©作者 | 小舟
来源 | 机器之心
本文中,来自清华大学、AWS AI 和北京智源人工智能研究院的研究者提出了一种新型可变形自注意力模块,其中以数据相关的方式选择自注意力中键值对的位置,使得自注意力模块能够专注于相关区域,并捕获更多信息特征。
Transformer 近来在各种视觉任务上表现出卓越的性能,感受野赋予 Transformer 比 CNN 更强的表征能力。然而,简单地扩大感受野会引起一些问题。一方面,使用密集注意力(例如 ViT)会导致过多的内存和计算成本,并且特征可能会受到超出兴趣区域的无关部分的影响;另一方面,PVT 或 Swin Transformer 中采用的稀疏注意力与数据无关,可能会限制对远程(long range)关系建模的能力。
为了缓解这些问题,清华大学、AWS AI 和北京智源人工智能研究院的研究者提出了一种新型可变形自注意力模块,其中以数据相关的方式选择自注意力中键值对的位置。这种灵活的方案使自注意力模块能够专注于相关区域并捕获更多信息特征。
在此基础上,该研究提出了可变形注意力 Transformer(Deformable Attention Transformer,DAT),一种具有可变形注意力的通用主干网络模型,适用于图像分类和密集预测任务。该研究通过大量基准测试实验证明了该模型的性能提升。
![]()
https://arxiv.org/abs/2201.00520
现有的分层视觉 Transformer,特别是 PVT 和 Swin Transformer 试图解决过多注意力的挑战。前者的下采样技术会导致严重的信息损失,而后者的 Swin 注意力导致感受野的增长要慢得多,这限制了对大型物体进行建模的潜力。因此,需要依赖于数据的稀疏注意力来灵活地对相关特征进行建模,从而导致首先在 DCN [9] 中提出可变形机制。
然而,在 Transformer 模型中实现 DCN 是一个不简单的问题。在 DCN 中,特征图上的每个元素单独学习其偏移量,其中 H ×W ×C 特征图上的 3 × 3 可变形卷积具有 9 HWC 的空间复杂度。如果在注意力模块中直接应用相同的机制,空间复杂度将急剧上升到 N_qN_kC,其中 N_q、N_k 是查询和键的数量,通常与特征图大小 HW 具有相同的比例,带来近似于双二次的复杂度。
尽管 Deformable DETR [54] 已经设法通过在每个尺度上设置较少数量的 N_k = 4 的键来减少这种开销,并且可以很好地作为检测头,但由于不可接受的信息丢失(参见附录中的详细比较),在骨干网络中关注如此少的键效果不佳。与此同时,[3,52] 中的观察表明,不同的查询在视觉注意力模型中具有相似的注意力图。因此,该研究选择了一个更简单的解决方案,为每个查询共享移位键和值,以实现有效的权衡。
