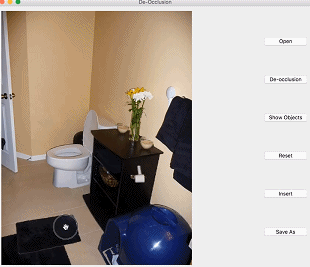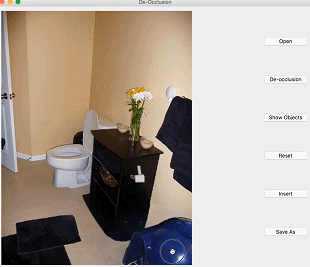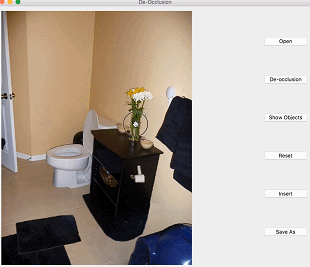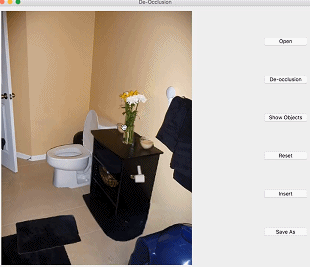
本文介绍的是CVPR2020 Oral论文《 Self-Supervised Scene De-occlusion 》,论文作者来自香港中文大学—商汤联合实验室与南洋理工大学,本文首发于知乎。
作者 | Xiaohang Zhan
编辑 | 丛 末
论文链接:https://arxiv.org/abs/2004.02788
代码:https://github.com/XiaohangZhan/deocclusion
自然场景理解是一项具有挑战性的任务,尤其是遇到图像中的物体互相遮挡的时候。现有的场景理解只能解析可见的部分。
在本文中,来自香港中文大学、商汤、南洋理工大学的研究者提出了一种自监督的场景去遮挡方法,旨在恢复潜在的遮挡顺序并补全被遮挡对象的不可见部分,其效果可媲美全监督的方法。
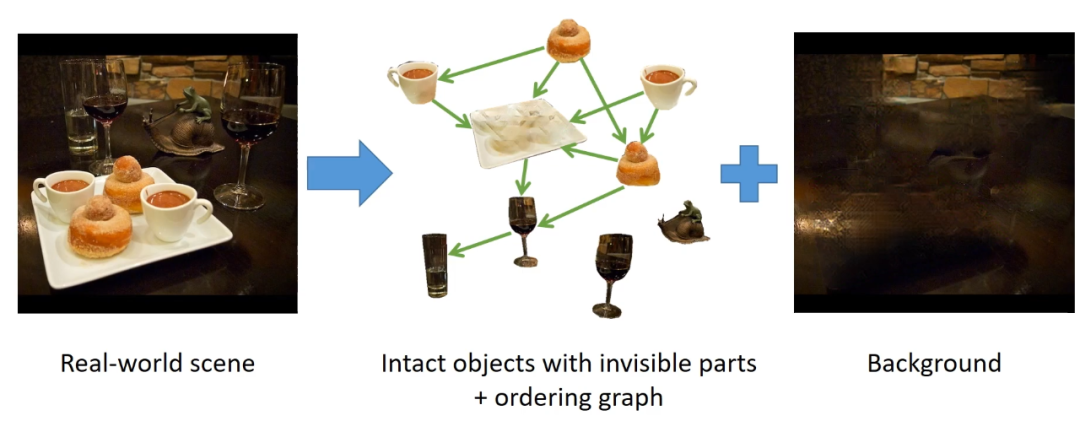
进入正题。先来看看研究者希望达到什么效果,如下图:
研究者希望将一张真实场景图片分解为完整的物体和背景,物体间根据遮挡关系组成一个有向图。他们将场景去遮挡这个问题分解为如下步骤:
-
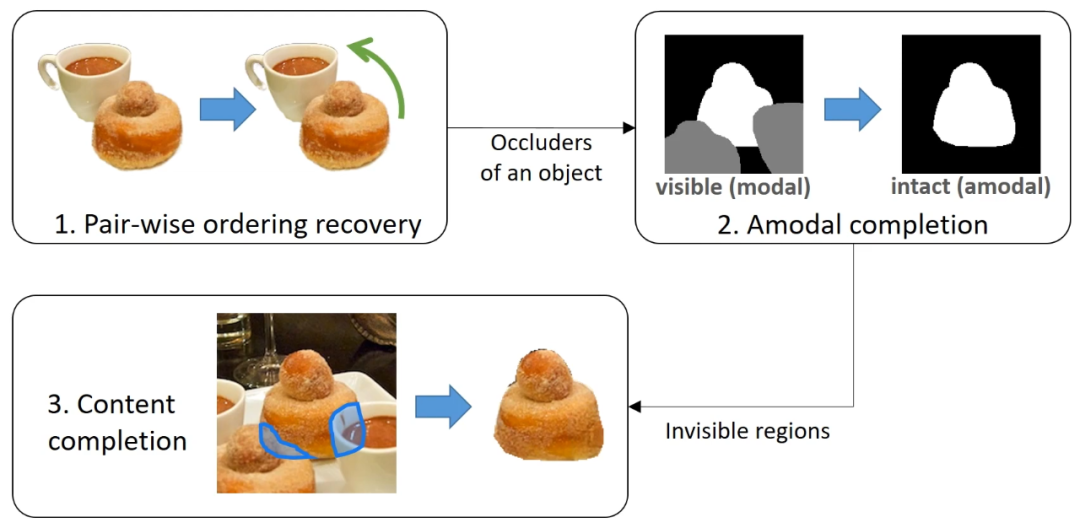
两两邻接的物体之间的顺序恢复。有了 pair-wise ordering 之后,就可以得到一个描述场景遮挡关系的有向图,称之为遮挡关系图(occlusion graph)。
-
