攻克目标检测难点:模型加速之轻量化网络
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
目标检测难点概述
对于小目标物体的检测(如小于30像素的目标物体)、遮挡面积较大的目标以及区分图像中与目标物体外形相似的非目标物体等问题需要在今后的研究中继续加强。
实时性检测与处理。对于自动驾驶或汽车辅助驾驶等对实时处理能力要求较高的应用场景,进一步提高目标检测的计算速度和准确度是至关重要的。
提高小数据量训练的检测效果。目前迁移学习的实现策略是先在现有大数据中进行训练,然后再将模型进行微调。虽然此方法能够实现,但检测精度和速度还有待进一步提高。
目前基于深度学习的目标检测所涉及的行业领域越来越多,很难获取大量的监督数据或数据的标准成本过高,进而导致缺少用于网络训练的样本数据。
秘籍一. 模型加速之轻量化网络
1 SqueezeNet:压缩再扩展

SqueezeNet层:首先使用1×1卷积进行降维,特征图的尺寸不变,这里的S1小于M,达到了压缩的目的。
Expand层:并行地使用1×1卷积与3×3卷积获得不同感受野的特征图,类似Inception模块,达到扩展的目的。
Concat合并:对得到的两个特征图进行通道拼接,作为最终输出。·模块中的S1、e1与e2都是可调的超参,Fire Module默认e1=e2=4×S1。激活函数使用了ReLU函数。
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
hidden_dim = round(inp * expand_ratio)
self.conv = nn.Sequential(
nn.Conv2d(inp, hidden_dim,
1,
1,
0, bias=
False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=
True),
nn.Conv2d(hidden_dim, hidden_dim,
3, stride,
1,
groups=hidden_dim, bias=
False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=
True),
nn.Conv2d(hidden_dim, oup,
1,
1,
0, bias=
False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
return x + self.conv(x)

2 MobileNet:深度可分离


class MobileNetV1(nn.Module):
def __init__(self):
super(MobileNet, self).__init__()
def conv_bn(dim_in, dim_out, stride):
return nn.Sequential(
nn.Conv2d(dim_in, dim_out,
3, stride,
1, bias=
False),
nn.BatchNorm2d(dim_out),
nn.ReLU(inplace=
True)
)
def conv_dw(dim_in, dim_out, stride):
return nn.Sequential(
nn.Conv2d(dim_in, dim_in,
3, stride,
1,
groups= dim_in, bias=
False),
nn.BatchNorm2d(dim_in),
nn.ReLU(inplace=
True),
nn.Conv2d(dim_in, dim_out,
1,
1,
0, bias=
False),
nn.BatchNorm2d(dim_out),
nn.ReLU(inplace=
True),
)
self.model = nn.Sequential(
conv_bn(
3,
32,
2),
conv_dw(
32,
64,
1),
conv_dw(
64,
128,
2),
conv_dw(
128,
128,
1),
conv_dw(
128,
256,
2),
conv_dw(
256,
256,
1),
conv_dw(
256,
512,
2),
conv_dw(
512,
512,
1),
conv_dw(
512,
512,
1),
conv_dw(
512,
512,
1),
conv_dw(
512,
512,
1),
conv_dw(
512,
512,
1),
conv_dw(
512,
1024,
2),
conv_dw(
1024,
1024,
1),
nn.AvgPool2d(
7),
)
self.fc = nn.Linear(
1024,
1000)
def forward(self, x):
x = self.model(x)
x = x.view(
-1,
1024)
x = self.fc(x)
return x
2.2 MobileNet V2



