ECCV 2020 Oral | TCGM:基于信息论的半监督多模态学习框架

导读
本文是计算机视觉领域顶级会议 ECCV 2020 入选 Oral 论文《基于信息论的半监督多模态学习框架 (TCGM: An Information-Theoretic Framework for Semi-Supervised Multi-Modality Learning)》的解读。
论文链接:https://arxiv.org/abs/2007.06793

01
引言
比起仅仅利用单个模态的数据,融合多个模态的数据信息能够训练出更加准确且鲁棒的分类器。比如,模型可以用X光图片、临床指标等数据来预测病人的身体情况。但是在实际中,多模态的精标注数据十分昂贵,往往只能在每个模态上获取少量标注数据。如何利用少量的多模态标注数据来高效地训练分类器成为一个关键问题。
本文将这个问题转化为等价的半监督+多模态学习问题。在这个背景下,我们关注如何在训练中利用好未标注的多模态数据。本文的贡献在于,设计一个全相关(Total Correlation)的下界作为在未标注的多模态数据上的目标函数,来更好地融合跨模态的信息。全相关(Total Correlation)是关于多个随机变量之间共有信息的度量,在两个随机变量下全相关退化为互信息(Mutual Information)。
更具体地,本文提出去最大化每个模态的全相关增益(Total Correlation Gain)。每个模态上都有一个分类器,而这些分类器的共同的目标就是在未标注数据上,去最大化它们的全相关增益。若我们假设所有模态的信息关于真实标注(ground truth)是条件独立的,最大化全相关增益直观地来看是去找到所有模态之间的“信息交集”,即真实标注。如下图所示:左图是对条件独立的直观阐释,右图是对真实标注是“信息交集”的图示。在最大化全相关增益的过程中,每个模态上的分类器能够更好地利用其他模态的信息。
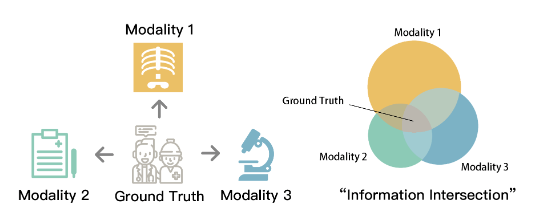
图1. (左图)条件独立假设;(右图)真实标注是“信息交集”
02
方法
给定未标注的数据集
关于如何衡量全相关增益,本文扩展[1]中的互信息增益到全相关增益上。它的实质是
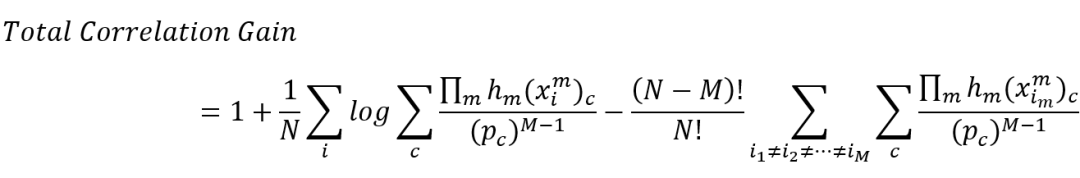
其中
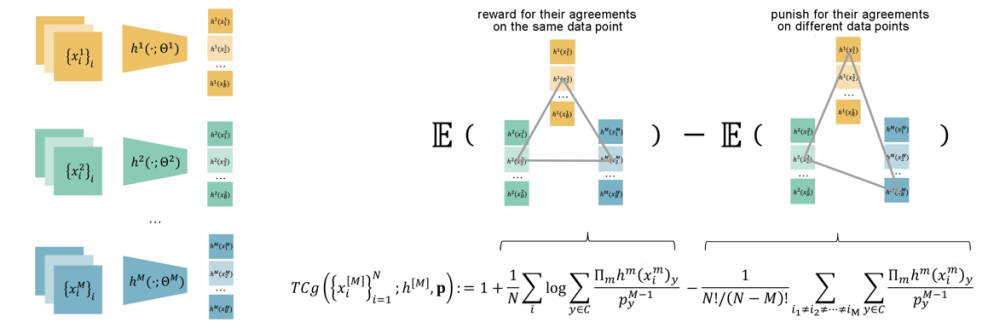
图2. 三个模态上 TCGM 的计算
03
实验结果
我们在三个多模态数据集上验证我们的方法:新闻分类数据集 Newsgroup;情感分类数据集 IEMOCAP 与 MOSI;与医疗图像数据集 ADNI。我们在不同比例的标注数据下做了多组实验,结果如下:

