Caffeine 和 Redis 居然可以这么搭,想不到吧!



前言

为什么要用多级缓存?
如果只使用redis来做缓存我们会有大量的请求到redis,但是每次请求的数据都是一样的,假如这一部分数据就放在应用服务器本地,那么就省去了请求redis的网络开销,请求速度就会快很多。但是使用redis横向扩展很方便。
如果只使用Caffeine来做本地缓存,我们的应用服务器的内存是有限,并且单独为了缓存去扩展应用服务器是非常不划算。所以,只使用本地缓存也是有很大局限性的。
1、缓存的选择
-
一级缓存:Caffeine是一个一个高性能的 Java 缓存库;使用 Window TinyLfu 回收策略,提供了一个近乎最佳的命中率。 -
二级缓存:redis是一高性能、高可用的key-value数据库,支持多种数据类型,支持集群,和应用服务器分开部署易于横向扩展。
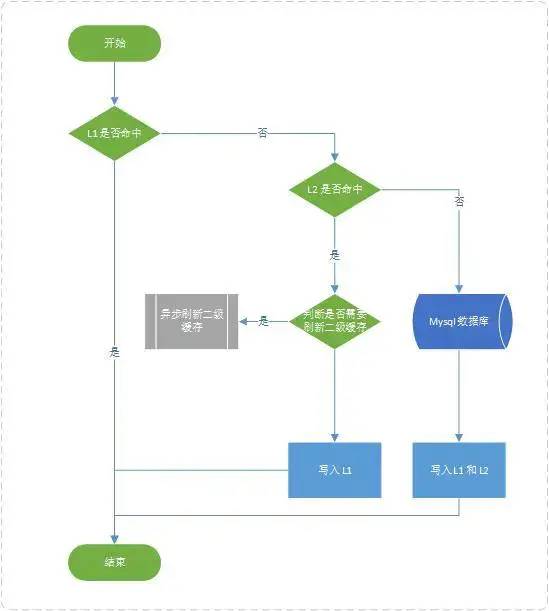
2、数据流向
数据读取流程
数据删除流程
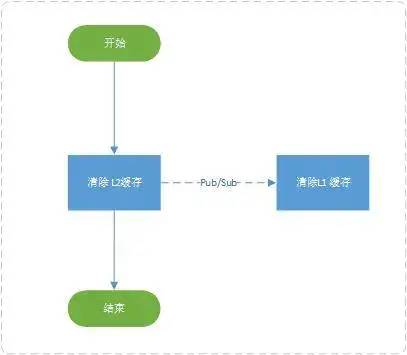
解决思路

