学界 | MSRA王井东详解ICCV 2017入选论文:通用卷积神经网络交错组卷积
机器之心报道
参与:高静宜
7 月 17 日,微软亚洲研究院的一篇论文,《Interleaved Group Convolutions for Deep Neural Networks》入选计算机视觉领域顶级会议 ICCV 2017(International Conference on Computer Vision)。论文中提出了一种全新的通用卷积神经网络交错组卷积(Interleaved Group Convolution,简称 IGC)模块,解决了神经网络基本卷积单元中的冗余问题,可以在无损性能的前提下,缩减模型、提升计算速度,有助于深度网络在移动端的部署。微软亚洲研究院视觉计算组王井东研究员向机器之心详细解读了这篇论文中的研究工作。

近年来,卷积神经网络凭借其强大的性能优势,在计算机视觉、自然语言处理等领域的应用得到了业界广泛的认可,并引发了一场研究热潮。目前,神经网络领域的研究基本上可以概括为两个方向,一是探索在测试数据集上如何有更好的表现,二是关注在实际应用中存在的难点。从实际的角度出发,由于深度神经网络受到大量矩阵运算的限制,往往需要海量存储及计算资源。削减神经网络中卷积单元的冗余是解决这个问题的重要研究之一,并分为空间(spatial)及通道(channel)两个方向。而微软亚洲研究院这篇论文的研究就从通道的角度出发,设计了一种全新的卷积冗余消除策略。
据王井东研究员介绍,这项研究的设计思路是来自于微软亚洲研究院去年提出的深度融合(Deep Fusion [1])概念,其本质是将不同分支的网络在中间层进行融合。他们在进一步研究中发现,一个标准的卷积也可以采用类似的多分支结构 [2],由此展开深入研究,研究出了较为简单的交错组卷积模块,即 IGC 模块。
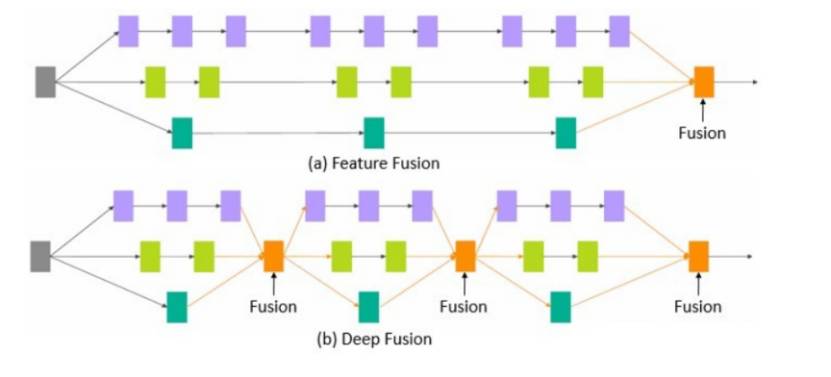
深度融合简单形式概念示意图
每个交错组卷积模块包括两个组卷积(group convolution)过程——第一次组卷积(primary group convolution)以及第二次组卷积(secondary group convolution)。组卷积曾被用于 AlexNet 中,将模型分布在两个 GPU 上以解决内存处理问题。用一个 32 通道的例子来解释一下组卷积:把 32 个输入通道平均分为 4 组,每组拥有 8 个通道,并分别对 4 组单独做卷积运算。这样的好处是参数较少可以提升计算速度,但是同时,由于每组卷积之间不存在交互,不同组的输出通道与输入通道并不相关。为了让输入通道与每一个输入通道实现关联,交错组卷积过程巧妙地引入了第二次组卷积,即第二次组卷积过程中,每组的输入通道均来自于第一次组卷积过程不同的组,达到交错互补的目的。
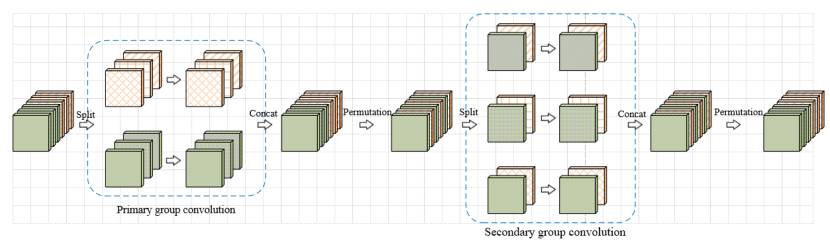
交错组卷积过程
从消除卷积核冗余的角度看,一个组卷积等价于具有稀疏核的普通卷积,而交错组卷积,即两次组卷积则等价于两个稀疏核相乘的普通卷积。这两个稀疏矩阵相乘可以得到两两相关的稠密矩阵,是一个线性的过程。在网络模型大小及计算复杂度相同的条件下,相较于普通卷积,使用 IGC 模块的网络更宽,性能更优。