图3. Newsgroup 实验结果
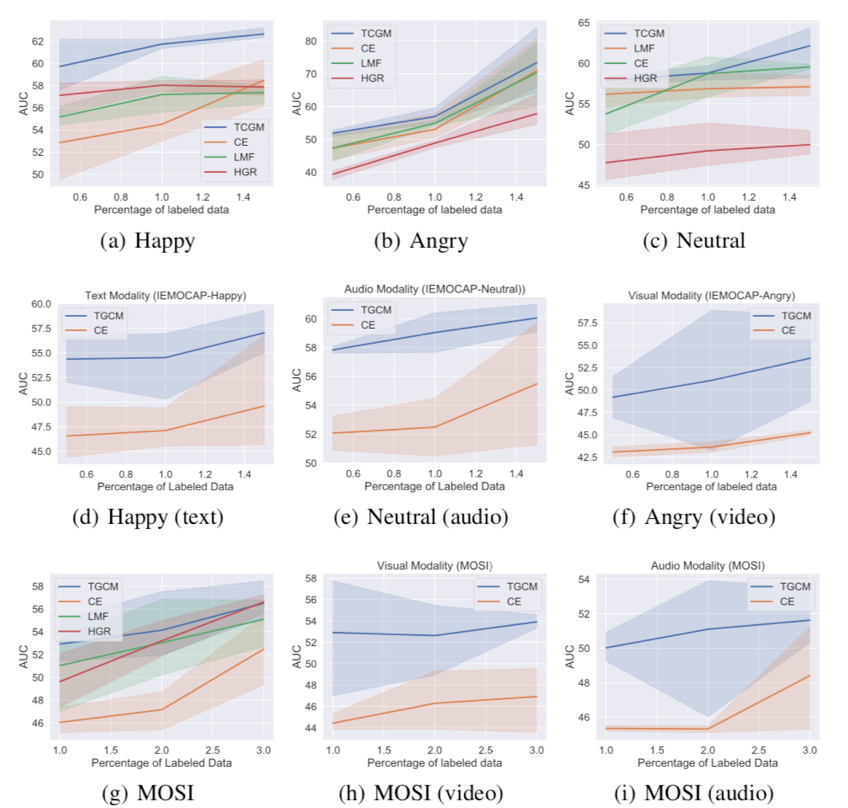
图4. IEMOCAP/MOSI(部分)实验结果
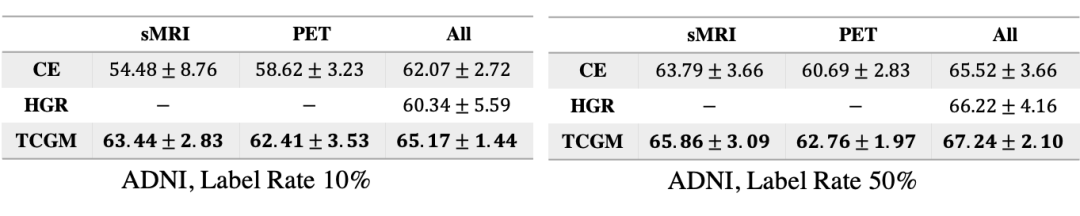
图5. ADNI 实验结果
我们的方法 TCGM(Total Correlation Gain Maximization)在不同的标注比例下的半监督+多模态学习中都取得较好效果。在训练中,不仅单个模态的分类器表现得到提升,在利用所有分类器来预测标注的情况下,TCGM 也好于其他方法。
04
总结
在本文中,我们提出了一个基于信息论的半监督多模态框架。在所有模态关于真实标注条件独立的假设下,我们通过在未标注数据上最大化全相关增益来融合各个模态之间的信息。理论和实验结果都证实了这个框架的有效性。
参考文献
[1] Peng Cao, Yilun Xu, Yuqing Kong and Yizhou Wang: Max-MIG: an Information Theoretic Approach for Joint Learning from Crowds. In ICLR 2019.
→ 论文解读
European Conference on Computer Vision (ECCV),即欧洲计算机视觉国际会议,是计算机视觉领域国际顶级会议,与计算机视觉模式识别会议(CVPR)和国际计算机视觉大会(IEEE ICCV)并称计算机视觉方向的三大顶级会议。ECCV每两年召开一次,受新冠疫情影响,ECCV 2020 将于2020年8月23-28日以在线方式举行。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“S358” 可以获取《358篇机器学习&自然语言处理综述论文》专知下载链接索引






