

https://nowpublishers.com/article/Details/INR-076
匹配在搜索和推荐中都是一个关键问题,它是衡量文档与查询的相关性或用户对某个条目的兴趣。机器学习已经被用来解决这个问题,它根据输入表示和标记数据学习匹配函数,也被称为“学习匹配”。近年来,人们努力开发用于匹配搜索和推荐任务的深度学习技术。随着大量数据的可用性、强大的计算资源和先进的深度学习技术,用于匹配的深度学习现在已经成为最先进的搜索和推荐技术。深度学习方法成功的关键在于它在从数据(例如查询、文档、用户、条目和上下文,特别是原始形式)中学习表示和匹配模式的泛化方面的强大能力。
本文系统全面地介绍了最近发展起来的搜索推荐深度匹配模型。首先给出了搜索和推荐匹配的统一观点。这样,两个领域的解决方案就可以在一个框架下进行比较。然后,调查将目前的深度学习解决方案分为两类:表示学习方法和匹配函数学习方法。介绍了搜索中的查询-文档匹配和推荐中的用户-项匹配的基本问题和最新的解决方案。该调查旨在帮助搜索和推荐社区的研究人员深入了解和洞察空间,激发更多的想法和讨论,促进新技术的发展。
匹配并不局限于搜索和推荐。在释义、问题回答、图像注释和许多其他应用程序中都可以发现类似的问题。一般而言,调查中引入的技术可以概括为一个更一般的任务,即匹配来自两个空间的物体。
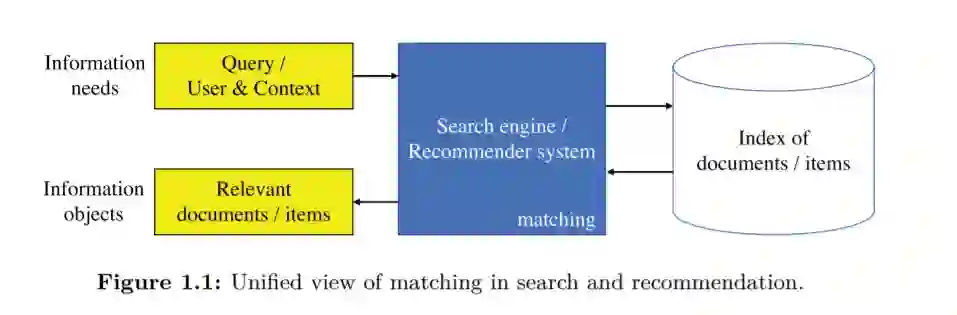
图1.1:搜索和推荐匹配的统一视图。

-
输入层接收两个匹配对象,它们可以是单词嵌入、ID向量或特征向量。
-
表示层将输入向量转换为分布式表示。这里可以使用MLP、CNN和RNN等神经网络,这取决于输入的类型和性质。
-
交互层比较匹配对象(例如,两个分布式表示)并输出大量(局部或全局)匹配信号。矩阵和张量可以用来存储信号及其位置。
-
聚合层将各个匹配信号聚合成一个高级匹配向量。该层通常采用深度神经网络中的pooling和catenation等操作。
-
输出层获取高级匹配向量并输出匹配分数。可以利用线性模型、MLP、神经张量网络(NTN)或其他神经网络。