王井东研究员提到,研究刚开始的时候,他们并没有发现在通道上的相关工作,直到去年十月份,他们才看到领域内的一些研究成果 [3, 4],例如 channel-wise convolution,包括谷歌的 Xception(Extreme Inception)。事实上,Xception 模块可以看作交错组卷积的一个特例。如果第一次组卷积过程中,每组只有一个输出通道,那么就变成了特殊的组卷积,即 channel-wise convolution,第二次组卷积成为 1X1 的卷积,这与 Xception 相似;如果第一次组卷积过程里仅有一组,那么这个过程就变成了普通卷积,第二次组卷积过程则相当于分配给每个通过一个不同的权重。那么问题来了,极端情况下是否能带来最佳结果?研究团队也针对这个问题进行了探讨,并设计了相关实验,结果发现并不是这样。
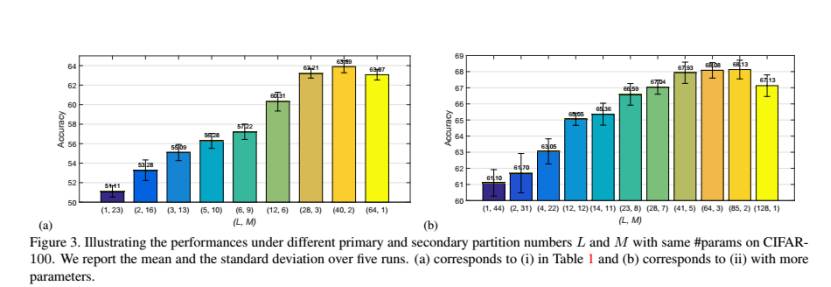

通过实验结果可以发现,网络的性能会随着通道数及组数的变化而变化,最优性能配置点存在于两个极端情况之间。精确度会随着第一次组卷积分成的组数的增加(第二次组卷积分成的组数的减少)而提升,达到极值后开始降低。
除此之外,论文中的实验部分还根据 CIFAR-10、CIFAR-100、SVHN 标准数据测试集,针对参数数目、计算复杂度及分类精确度性能衡量指标,将包含普通卷积模块、和融合模块及 IGC 模块的五种网络进行了比较,结果如下:


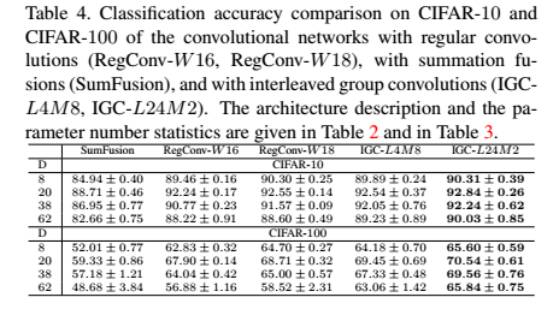
可以看出,由于 IGC 模块增加了网络的宽度,其性能具有明显优势。例如,在 CIFAR-100 测试集上,当网络层数为 38 时,IGC-L4M8 和 IGC-L24M2 可以达到 67.33% 和 69.56% 的分类精确度,分别比 RegConv-W18 的效果高 2.3% 和 4.5%。而由于融合算法降低了网络宽度,导致参数并没有被充分利用,因此效果明显不佳。
网络宽度对性能起到了至关重要的作用,不过目前,如何平衡神经网络的深度与宽度这一问题在业内还没有定论。对此,王井东研究员发表了自己的见解。一方面,深度神经网络在存在一些优势的同时也会带来梯度消失等问题,ResNet 等优化算法也应运而生;另一方面,在解决落地问题时,非常深的网络结构的实际意义往往并没有想象中那么大,例如,在达到一定层次时,再增加网络的深度只会增加计算的复杂度却并没有带来相应的效果提升。「神经网络宽度的作用在本质上与核方法相似,就是把本来不能线性可分的部分变得线性可分。虽然现阶段在理论上还没有解决深度与宽度的权衡问题,不过利用有效的方法增加网络的宽度是非常值得探索的一个方向。」
另外,该研究团队在 ImageNet 上与 ResNet-18 进行了比较,在分类错误率方面存在优势。「我们的实验主要是想表达 IGC 模块与标准的卷积比较会带来什么样的好处,而不是在标准数据集上将其他所有算法刷下去。」王井东研究员解释道。
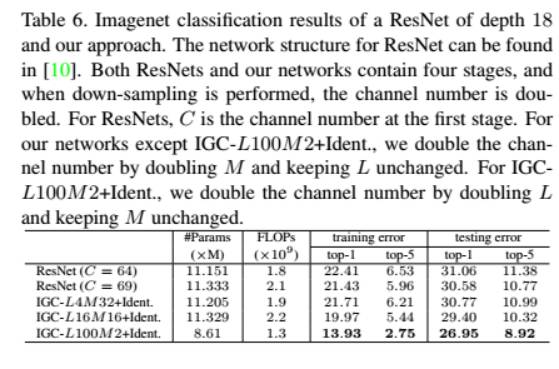
在与其他世界前领先算法进行比较的过程中,IGC 在 CIFAR-10 数据集上表现最为出色,在 SVHN 上精确度可以达到第三(第一跟第二则是该研究团队另外一篇论文 [5] 所提出的算法的结果)。王井东研究员表示,如果采用 bottleneck 层,他们的结果在 CIFAR-100 上表现会更好一些。
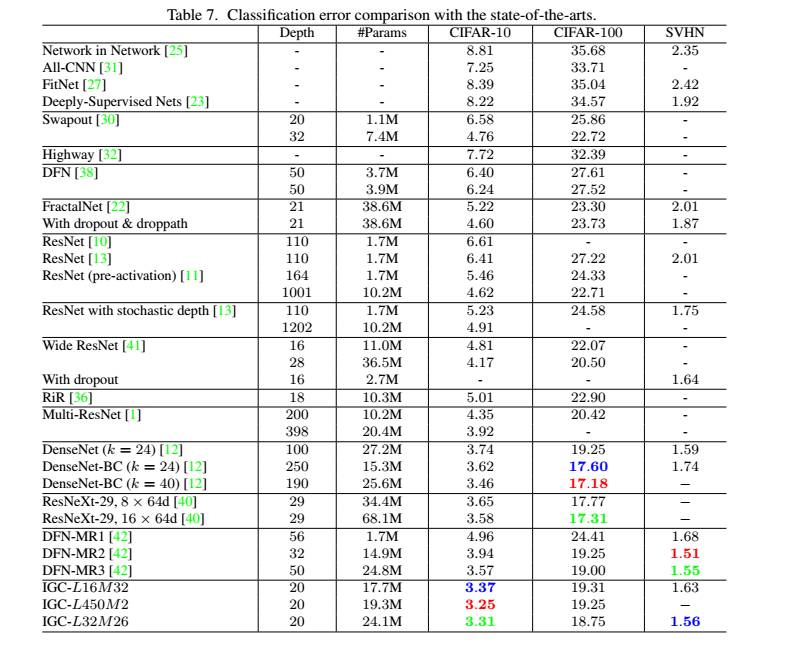
