西电TKDE 2021 | 可解释高效的异质图卷积神经网络

作者 | 杨亚明,管子玉,李建新
赵伟,崔江涛,王泉
论文地址:https://www.zhuanzhi.ai/paper/c55c7aa0af69bfeee9a7499f5824f530
代码地址:https://github.com/kepsail/ie-HGCN
1. 引言
2. 方法
下图通过在DBLP上的一个模型实例展示了方法的基本流程。如左侧子图(a)所示,模型一共包含5层。在每一层,针对某个对象类型,都将其异质邻居的特征聚合过来(实线),同时也将其自身的上一层的特征聚合过来(虚线)。右侧子图(b)展示了针对P(Paper)类型对象的计算过程:(1)自身/邻居的特征投影;(2)利用归一化邻接矩阵聚合;(3)利用注意力聚合。
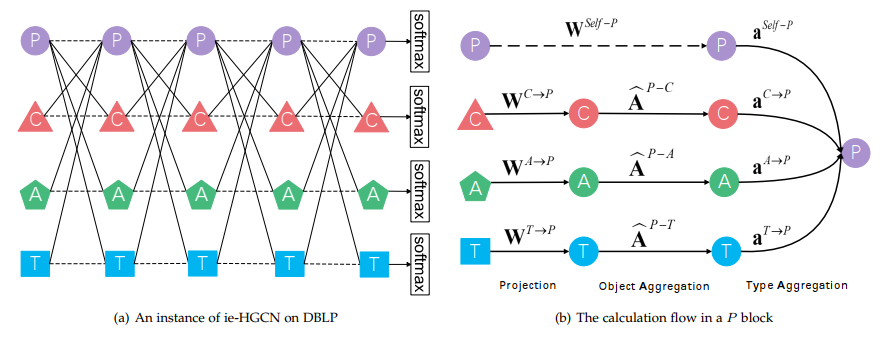
投影
考虑到在异质图里,不同类型的对象的特征通常有着不同的分布,因此在每一层,通过相关的投影矩阵把邻居特征映射到一个共同的语义空间中。同时,也将上一层输出的目标对象的自身特征也投影到这个空间:
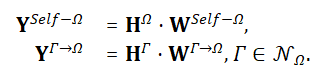
对象级聚合
对于每种类型的邻居,通过相应的行归一化的邻接矩阵将其投影后的特征聚合起来。这里,自身的投影特征不需要执行对象级聚合。至此,形成若干个临时的特征,即:目标对象自身的投影特征,以及聚合的各种类型的邻居的投影特征。每种特征都从不同的方面反映了目标对象的特性。
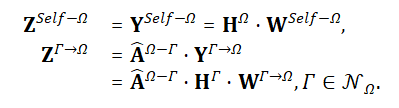
类型级聚合
利用注意力机制将这些临时的特征聚合起来,从而全面地刻画目标对象的特性。首先,通过不同的参数将目标对象的自身投影特征映射为注意力的查询值和键值,也通过不同的参数将邻居的聚合特征映射为相应的键值:
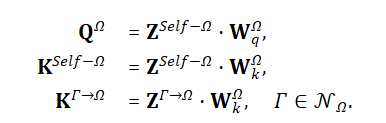
然后,通过一个小型的非线性神经网络将查询与键值映射为注意力系数:
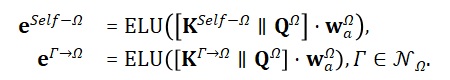
通过softmax函数将注意力系数归一化:
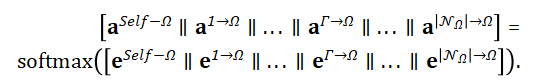
利用归一化的注意力系数,将若干个临时特征聚合起来,形成目标对象本层输出的新的特征:
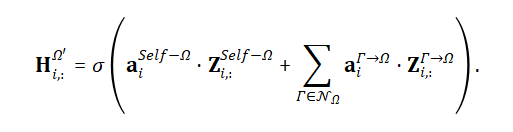
3. 理论分析
论文从理论上证明、分析了该模型具有以下三个良好的性质:
在粗粒度和细粒度两个层面上,可以自动发现针对当前任务最优的原路径。
模型实际上是在谱域执行异质谱图卷积。
具有近似线性的时间复杂度。
4. 实验
论文在4个公开的真实数据集上与若干个先进的基线方法进行了实验比较。结果显示该模型能够取得优越的性能以及效率。最重要的是,模型可以有效地自动发现最有用的元路径,从而促进了模型的可解释性。我们考虑在DBLP数据集上对作者(A)类型的对象进行分类任务。下图展示了模型发现的针对此任务最有用的若干元路径。上方的子图(a)展示了每一层中,每个目标对象类型与邻居类型(包括自身)之间的归一化注意力系数。下方的子图(b)展示了最有用的几条元路径的重要性得分及其计算过程。其中,第二列中的符号“—”代表了自连接(如图1中的虚线所示),这表明了有些路径是可以“坍缩”的。如此,经过合并一系列等价的路径,我们可以得到任意长度的元路径(第一列)的重要性得分。
很明显,我们可以看到,元路径CPA的得分最高,而该路径的语义是:作者(A)将其论文(P)发表到了会议(C)。令人鼓舞的是,这与数据集的真实情况高度吻合。实际上,这个数据集中,作者(A)类型对象的真实类别标签(ground-truth label)就是根据作者的论文(P)所发表的会议(C)来被标记的。
其他几个得分高的元路径也可以得到合理的解释。元路径CPTPA表明除了作者自己所发表论文的会议以外,另外一些会议也很重要,这些会议里的论文和作者的论文有很多共同的关键词(T)。元路径CPAPA表明作者的共同合作者所发表论文的会议也很重要。元路径CPCPA也比较有意思,因为一篇论文通常只会被发表到一个会议,从而左侧的子路径CPC等价于子路径C,进而CPCPA也可以被解释为CPA。
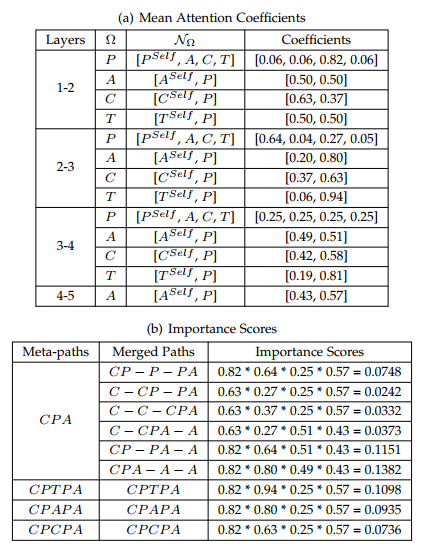
图2 模型自动发现的最有用的若干元路径
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“IEGCN” 就可以获取《西电TKDE 2021 | 可解释高效的异质图卷积神经网络》专知下载链接




