个性化推荐如何满足用户口味?微信看一看的技术这样做

在微信AI背后,技术究竟如何让一切发生?关注微信AI公众号,我们将为你一一道来。今天起,微信AI推出技术专题系列“微信看一看背后的技术架构详解”,干货满满,敬请关注。以下为本专题的第一篇《微信看一看推荐排序》。
背 景
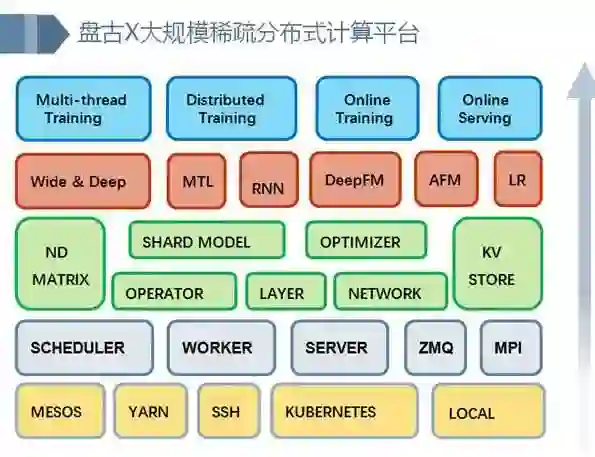
整体架构
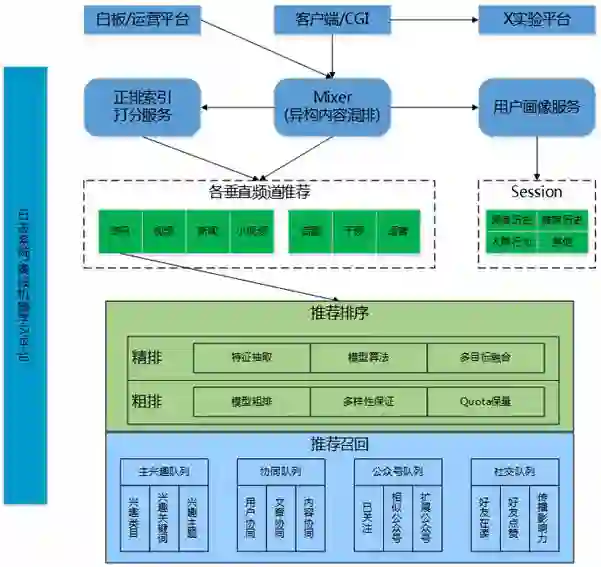
基础数据和召回
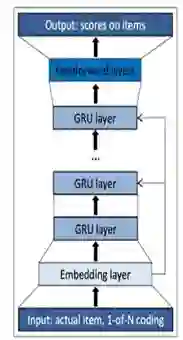
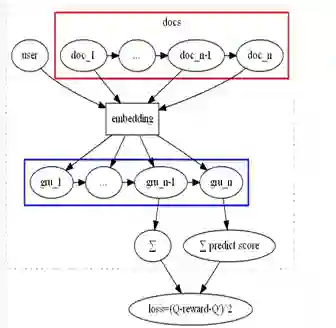
排 序