实战多级缓存的用法
1、项目说明
我们在项目中使用了两级缓存
本地缓存的时间为60秒,过期后则从redis中取数据,
如果redis中不存在,则从数据库获取数据,
-
从数据库得到数据后,要写入到redis
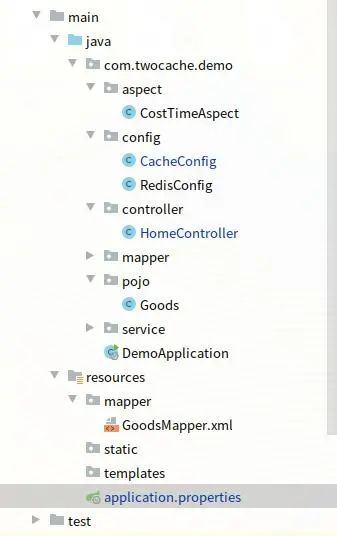
2、项目结构
3、配置文件说明
application.properties
#redis1spring.redis1.host=127.0.0.1spring.redis1.port=6379spring.redis1.password=lhddemospring.redis1.database=0spring.redis1.lettuce.pool.max-active=32spring.redis1.lettuce.pool.max-wait=300spring.redis1.lettuce.pool.max-idle=16spring.redis1.lettuce.pool.min-idle=8spring.redis1.enabled=1#profilespring.profiles.active=cacheenable
CREATE TABLE `goods` (`goodsId` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',`goodsName` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT 'name',`subject` varchar(200) NOT NULL DEFAULT '' COMMENT '标题',`price` decimal(15,2) NOT NULL DEFAULT '0.00' COMMENT '价格',`stock` int(11) NOT NULL DEFAULT '0' COMMENT 'stock',PRIMARY KEY (`goodsId`)) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='商品表'
4、Java代码说明
CacheConfig.java
("cacheenable") //prod这个profile时缓存才生效//开启缓存public class CacheConfig {public static final int DEFAULT_MAXSIZE = 10000;public static final int DEFAULT_TTL = 600;private SimpleCacheManager cacheManager = new SimpleCacheManager();//定义cache名称、超时时长(秒)、最大容量public enum CacheEnum{goods(60,1000), //有效期60秒 , 最大容量1000homePage(7200,1000), //有效期2个小时 , 最大容量1000;CacheEnum(int ttl, int maxSize) {this.ttl = ttl;this.maxSize = maxSize;}private int maxSize=DEFAULT_MAXSIZE; //最大數量private int ttl=DEFAULT_TTL; //过期时间(秒)public int getMaxSize() {return maxSize;}public int getTtl() {return ttl;}}//创建基于Caffeine的Cache Managerpublic CacheManager caffeineCacheManager() {ArrayList<CaffeineCache> caches = new ArrayList<CaffeineCache>();for(CacheEnum c : CacheEnum.values()){caches.add(new CaffeineCache(c.name(),Caffeine.newBuilder().recordStats().expireAfterWrite(c.getTtl(), TimeUnit.SECONDS).maximumSize(c.getMaxSize()).build()));}cacheManager.setCaches(caches);return cacheManager;}public CacheManager getCacheManager() {return cacheManager;}}
RedisConfig.java
public class RedisConfig {public LettuceConnectionFactory redis1LettuceConnectionFactory(RedisStandaloneConfiguration redis1RedisConfig,GenericObjectPoolConfig redis1PoolConfig) {LettuceClientConfiguration clientConfig =LettucePoolingClientConfiguration.builder().commandTimeout(Duration.ofMillis(100)).poolConfig(redis1PoolConfig).build();return new LettuceConnectionFactory(redis1RedisConfig, clientConfig);}public RedisTemplate<String, String> redis1Template(LettuceConnectionFactory redis1LettuceConnectionFactory) {RedisTemplate<String, String> redisTemplate = new RedisTemplate<>();//使用Jackson2JsonRedisSerializer来序列化和反序列化redis的value值redisTemplate.setKeySerializer(new StringRedisSerializer());redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());//使用StringRedisSerializer来序列化和反序列化redis的key值redisTemplate.setHashKeySerializer(new StringRedisSerializer());redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());//开启事务redisTemplate.setEnableTransactionSupport(true);redisTemplate.setConnectionFactory(redis1LettuceConnectionFactory);redisTemplate.afterPropertiesSet();return redisTemplate;}public static class Redis1Config {private String host;private Integer port;private String password;private Integer database;private Integer maxActive;private Integer maxIdle;private Long maxWait;private Integer minIdle;public GenericObjectPoolConfig redis1PoolConfig() {GenericObjectPoolConfig config = new GenericObjectPoolConfig();config.setMaxTotal(maxActive);config.setMaxIdle(maxIdle);config.setMinIdle(minIdle);config.setMaxWaitMillis(maxWait);return config;}public RedisStandaloneConfiguration redis1RedisConfig() {RedisStandaloneConfiguration config = new RedisStandaloneConfiguration();config.setHostName(host);config.setPassword(RedisPassword.of(password));config.setPort(port);config.setDatabase(database);return config;}}}
HomeController.java
//商品详情 参数:商品idpublic Goods goodsInfo( Long goodsId) {Goods goods = goodsService.getOneGoodsById(goodsId);return goods;}
GoodsServiceImpl.java
public Goods getOneGoodsById(Long goodsId) {Goods goodsOne;if (redis1enabled == 1) {System.out.println("get data from redis");Object goodsr = redis1Template.opsForValue().get("goods_"+String.valueOf(goodsId));if (goodsr == null) {System.out.println("get data from mysql");goodsOne = goodsMapper.selectOneGoods(goodsId);if (goodsOne == null) {redis1Template.opsForValue().set("goods_"+String.valueOf(goodsId),"-1",600, TimeUnit.SECONDS);} else {redis1Template.opsForValue().set("goods_"+String.valueOf(goodsId),goodsOne,600, TimeUnit.SECONDS);}} else {if (goodsr.equals("-1")) {goodsOne = null;} else {goodsOne = (Goods)goodsr;}}} else {goodsOne = goodsMapper.selectOneGoods(goodsId);}return goodsOne;}
5、测试效果
http://127.0.0.1:8080/home/goodsget?goodsid=3get data from redisget data from mysqlcosttime aop 方法doafterreturning:毫秒数:395
costtime aop 方法doafterreturning:毫秒数:0get data from rediscosttime aop 方法doafterreturning:毫秒数:8

总结

福 利
CSDN旗下公众号全新搜索技能上线啦!
只要在公众号内回复消息
就能自动回复想搜索的内容啦!
现在体验有惊喜,每日参与搜索打卡,
连续打卡满3天、7天、14天
均有CSDN精美礼品相送 百分百有礼!快戳


更多精彩推荐
☞开源数据库再创里程碑,PingCAP 获 2.7 亿美元融资
☞全球数百万台 Mac 疑似因 Big Sur 更新险酿计算灾难,苹果官方回应来了! ☞ JavaScript 稳居第一、C# 连续下跌,调查 17000 名程序员后有了这些新发现! ☞ 中国第一代程序员潘爱民的 30 年程序人生
☞ 漫画:什么是 “千年虫” 问题? ☞ 万万没想到 Java 中最重要的关键字竟然是这个!
![]()
点分享
![]()
点点赞
![]()
点在看



登录查看更多
相关内容

Arxiv
0+阅读 · 2021年1月27日
Arxiv
0+阅读 · 2021年1月27日
Arxiv
0+阅读 · 2021年1月27日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年1月27日
Arxiv
0+阅读 · 2021年1月27日
Arxiv
0+阅读 · 2021年1月27日