Amodal completion。在遮挡关系图中,可以检索到任意一个物体被哪些物体遮挡了,这样就可以进行 amodal completion 步骤,把物体完整的 mask 恢复出来。
-
Content completion。有了 amodal mask 之后,就知道了物体的被遮挡区域(不可见部分),那么下一步就可以想办法在不可见部分填充 RGB 内容,使得这个物体完整的样子被恢复出来。
现有的数据包括 RGB 的图片、modal mask 和物体类别。modal mask 是指物体可见部分的 mask,其实就是一般意义的 instance segmentation 的 mask。这些其实正好构成了一个 instance segmentation 的数据集,例如 COCO、KITTI、LVIS 这些。注意,这样的数据集里并没有遮挡关系和 amodal mask 的标注,所以用有监督学习的思路是无法解决上述问题的。
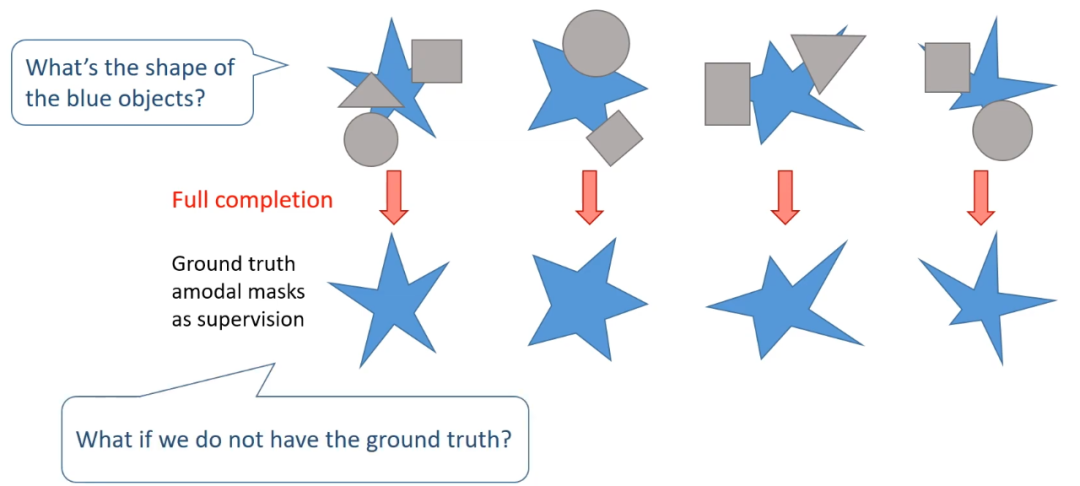
下面来介绍一个重要的概念,部分补全。在此之前,先来介绍完整补全。
如果有 amodal 标注,可以使用完整补全来训练和预测
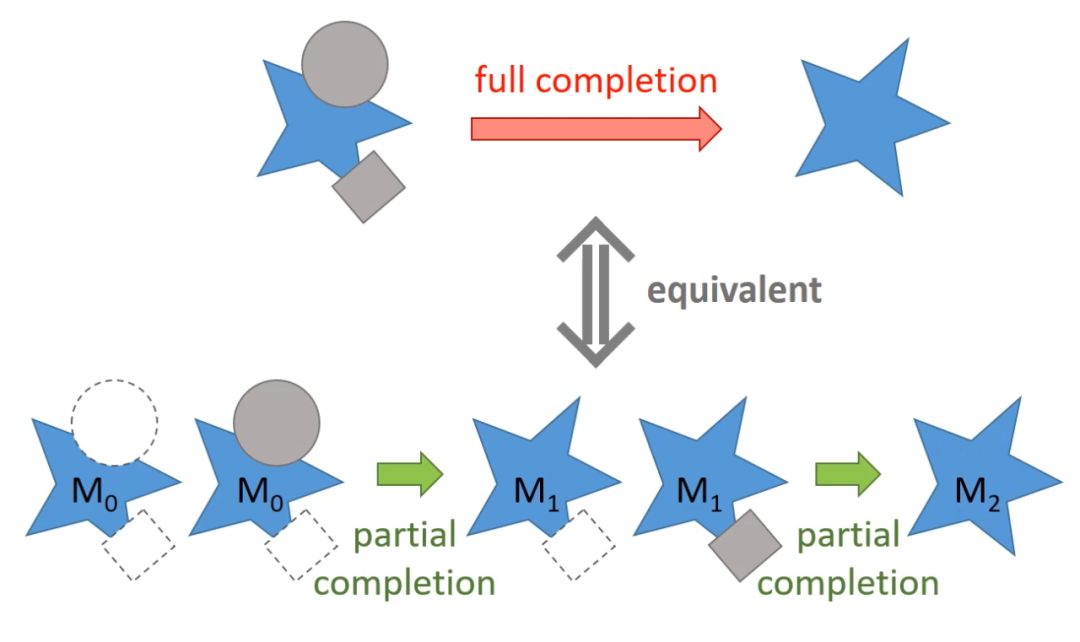
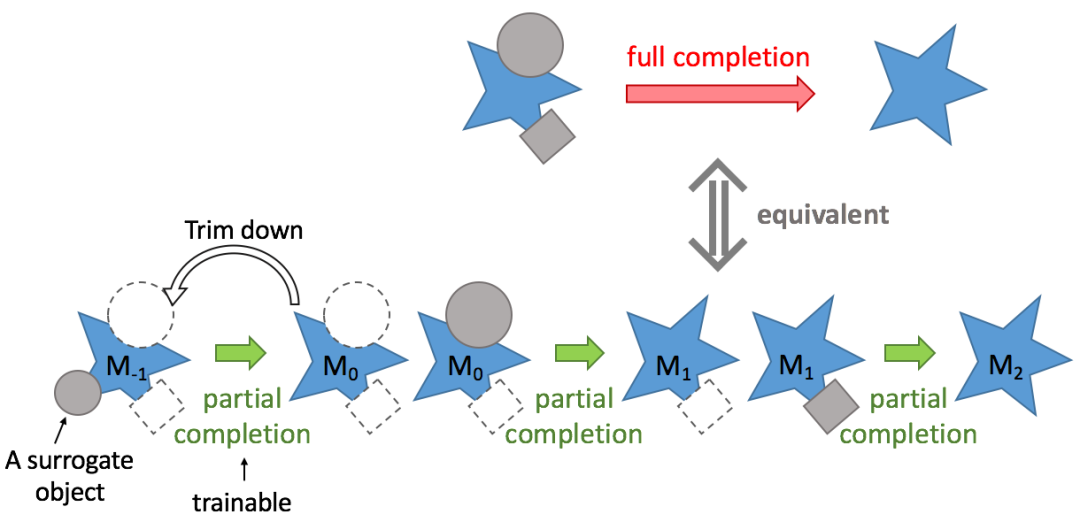
完整补全是指给定被遮挡的物体和它的遮挡物,一次性将物体完整的 amodal mask 补全,当然它的前提是需要有 ground truth amodal mask 作为监督。研究者发现一次完整补全等价于一系列的部分补全。
这里的部分补全(partial completion)是指:给定某一个遮挡物,只补全目标物体被当前遮挡物遮挡的部分。例如给定上图中的圆形遮挡物,把 M_0 补全为 M_1。然而,这些部分补全过程还是无法训练的,因为补全的中间状态(如 M_1)和最终状态(如 M_2)都是未知的。