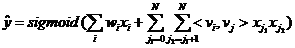
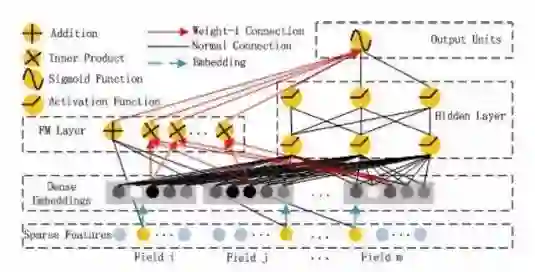
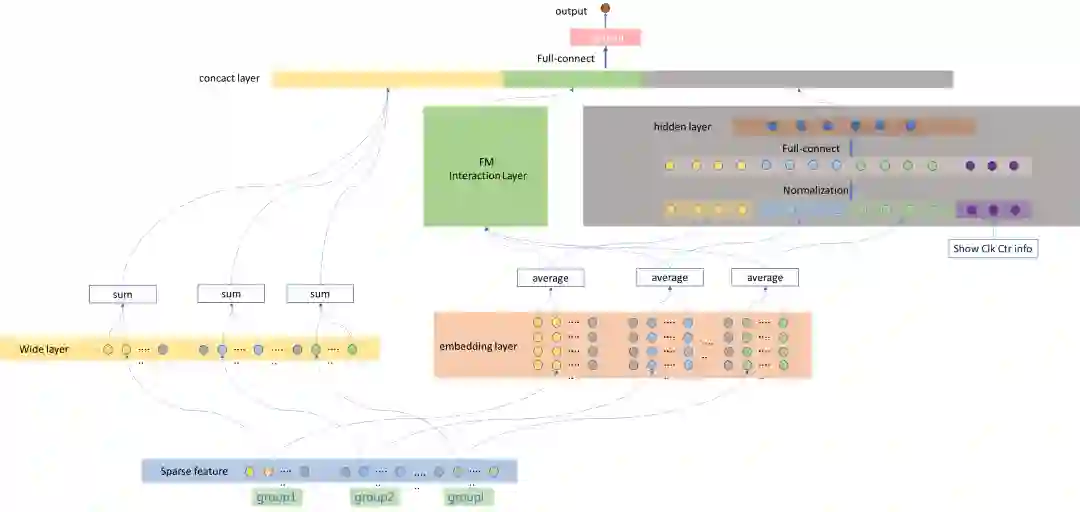
多目标
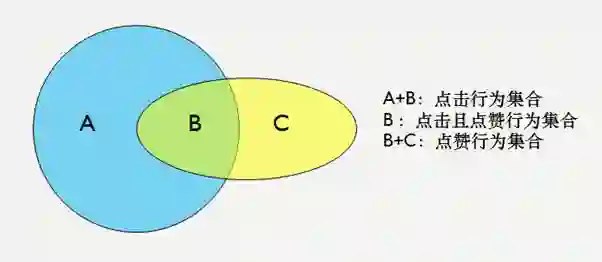
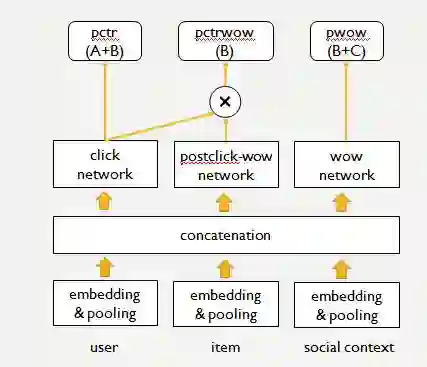
重排与多样性
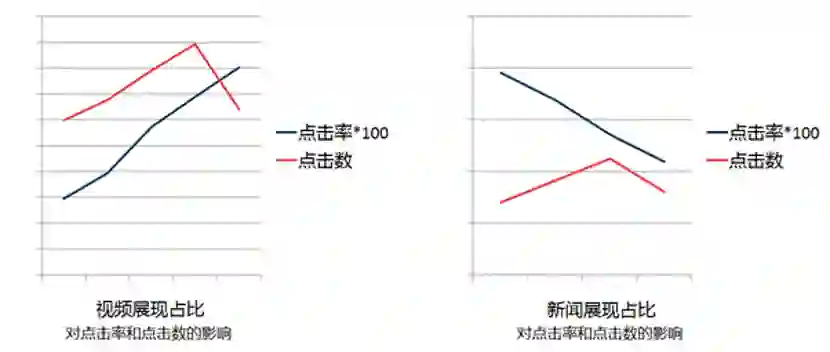
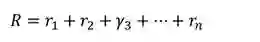
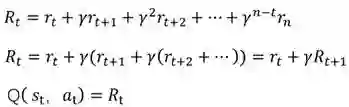
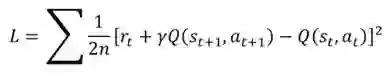

工程挑战
后 记
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。
登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月17日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月17日