def conv_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup,
3, stride,
1, bias=
False),
nn.BatchNorm2d(oup),
nn.ReLU6(inplace=
True)
)
def conv_1x1_bn(inp, oup):
return nn.Sequential(
nn.Conv2d(inp, oup,
1,
1,
0, bias=
False),
nn.BatchNorm2d(oup),
nn.ReLU6(inplace=
True)
)
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride
in [
1,
2]
hidden_dim = round(inp * expand_ratio)
self.use_res_connect = self.stride ==
1
and inp == oup
if expand_ratio ==
1:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim,
3, stride,
1, groups=hidden_dim, bias=
False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=
True),
# pw-linear
nn.Conv2d(hidden_dim, oup,
1,
1,
0, bias=
False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim,
1,
1,
0, bias=
False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=
True),
# dw
nn.Conv2d(hidden_dim, hidden_dim,
3, stride,
1, groups=hidden_dim, bias=
False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=
True),
# pw-linear
nn.Conv2d(hidden_dim, oup,
1,
1,
0, bias=
False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, n_class=1000, input_size=224, width_mult=1.):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel =
32
last_channel =
1280
interverted_residual_setting = [
# t, c, n, s
[
1,
16,
1,
1],
[
6,
24,
2,
2],
[
6,
32,
3,
2],
[
6,
64,
4,
2],
[
6,
96,
3,
1],
[
6,
160,
3,
2],
[
6,
320,
1,
1],
]
# building first layer
assert input_size %
32 ==
0
input_channel = int(input_channel * width_mult)
self.last_channel = int(last_channel * width_mult)
if width_mult >
1.0
else last_channel
self.features = [conv_bn(
3, input_channel,
2)]
# building inverted residual blocks
for t, c, n, s
in interverted_residual_setting:
output_channel = int(c * width_mult)
for i
in range(n):
if i ==
0:
self.features.append(block(input_channel, output_channel, s, expand_ratio=t))
else:
self.features.append(block(input_channel, output_channel,
1, expand_ratio=t))
input_channel = output_channel
# building last several layers
self.features.append(conv_1x1_bn(input_channel, self.last_channel))
# make it nn.Sequential
self.features = nn.Sequential(*self.features)
# building classifier
self.classifier = nn.Sequential(
nn.Dropout(
0.2),
nn.Linear(self.last_channel, n_class),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = x.mean(
3).mean(
2)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m
in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[
0] * m.kernel_size[
1] * m.out_channels
m.weight.data.normal_(
0, math.sqrt(
2. / n))
if m.bias
is
not
None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(
1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(
1)
m.weight.data.normal_(
0,
0.01)
m.bias.data.zero_()
扩张(1x1 conv) -> 抽取特征(3x3 depthwise)-> 压缩(1x1 conv)
当且仅当输入输出具有相同的通道数时,才进行残余连接
在最后“压缩”完以后,没有接ReLU激活,作者认为这样会引起较大的信息损失
该结构在输入和输出处保持紧凑的表示,同时在内部扩展到更高维的特征空间,以增加非线性每通道变换的表现力。
2.3 MobileNet V3
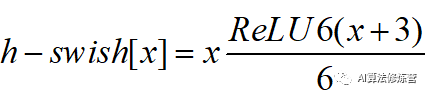