接下来则是最关键的操作。如下图,将 M_0 再「切一刀」,即从数据集中随机选一个物体,用它的 modal mask 来盖住 M_0,得到 M_{-1},然后训练部分补全,从 M_{-1} 恢复 M_0。这个过程是可训练的。
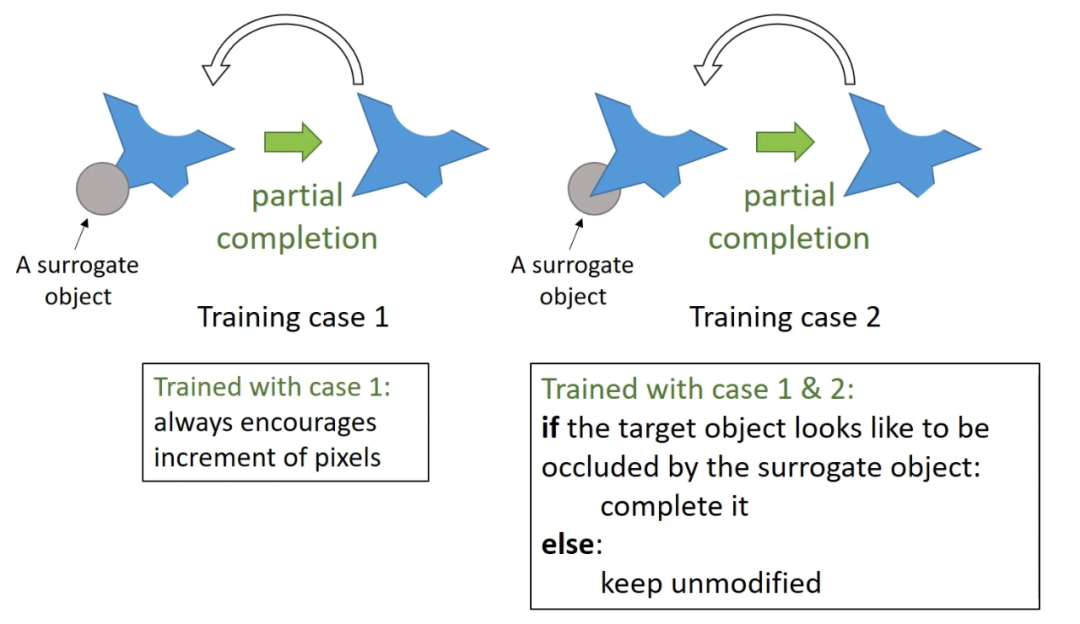
有了部分补全机制之后,为了方便后续的步骤,还需要引入一个正则机制,即下图 case 2。
Case 1 是之前介绍的用随机选择的 surrogate object 来遮挡住目标物体。用 case 1 来训练的部分补全会永远增加物体的面积。研究者又引入了 case 2,将 surrogate object 放在目标物体下面,然后要求在部分补全过程中保持目标物体不变。训练过程在 case 1 和 2 之间随机切换,那么网络在训练过程中需要从输入中挖掘信息来判断目标物体是否被 surrogate object 遮挡,只有在目标物体被遮挡的时候,它才会被部分地补全,否则就会保持不变。
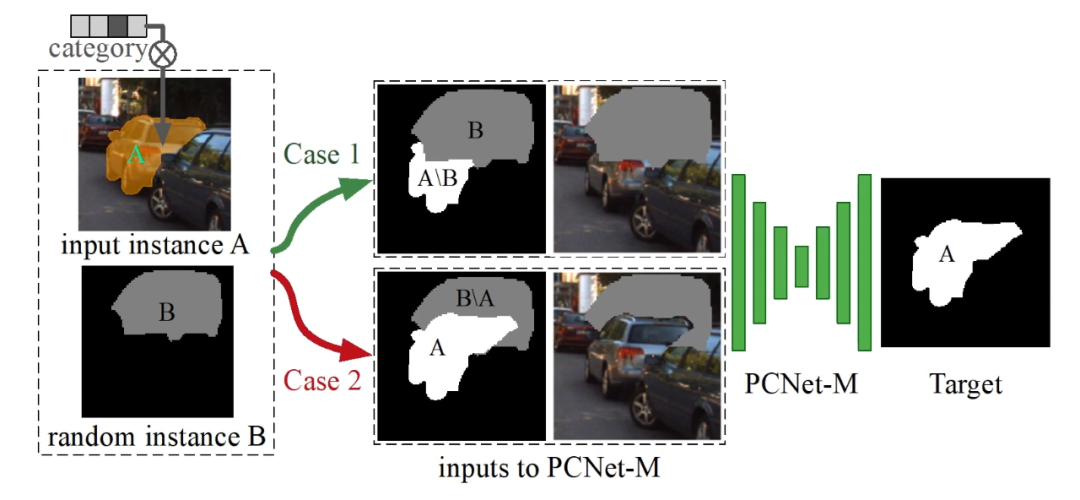
研究者用一个神经网络来模拟这个部分补全过程。部分补全网络(Partial Completion Network - Mask,简称 PCNet-M)的训练过程如下,其中 A 物体为目标物体,B 为 surrogate object,对于 case 1 和 2,PCNet-M 都需要恢复出 A 的初始 modal mask。
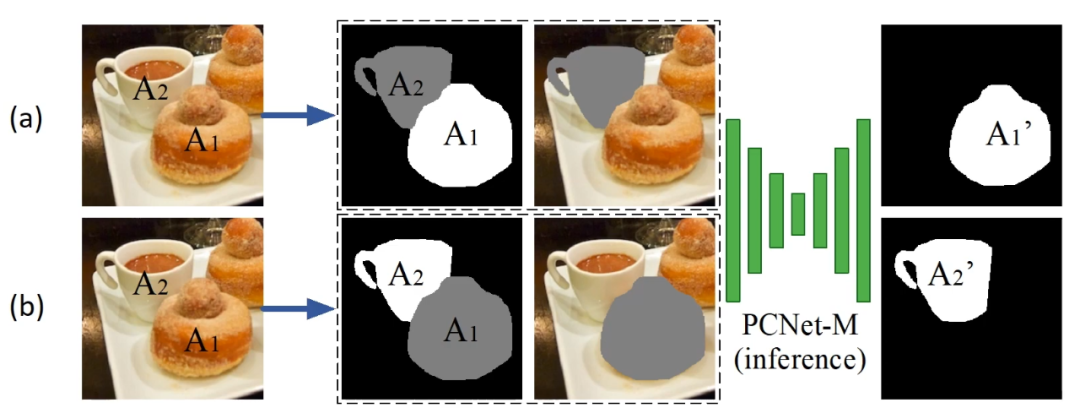