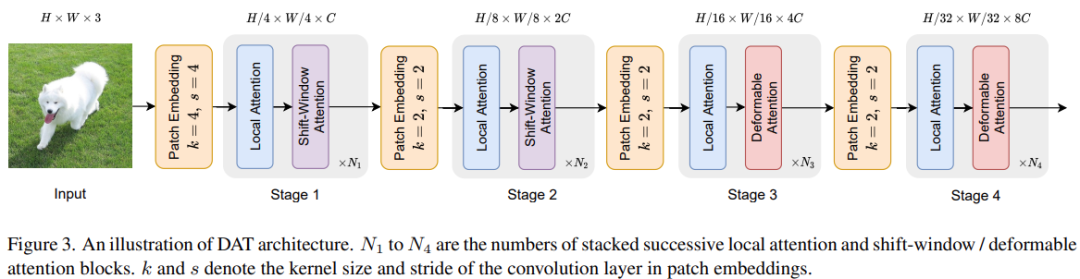
该研究在 Transformer(等式 (4))中的可变形注意力替换了 vanilla MHSA,并将其与 MLP(等式 (5))相结合,以构建一个可变形的视觉 transformer 块。在网络架构方面, DAT 与 [7, 26, 31, 36] 共享类似的金字塔结构,广泛适用于需要多尺度特征图的各种视觉任务。如下图 3 所示,形状为 H × W × 3 的输入图像首先被步长为 4 的 4 × 4 非重叠卷积嵌入,然后一个归一化层获得
![]() 补丁嵌入。
补丁嵌入。
![]()
为了构建分层特征金字塔,主干包括 4 个阶段,步幅逐渐增加。在两个连续的阶段之间,有一个步长为 2 的非重叠 2×2 卷积,对特征图进行下采样,将空间大小减半并将特征维度加倍。
在分类任务中,该研究首先对最后阶段输出的特征图进行归一化,然后采用具有池化特征的线性分类器来预测对数;在对象检测、实例分割和语义分割任务中,DAT 在集成视觉模型中扮演主干的角色,以提取多尺度特征。该研究为每个阶段的特征添加一个归一化层,然后将它们输入到以下模块中,例如对象检测中的 FPN [23] 或语义分割中的解码器。
该研究在 3 个数据集上进行了实验,以验证提出的 DAT 的有效性。该研究展示了在 ImageNet-1K [10] 分类、COCO 目标检测和 ADE20K 语义分割任务上的结果。此外,该研究提供了消融研究和可视化结果,以进一步展示该方法的有效性。
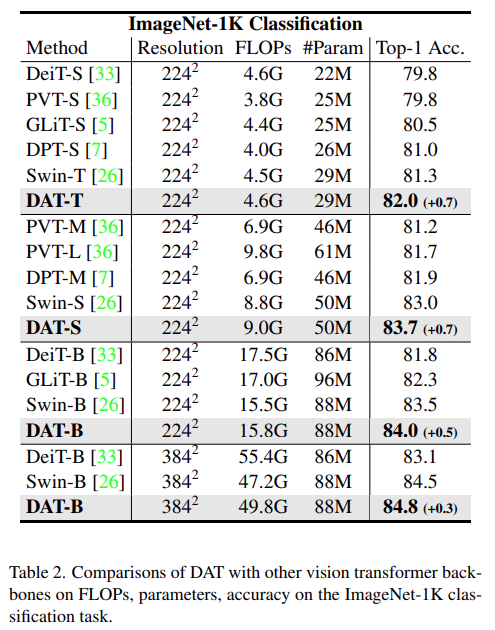
ImageNet-1K [10] 数据集有 128 万张用于训练的图像和 5 万张用于验证的图像。研究者在训练分割上训练 DAT 的三个变体,并报告验证分割上的 Top-1 准确度,并与其他 Vision Transformer 模型进行比较。
该研究在下表 2 中给出了有 300 个训练 epoch 的结果。与其他 SOTA 视觉 Transformer 模型相比, DAT 在具有相似计算复杂性的情况下在 Top-1 精度上实现了显著提高。DAT 在所有三个尺度上都优于 Swin Transformer [26]、PVT [36]、DPT [7] 和 DeiT [33]。没有在 Transformer 块 [13, 14, 35] 中插入卷积,或在补丁嵌入 [6, 11, 45] 中使用重叠卷积,DAT 比 Swin Transformer [26] 实现了 +0.7、+0.7 和 +0.5 的增益。在 384 × 384 分辨率下进行微调时,该模型继续比 Swin Transformer 性能好 0.3。