swish非线性激活
Squeeze and Excitation思想
为了减轻计算swish中传统sigmoid的代价,提出了hard sigmoid
class hswish(nn.Module):
def forward(self, x):
out = x * F.relu6(x +
3, inplace=
True) /
6
return out
class hsigmoid(nn.Module):
def forward(self, x):
out = F.relu6(x +
3, inplace=
True) /
6
return out
class SeModule(nn.Module):
def __init__(self, in_size, reduction=4):
super(SeModule, self).__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(
1),
nn.Conv2d(in_size, in_size // reduction, kernel_size=
1, stride=
1, padding=
0, bias=
False),
nn.BatchNorm2d(in_size // reduction),
nn.ReLU(inplace=
True),
nn.Conv2d(in_size // reduction, in_size, kernel_size=
1, stride=
1, padding=
0, bias=
False),
nn.BatchNorm2d(in_size),
hsigmoid()
)
def forward(self, x):
return x * self.se(x)
class Block(nn.Module):
expand + depthwise + pointwise
def __init__(self, kernel_size, in_size, expand_size, out_size, nolinear, semodule, stride):
super(Block, self).__init__()
self.stride = stride
self.se = semodule
self.conv1 = nn.Conv2d(in_size, expand_size, kernel_size=
1, stride=
1, padding=
0, bias=
False)
self.bn1 = nn.BatchNorm2d(expand_size)
self.nolinear1 = nolinear
self.conv2 = nn.Conv2d(expand_size, expand_size, kernel_size=kernel_size, stride=stride, padding=kernel_size//
2, groups=expand_size, bias=
False)
self.bn2 = nn.BatchNorm2d(expand_size)
self.nolinear2 = nolinear
self.conv3 = nn.Conv2d(expand_size, out_size, kernel_size=
1, stride=
1, padding=
0, bias=
False)
self.bn3 = nn.BatchNorm2d(out_size)
self.shortcut = nn.Sequential()
if stride ==
1
and in_size != out_size:
self.shortcut = nn.Sequential(
nn.Conv2d(in_size, out_size, kernel_size=
1, stride=
1, padding=
0, bias=
False),
nn.BatchNorm2d(out_size),
)
def forward(self, x):
out = self.nolinear1(self.bn1(self.conv1(x)))
out = self.nolinear2(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
if self.se !=
None:
out = self.se(out)
out = out + self.shortcut(x)
if self.stride==
1
else out
return out
class MobileNetV3_Large(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV3_Large, self).__init__()
self.conv1 = nn.Conv2d(
3,
16, kernel_size=
3, stride=
2, padding=
1, bias=
False)
self.bn1 = nn.BatchNorm2d(
16)
self.hs1 = hswish()
self.bneck = nn.Sequential(
Block(
3,
16,
16,
16, nn.ReLU(inplace=
True),
None,
1),
Block(
3,
16,
64,
24, nn.ReLU(inplace=
True),
None,
2),
Block(
3,
24,
72,
24, nn.ReLU(inplace=
True),
None,
1),
Block(
5,
24,
72,
40, nn.ReLU(inplace=
True), SeModule(
40),
2),
Block(
5,
40,
120,
40, nn.ReLU(inplace=
True), SeModule(
40),
1),
Block(
5,
40,
120,
40, nn.ReLU(inplace=
True), SeModule(
40),
1),
Block(
3,
40,
240,
80, hswish(),
None,
2),
Block(
3,
80,
200,
80, hswish(),
None,
1),
Block(
3,
80,
184,
80, hswish(),
None,
1),
Block(
3,
80,
184,
80, hswish(),
None,
1),
Block(
3,
80,
480,
112, hswish(), SeModule(
112),
1),
Block(
3,
112,
672,
112, hswish(), SeModule(
112),
1),
Block(
5,
112,
672,
160, hswish(), SeModule(
160),
1),
Block(
5,
160,
672,
160, hswish(), SeModule(
160),
2),
Block(
5,
160,
960,
160, hswish(), SeModule(
160),
1),
)
self.conv2 = nn.Conv2d(
160,
960, kernel_size=
1, stride=
1, padding=
0, bias=
False)
self.bn2 = nn.BatchNorm2d(
960)
self.hs2 = hswish()
self.linear3 = nn.Linear(
960,
1280)
self.bn3 = nn.BatchNorm1d(
1280)
self.hs3 = hswish()
self.linear4 = nn.Linear(
1280, num_classes)
self.init_params()
def init_params(self):
for m
in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode=fan_out)
if m.bias
is
not
None:
init.constant_(m.bias,
0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight,
1)
init.constant_(m.bias,
0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=
0.001)
if m.bias
is
not
None:
init.constant_(m.bias,
0)
def forward(self, x):
out = self.hs1(self.bn1(self.conv1(x)))
out = self.bneck(out)
out = self.hs2(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out,
7)
out = out.view(out.size(
0),
-1)
out = self.hs3(self.bn3(self.linear3(out)))
out = self.linear4(out)
return out
class MobileNetV3_Small(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV3_Small, self).__init__()
self.conv1 = nn.Conv2d(
3,
16, kernel_size=
3, stride=
2, padding=
1, bias=
False)
self.bn1 = nn.BatchNorm2d(
16)
self.hs1 = hswish()
self.bneck = nn.Sequential(
Block(
3,
16,
16,
16, nn.ReLU(inplace=
True), SeModule(
16),
2),
Block(
3,
16,
72,
24, nn.ReLU(inplace=
True),
None,
2),
Block(
3,
24,
88,
24, nn.ReLU(inplace=
True),
None,
1),
Block(
5,
24,
96,
40, hswish(), SeModule(
40),
2),
Block(
5,
40,
240,
40, hswish(), SeModule(
40),
1),
Block(
5,
40,
240,
40, hswish(), SeModule(
40),
1),
Block(
5,
40,
120,
48, hswish(), SeModule(
48),
1),
Block(
5,
48,
144,
48, hswish(), SeModule(
48),
1),
Block(
5,
48,
288,
96, hswish(), SeModule(
96),
2),
Block(
5,
96,
576,
96, hswish(), SeModule(
96),
1),
Block(
5,
96,
576,
96, hswish(), SeModule(
96),
1),
)
self.conv2 = nn.Conv2d(
96,
576, kernel_size=
1, stride=
1, padding=
0, bias=
False)
self.bn2 = nn.BatchNorm2d(
576)
self.hs2 = hswish()
self.linear3 = nn.Linear(
576,
1280)
self.bn3 = nn.BatchNorm1d(
1280)
self.hs3 = hswish()
self.linear4 = nn.Linear(
1280, num_classes)
self.init_params()
3 ShuffleNet:通道混洗
3.1 ShuffleNet V1