如下图,有了训练好的 PCNet-M 之后,他们设计了如下推理过程来恢复遮挡顺序。给定 A1 和 A2 两个邻接的物体,分别以 A1 为目标物体,A2 为 surrogate object,研究者发现 PCNet-M 并没有增加 A1 的面积;反过来,他们以 A2 为目标物体,A1 为 surrogate object,结果发现 A2 的面积增加了。由此可以判断出来,A1 遮挡了 A2。
Dual-completion for Ordering Recovery
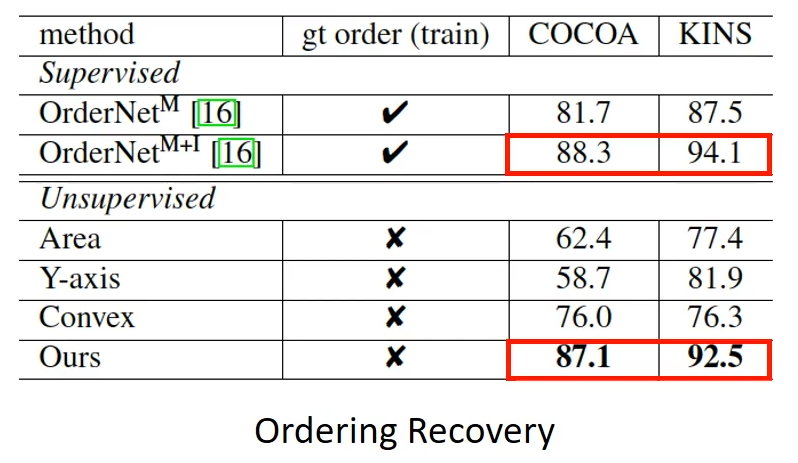
这个策略看似简单,实际上很巧妙地利用了正则化后的部分补全机制的选择性补全的特性,获得了很好的效果,在 COCOA 和 KINS 两个数据集上获得了和有监督方案非常接近的结果。
基于遮挡顺序的 Amodal Completion
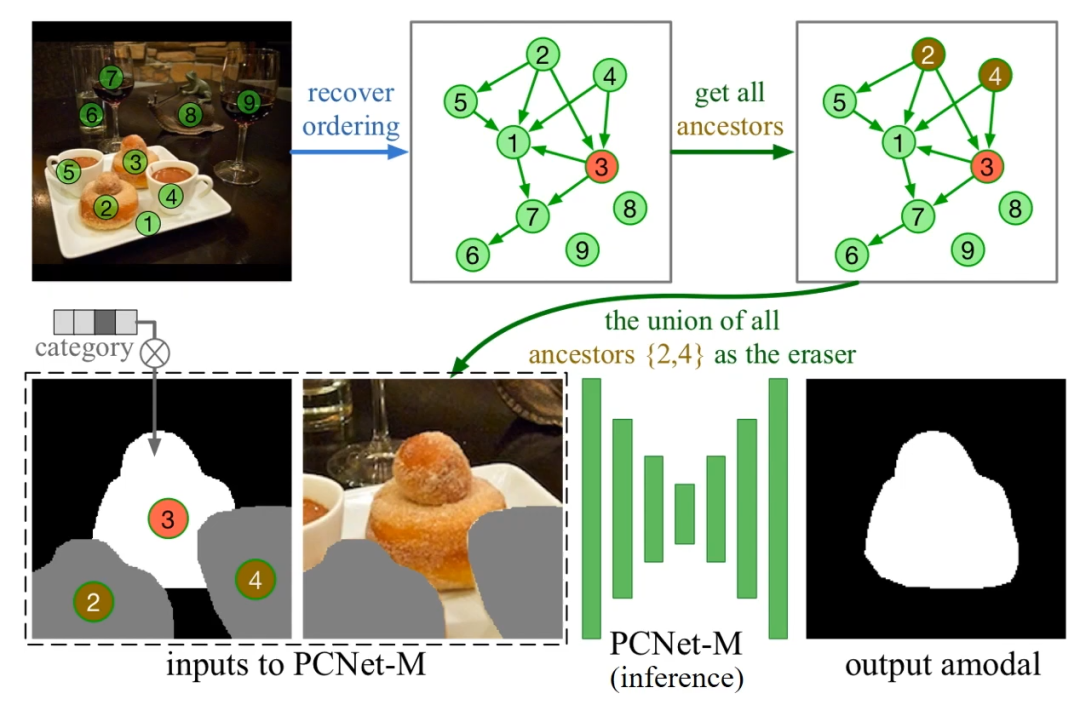
如下图,有了遮挡顺序之后,可以构建出一个遮挡顺序图。图中的边从遮挡物指向被遮挡物,这样一来,从图中对于任意一个物体,可以得到它的所有祖先节点,即为它的所有遮挡物。其中一阶祖先节点为直接遮挡物,高阶祖先节点为间接遮挡物。例如下图例子中可以得到,物体 3 有两个直接遮挡物,分别为 2 和 4。判断出遮挡物之后,就可以再次利用部分补全网络(PCNet-M)来恢复出 amodal mask。
基于遮挡顺序的 Amodal Completion 推理过程
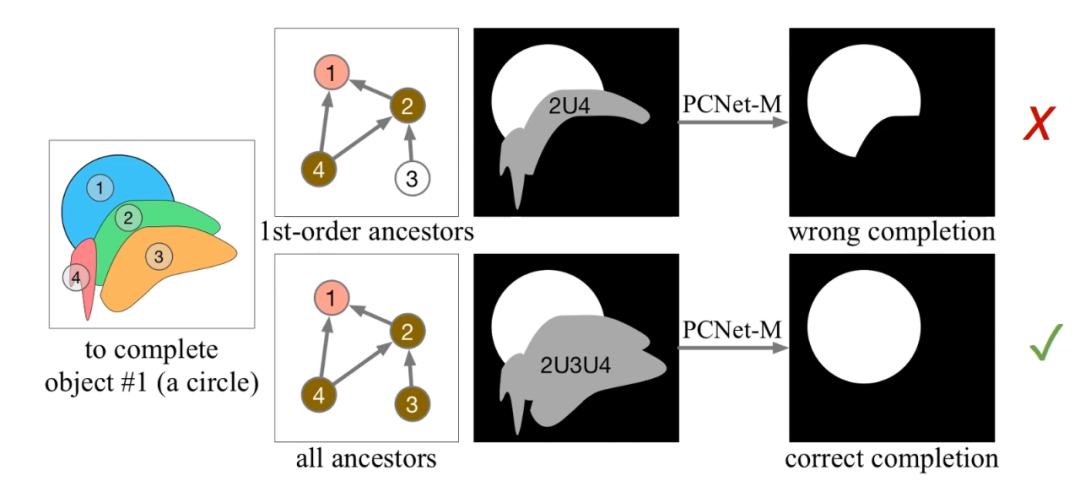
这里还需要解释一下为何要选取所有祖先节点作为遮挡物,而非仅仅直接遮挡的一阶祖先节点。如下图,这里需要补全物体 1。从遮挡关系图中,它的一阶祖先节点(即直接遮挡物)是 2 和 4,高阶祖先节点(间接遮挡物)是 3。研究者发现,只考虑一阶遮挡物,无法完整地补全物体 1 被物体 3 间接遮挡的部分。只有考虑所有祖先节点,才可以获得正确的补全结果。
使用一阶祖先节点和包括高阶祖先的所有祖先节点的对比。
