差异,deep AUC涨千分之三。
这是否说明,traditional attention学到的信息比self attention更多呢?
traditional attention不会使序列内部进行两两交叉,但是self attention会通过 
至于真正的核心原因,我并没有idea。大家可以留言讨论。
这让人想起了奥卡姆剃刀原则:“如无必要,勿增实体”。有时候,模型并不是越复杂越好,“在其他一切同等的情况下,较简单的解释普遍比较复杂的好“。所以,当你堆叠了无数高大上的复杂网络结构,但离线AUC和线上指标却一直上不去时,是不是可以考虑从特征、样本甚至产品改进等层面入手呢?
参考:
1、邱锡鹏:《神经网络与深度学习》
2、attention is all you need论文:https://arxiv.org/pdf/1706.03762.pdf
推荐阅读