Reshape:首先将输入通道一个维度Reshape成两个维度,一个是卷积组数,一个是每个卷积组包含的通道数。
Transpose:将扩展出的两维进行置换。
Flatten:将置换后的通道Flatten平展后即可完成最后的通道混洗。


g代表组卷积的组数,以控制卷积连接的稀疏性。组数越多,计算量越少,因此在相同的计算资源,可以使用更多的卷积核以获取更多的通道数。
ShuffleNet在3个阶段内使用了其特殊的基本单元,这3个阶段的第一个Block的步长为2以完成降采样,下一个阶段的通道数是上一个的两倍。
深度可分离卷积虽然可以有效降低计算量,但其存储访问效率较差,因此第一个卷积并没有使用ShuffleNet基本单元,而是只在后续3个阶段使用。
class ShuffleNetV1(nn.Module):
def __init__(self, groups=3, in_channels=3, num_classes=1000):
super(ShuffleNet, self).__init__()
self.groups = groups
self.stage_repeats = [
3,
7,
3]
self.in_channels = in_channels
self.num_classes = num_classes
self.stage_out_channels = [
-1,
24,
240,
480,
960]
self.conv1 = conv3x3(self.in_channels,
self.stage_out_channels[
1],
# stage 1
stride=
2)
self.maxpool = nn.MaxPool2d(kernel_size=
3, stride=
2, padding=
1)
self.stage2 = self._make_stage(
2)
self.stage3 = self._make_stage(
3)
self.stage4 = self._make_stage(
4)
num_inputs = self.stage_out_channels[
-1]
self.fc = nn.Linear(num_inputs, self.num_classes)
def _make_stage(self, stage):
modules = OrderedDict()
stage_name = ShuffleUnit_Stage{}.format(stage)
grouped_conv = stage >
2
first_module = ShuffleUnit(
self.stage_out_channels[stage
-1],
self.stage_out_channels[stage],
groups=self.groups,
grouped_conv=grouped_conv,
combine=concat
)
modules[stage_name+_0] = first_module
for i
in range(self.stage_repeats[stage
-2]):
name = stage_name + _{}.format(i+
1)
module = ShuffleUnit(
self.stage_out_channels[stage],
self.stage_out_channels[stage],
groups=self.groups,
grouped_conv=
True,
combine=add
)
modules[name] = module
return nn.Sequential(modules)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = F.avg_pool2d(x, x.data.size()[
-2:])
x = x.view(x.size(
0),
-1)
x = self.fc(x)
return F.log_softmax(x, dim=
1)
3.2 ShuffleNet V2
在Bottleneck中使用了1×1组卷积与1×1的逐点卷积,导致输入输出通道数不同,违背了规则1与规则2。
整体网络中使用了大量的组卷积,造成了太多的分组,违背了规则3。
网络中存在大量的逐点相加操作,违背了规则4。