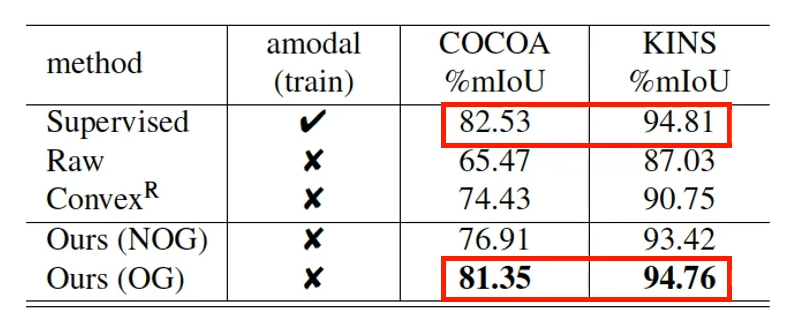
下面是 amodal completion 的结果。同样,本文提出的方法在 amodal completion 这个子任务上也达到了和有监督方案非常接近的结果。
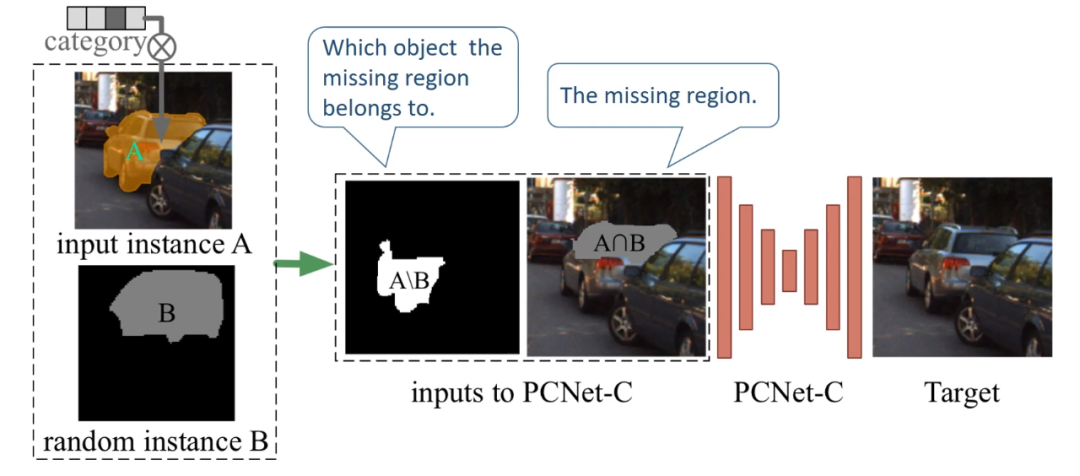
内容补全网络(Partial Completion Network - Content,缩写 PCNet-C)的训练方式和 PCNet-M 类似。同样地,此处无法在训练的时候用完整内容补全的结果来监督,研究者设计了如下的部分内容补全的训练策略。给定目标物体 A 和 surrogate object B,用 A∩B 来擦除图片的 RGB,作为缺失的需要填充的内容,然后用 A\B 来代表缺失的内容属于哪个物体。训练的目标是恢复原图。
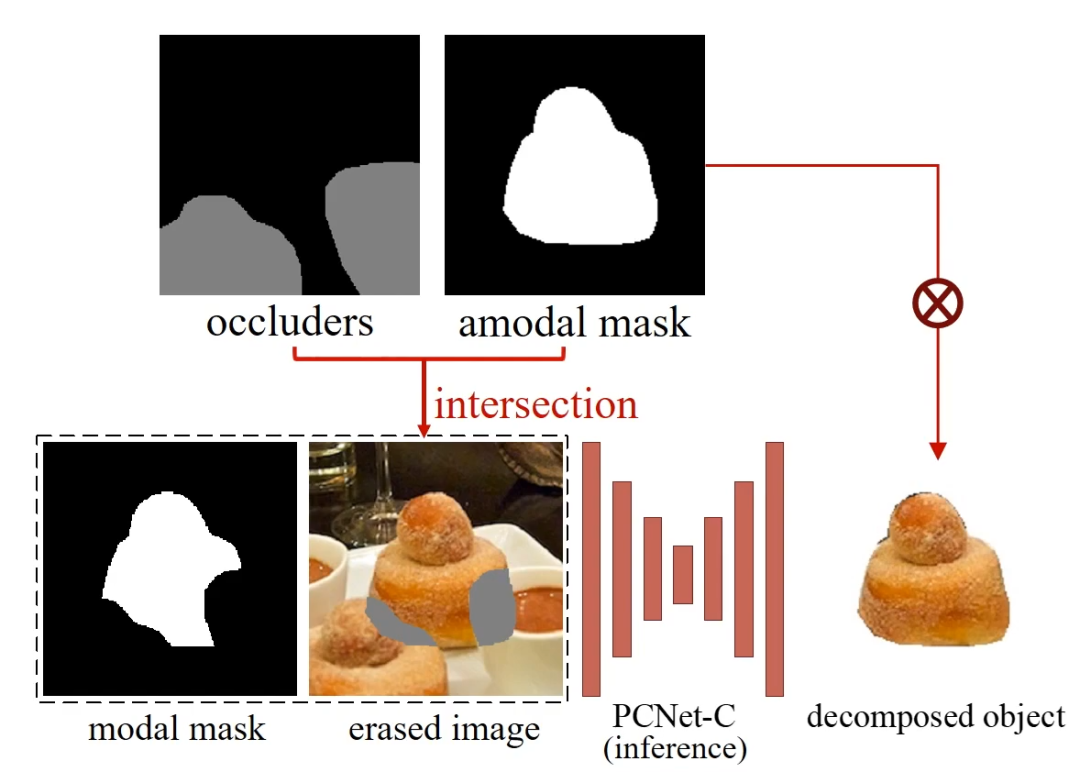
测试的时候,有了遮挡物(occluders)和目标物体的 amodal mask,取交集,就得到了需要填充内容的区域(即被遮挡的区域)。同时目标物体的 modal mask 也作为输入,用来表示缺失的区域属于该目标物体而非其他物体。最后 PCNet-C 将物体完整的样子补全了出来。
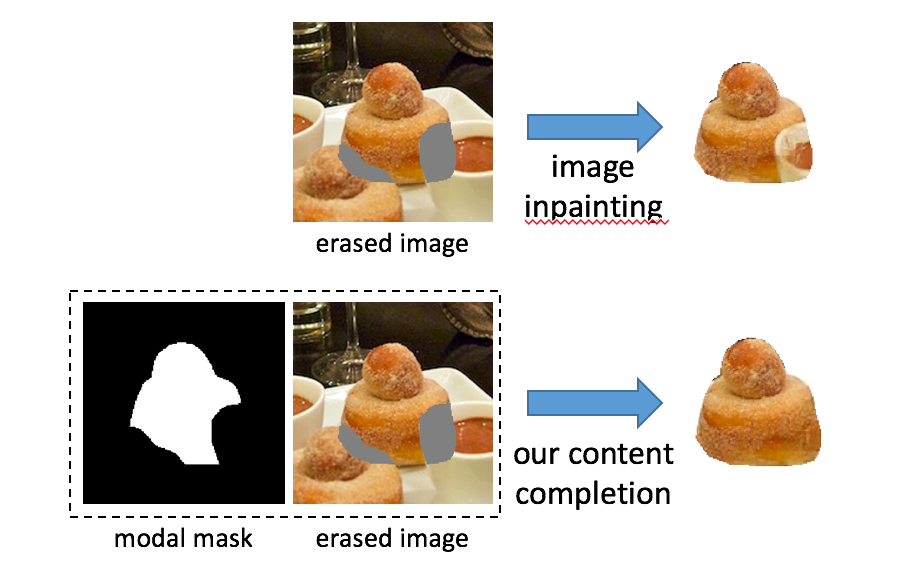
(说得这么花里胡哨,这不就是 image inpainting 吗?
如下图,关键的不同之处在于,image inpainting 没有 modal mask 这个输入,因为 image inpainting 并不 care 缺失的部分属于哪个物体,只要结果看起来合理就行。那么如果直接使用 image inpainting,缺失的区域就会被填充为其他物体的 RGB,例如下面的咖啡杯。这个结果对于 image inpainting 是非常合理的,但是对于物体的内容补全来说,则是不正确的。