补充材料中,团队还设计了一个 Group-and-Point-wise Convolution(GPC)(类似于 deep roots [3]) 模块,通过实验与同样基于通道的 deep roots 算法进行了比较。Deep roots 本质上相当于一个组卷积加上一个 1X1 的卷积,某种意义上讲,Xception 也是 deep roots 的一个特例。结果显示,交错组卷积表现更好。
王井东研究员表示,解决冗余还有很多其他的角度,比如二值化网络等。IGC 模块可以与这些还存在上升空间的算法实现互补,进一步降低神经网络的冗余,在不失精度的情况下,实现缩减网络模型、降低计算量的目的。「非常有趣的是,在组卷积中,每组都在进行普通的卷积,这里也可以继续使用交错组卷积。在我们的交错组卷积模块中,未来也许会有第三次、第四次组卷积,这也是我们未来对这个算法进行改进的方向之一。」
自去年八月份产生这个想法后,微软亚洲研究院研究团队于九月开始着手推进这个项目。在经历了大约半年的时间后,团队在今年三月份正式向 ICCV 2017 提交论文及研究成果。在这期间,团队也曾在探索过程中遇到阻碍和瓶颈,走过一些弯路。据王井东研究员介绍,在受到深度融合的启发之后,团队把研究重点放在了沿着深度融合的思路推广普通卷积,开始尝试让组卷积(secondary group convolution)共享参数。不过,由于团队发现这个方式的效果提升并不明显,所以最终选择了不共享参数的研究道路。除此之外,由于现在很多平台并没有对组卷积有很好的支持,所以团队在实现方面也曾遇到了一些问题,并在实践层次做了相关工作,也寄希望于 cuDNN 将来有更好的支持。
深度学习技术的突破给计算机视觉领域带来了较大的冲击。「许多做计算机视觉的研究人员之前是很难想象到今天这个领域会得到如此多的关注。」王井东研究员表示,虽然深度学习的优越性在计算机视觉领域有所表现,但是距离很多算法落地还有很长的一段路要走。「做研究的人可以多从实际应用出发,让算法在产品中发挥价值,这也是我们的初心。」
[1] Jingdong Wang, Zhen Wei, Ting Zhang, Wenjun Zeng: Deeply-Fused Nets. CoRR abs/1605.07716 (2016).
[2] Ting Zhang, Guo-Jun Qi, Bin Xiao, Jingdong Wang: Interleaved Group Convolutions for Deep Neural Networks. CoRR abs/1707.02725 (2017).
[3] Yani Ioannou, Duncan P. Robertson, Roberto Cipolla, Antonio Criminisi: Deep Roots: Improving CNN Efficiency with Hierarchical Filter Groups. CoRR abs/1605.06489 (2016).
[4] François Chollet: Xception: Deep Learning with Depthwise Separable Convolutions. CoRR abs/1610.02357 (2016).
[5] Liming Zhao, Jingdong Wang, Xi Li, Zhuowen Tu, Wenjun Zeng: On the Connection of Deep Fusion to Ensembling. CoRR abs/1611.07718 (2016).

本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