class ShuffleBlock(nn.Module):
def __init__(self, groups):
super(ShuffleBlock, self).__init__()
self.groups = groups
def forward(self, x):
Channel shuffle: [N,C,H,W] -> [N,g,C/g,H,W] -> [N,C/g,g,H,w] -> [N,C,H,W]
N,C,H,W = x.size()
g = self.groups
# 维度变换之后必须要使用.contiguous()使得张量在内存连续之后才能调用view函数
return x.view(N,g,int(C/g),H,W).permute(
0,
2,
1,
3,
4).contiguous().view(N,C,H,W)
class Bottleneck(nn.Module):
def __init__(self, in_planes, out_planes, stride, groups):
super(Bottleneck, self).__init__()
self.stride = stride
# bottleneck层中间层的channel数变为输出channel数的1/4
mid_planes = int(out_planes/
4)
g =
1
if in_planes==
24
else groups
# 作者提到不在stage2的第一个pointwise层使用组卷积,因为输入channel数量太少,只有24
self.conv1 = nn.Conv2d(in_planes, mid_planes,
kernel_size=
1, groups=g, bias=
False)
self.bn1 = nn.BatchNorm2d(mid_planes)
self.shuffle1 = ShuffleBlock(groups=g)
self.conv2 = nn.Conv2d(mid_planes, mid_planes,
kernel_size=
3, stride=stride, padding=
1,
groups=mid_planes, bias=
False)
self.bn2 = nn.BatchNorm2d(mid_planes)
self.conv3 = nn.Conv2d(mid_planes, out_planes,
kernel_size=
1, groups=groups, bias=
False)
self.bn3 = nn.BatchNorm2d(out_planes)
self.shortcut = nn.Sequential()
if stride ==
2:
self.shortcut = nn.Sequential(nn.AvgPool2d(
3, stride=
2, padding=
1))
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.shuffle1(out)
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
res = self.shortcut(x)
out = F.relu(torch.cat([out,res],
1))
if self.stride==
2
else F.relu(out+res)
return out
class ShuffleNet(nn.Module):
def __init__(self, cfg):
super(ShuffleNet, self).__init__()
out_planes = cfg[out_planes]
num_blocks = cfg[num_blocks]
groups = cfg[groups]
self.conv1 = nn.Conv2d(
3,
24, kernel_size=
1, bias=
False)
self.bn1 = nn.BatchNorm2d(
24)
self.in_planes =
24
self.layer1 = self._make_layer(out_planes[
0], num_blocks[
0], groups)
self.layer2 = self._make_layer(out_planes[
1], num_blocks[
1], groups)
self.layer3 = self._make_layer(out_planes[
2], num_blocks[
2], groups)
self.linear = nn.Linear(out_planes[
2],
10)
def _make_layer(self, out_planes, num_blocks, groups):
layers = []
for i
in range(num_blocks):
if i ==
0:
layers.append(Bottleneck(self.in_planes,
out_planes-self.in_planes,
stride=
2, groups=groups))
else:
layers.append(Bottleneck(self.in_planes,
out_planes,
stride=
1, groups=groups))
self.in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.avg_pool2d(out,
4)
out = out.view(out.size(
0),
-1)
out = self.linear(out)
return out
总结
推荐阅读:


△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~