当然 PCNet-C 的其他训练方式,包括网络结构、loss 等,都跟 image inpainting 大同小异。所以以后 image inpainting 做得更好了,也能帮助提升内容补全的效果。
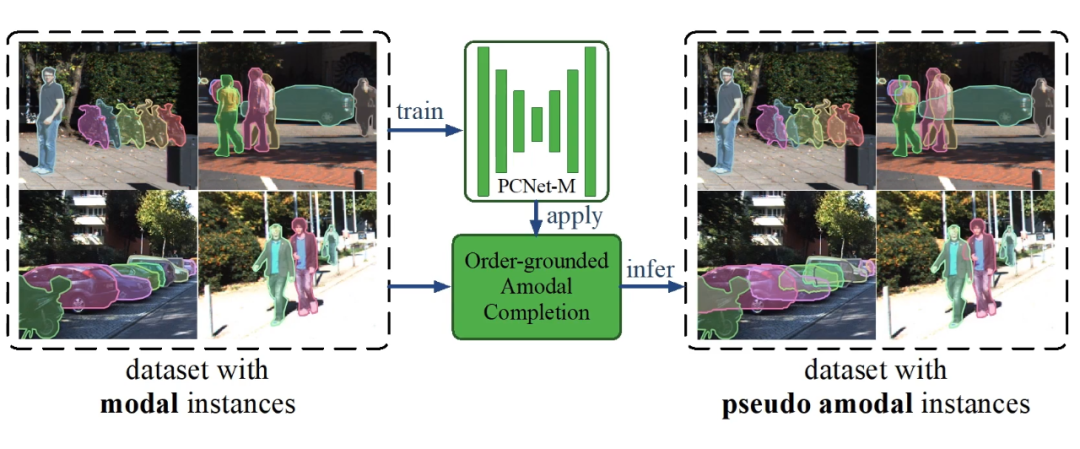
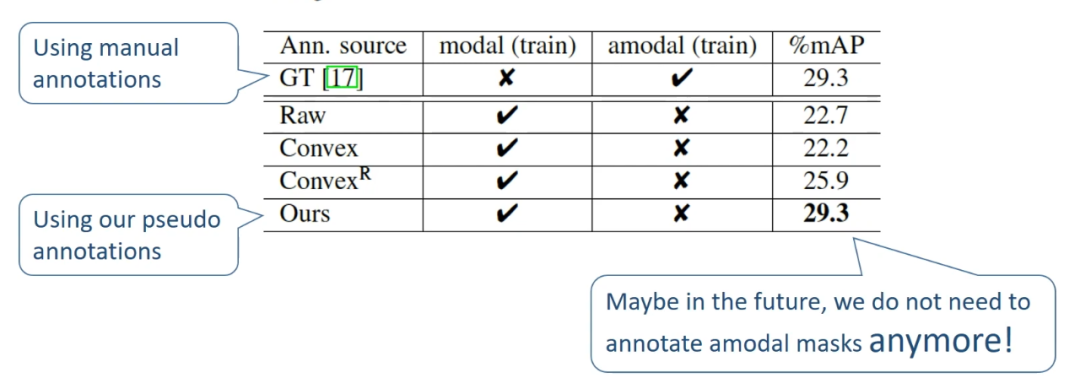
给一个普通的 instance segmentation dataset,例如下图中的 KITTI training set,研究者训练了 PCNet-M 并且仍旧在 training set 上应用 amodal completion 方法,就可以得到 pseudo amodal masks。这样相当于在 training set 上免费拿到了一批 amodal mask。
然后来看看这些 amodal mask 质量和人工标注的 amodal mask 的对比。研究者使用不同来源的 amodal mask 作为监督,用 Mask R-CNN 在 KITTI 上训练了 amodal instance segmentation 任务,并在人工标注的测试集上测试。结果发现本文所提方法获得的 amodal mask 和人工标注获得了正好一样的结果。这意味着以后可能再也不需要标 amodal mask 了。
既然现在能将场景分解开,那么就可以对场景进行编辑和重组。如下图,其中的 baseline modal-based manipulation 是基于普通的 image inpainting 做的,只有 modal mask,没有 ordering 和 amodal mask。本文提出的方法基于 ordering 和 amodal mask,能做更加自然的场景编辑。