![]()
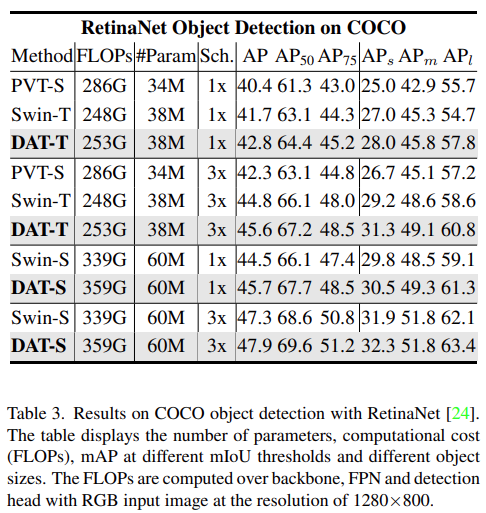
COCO 目标检测和实例分割数据集有 118K 的训练图像和 5K 的验证图像。该研究使用 DAT 作为 RetinaNet [24]、Mask R-CNN [17] 和 Cascade Mask R-CNN [2] 框架中的主干,以评估该方法的有效性。该研究在 ImageNet-1K 数据集上对该模型进行 300 个 epoch 的预训练,并遵循 Swin Transformer [26] 中类似的训练策略来公平地比较该方法。该研究在 1x 和 3x 训练计划中报告在 RetinaNet 模型上的 DAT。如下表 3 所示,在微型和小型模型中,DAT 的性能优于 Swin Transformer 1.1 和 1.2 mAP。
![]()
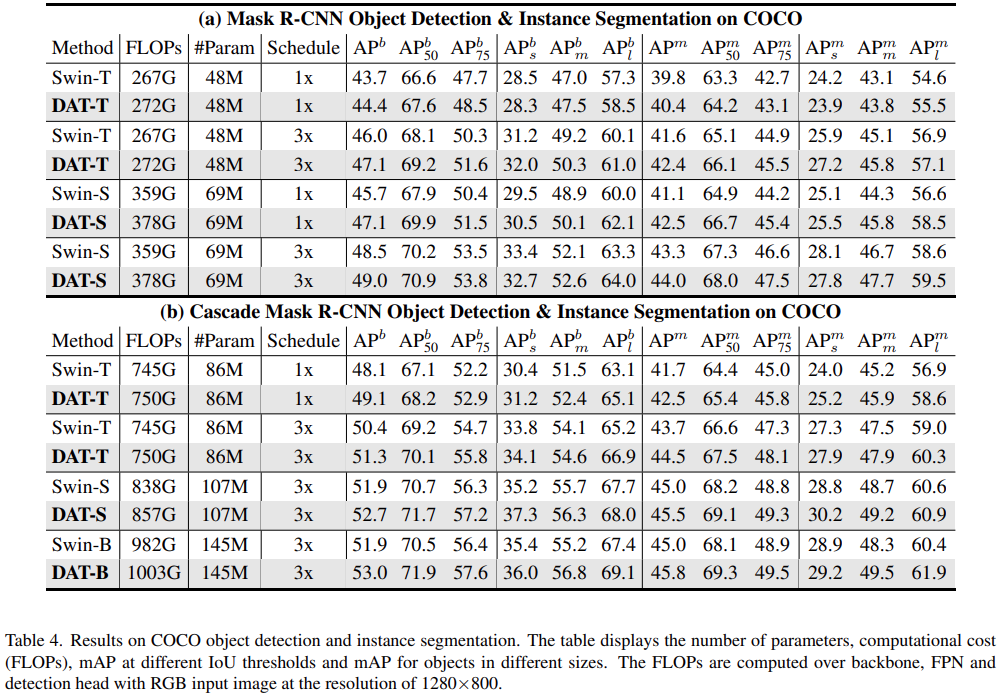
当在两阶段检测器(例如 Mask R-CNN、Cascade Mask R-CNN)中实现时,DAT 模型在不同尺寸的 Swin Transformer 模型上实现了一致的改进,如下表 4 所示。
![]()
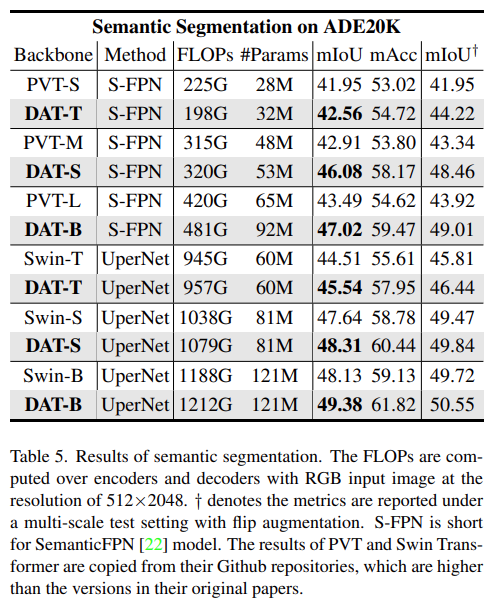
下表 5 给出了在验证集上各种方法的 mIoU 分数。
![]()
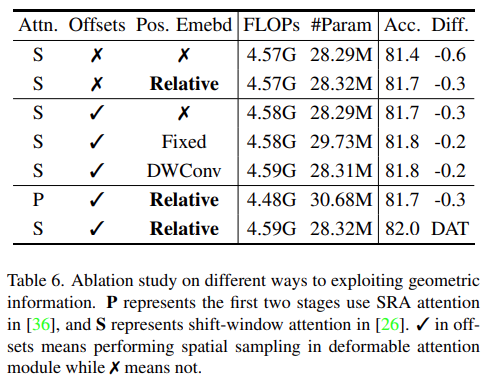
为了验证 DAT 模型中关键组件设计的有效性, 该研究进行了消融实验,报告了基于 DAT-T 的 ImageNet-1K 分类结果。对于几何信息开发,该研究首先评估了所提可变形偏移和可变形相对位置嵌入的有效性,如下表 6 所示。
![]()
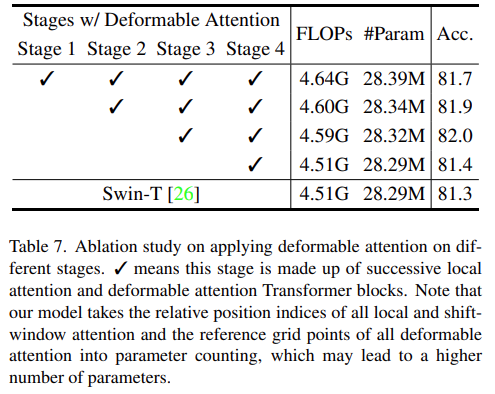
对于不同阶段的可变形注意力,该研究用不同阶段的可变形注意力替换了 Swin Transfomer [26] 的移位窗口注意力。如下表 7 所示,仅替换最后阶段的注意力提高了 0.1,替换最后两个阶段导致性能增益为 0.7(达到 82.0 的整体准确度)。然而,在早期阶段用更多可变形注意力替换会略微降低准确性。
![]()
该研究在 DAT 中可视化学习变形位置的示例,以验证该方法的有效性。如下图 4 所示,采样点描绘在对象检测框和实例分割掩码的顶部,从中可以看到这些点已转移到目标对象。
![]()
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()


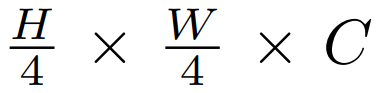 补丁嵌入。
补丁嵌入。