研究者也做了一个图片编辑的 GUI,demo 如下:
-
Instance segmentation 的 data augmentation。还记得去年有一篇很棒的工作(InstaBoost [2], ICCV2019),通过移动物体来做 data augmentation,但是不能解决移动物体过程中的遮挡问题。现在配合 scene de-occlusion,也许可以做得更好。
-
帮助 panoptic segmentation 后处理中的 mask fusion 步骤。
-
应用到增强现实(AR)中。例如下图,对真实场景做 de-occlusion 之后,就可以将虚拟的物体放在真实物体的后面。
1. 可以解决两个物体互相遮挡吗?不能。因为如下图中的互相遮挡的情况中,无法定义 ordering graph。ordering graph 是 object level 的,而互相遮挡则需要 boundary-level de-occlusion。也相当于留下了一个 open question 供大家思考。
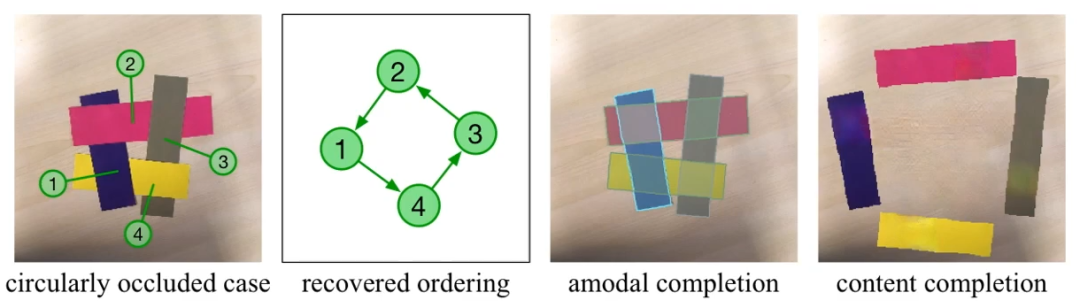
2. 可以解决多个物体循环遮挡吗?可以。因为该方法是按照 pairwise 来恢复顺序的,所以循环遮挡不会有问题。如下图(因为循环遮挡例子比较少见,作者用剪刀剪了几张纸片来摆了这么一张图,然后跑了一下测试),预测出来的 ordering graph 也是一个环。
[1] Xiaohang Zhan, Xingang Pan, Bo Dai, Ziwei Liu, Dahua Lin, and Chen Change Loy. Self-Supervised Scene De-occlusion. In CVPR 2020.
[2] Hao-Shu Fang, Jianhua Sun, Runzhong Wang, Minghao Gou, Yong-Lu Li, and Cewu Lu. Instaboost: Boosting instance segmentation via probability map guided copy-pasting. In ICCV 2019.
1、ICLR 2020 系列直播
直播主题:ICLR 2020丨Action Semantics Network: Considering the Effects of Actions in Multiagent Systems
主讲人:王维埙
直播时间:4月23日 (周四晚)20:00整
直播主题:ICLR 2020丨通过负采样从专家数据中学习自我纠正的策略和价值函数
主讲人:罗雨屏
直播时间:4月24日 (周五上午) 10:00整
直播主题:ICLR 2020丨分段线性激活函数塑造了神经网络损失曲面
主讲人:何凤翔
直播时间:4月24日 (周五晚) 20:00整
2、ACL 2020 - 复旦大学系列解读
直播主题:不同粒度的抽取式文本摘要系统
主讲人:王丹青、钟鸣
直播时间:4月 25 日,(周一晚) 20:00整。
直播主题:结合词典的中文命名实体识别【ACL 2020 - 复旦大学系列解读之(二)】
主讲人:马若恬, 李孝男
直播时间:4月 26 日,(周一晚) 20:00整。
直播主题:ACL 2020 | 基于对抗样本的依存句法模型鲁棒性分析
【ACL 2020 - 复旦大学系列解读之(三)】
主讲人:曾捷航
直播时间:4月 27 日,(周一晚) 20:00整。
扫码关注[ AI研习社顶会小助手] 微信号,发送关键字“ICLR 2020+直播” 或 “ACL 2020+直播”,即可进相应直播群,观看直播和获取课程资料。
![]()