CVPR 2018 | Spotlight 论文:北京大学计算机研究所提出深度跨媒体知识迁移方法
机器之心发布
作者:Xin Huang、Yuxin Peng
近日,来自北京大学计算机科学技术研究所的博士生黄鑫和彭宇新教授提出了一种新型的迁移学习方法:深度跨媒体知识迁移(Deep Cross-media Knowledge Transfer, DCKT)。该方法针对跨媒体检索中训练样本不足导致检索效果差的问题,结合了两级迁移网络结构和渐进迁移机制,能够基于大规模跨媒体数据进行知识迁移,提高了小规模跨媒体数据上的检索准确率。在实验中,以大规模跨媒体数据集 XMediaNet 为源域,以 3 个广泛使用的小规模跨媒体数据集为目标域进行知识迁移与检索,结果表明 DCKT 有效提高了跨媒体检索的准确率。该论文已经被 CVPR 2018 大会接收为 Spotlight 论文。
一、简介
随着计算机与数字传输技术的快速发展,图像、文本、视频、音频等不同媒体数据已经随处可见,并作为相互融合的整体深刻影响和改变着我们的生活。认知科学表明,人类天然地具备接收与整合来自于不同感官通道的信息的能力。因此,如果能方便地检索出语义相关但媒体不同的数据,对于提高人们的信息获取效率具有重大意义。跨媒体检索是旨在进行跨越图像、文本等不同媒体类型的信息检索。例如,用户上传一张北京大学的图片,不仅能够得到有关北京大学的相关图片,也能检索到北京大学的文字描述、视频介绍、音频资料等。相比于传统的单媒体检索(如以文搜文、以图搜图等),跨媒体检索能够打破检索结果的媒体限制,从而增强搜索体验和结果的全面性。
「异构鸿沟」问题是跨媒体检索面临的一个核心挑战:不同媒体的数据具有不同的特征表示形式,它们的相似性难以直接度量。为解决上述问题,一种直观的方法是跨媒体统一表征,即把不同媒体数据从各自独立的表示空间映射到一个第三方的公共空间中,使得彼此可以度量相似性。近年来,随着深度学习的快速发展与广泛应用,基于深度学习的统一表征方法已经成为了研究的热点与主流。
然而,训练数据不足是深度学习的一个普遍挑战,而对于深度跨媒体检索方法来说则更加严峻。从模型训练的角度来讲,跨媒体关联关系呈现复杂多样的特点,使得深度网络需要从大规模、多样化、高质量的训练数据中学习关联线索。训练数据不足的问题严重限制了模型的训练效果。从人工成本的角度来讲,跨媒体数据的收集与标注需要耗费大量的人工劳动。例如,我们需要收集与「老虎」这一概念相关的跨媒体数据,不但需要看图片、读文本、听音频、看视频,还需要判断这些数据是否确实彼此相关。这使得针对特定域的检索问题往往难以收集到足够的样本进行训练。
在这种情况下,迁移学习思想就显得尤为重要,它能够从源域(一般是大规模数据集)中提取与迁移知识到目标域(一般是小规模数据集),从而提高目标域上的模型训练效果。如何从已有跨媒体数据集中迁移有价值的知识以提高新数据上的检索准确率,成为了跨媒体检索走向实际应用的一大挑战。然而,现有的迁移学习方法往往是从单媒体源域迁移至单媒体目标域,缺少从跨媒体源域到跨媒体目标域的知识迁移的研究。此外,现有方法往往假定源域和目标域具有共同的语义标签空间,而对于跨媒体数据集来说往往难以满足。针对上述问题,本文提出了深度跨媒体知识迁移方法,基于两级迁移网络和渐进迁移机制,能够从一个大规模跨媒体数据集中充分迁移知识,提高小规模数据集上的模型训练效果。
二、方法:深度跨媒体知识迁移
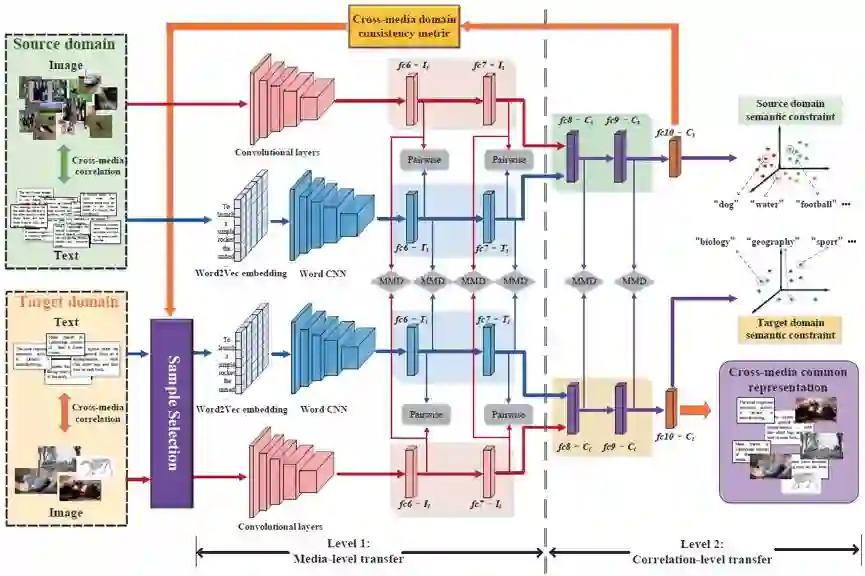
图 1:深度跨媒体知识迁移(DCKT)方法的总体框架。
本文提出了深度跨媒体知识迁移(DCKT)方法,其主要贡献在于:(1)提出了两级迁移网络,通过同时最小化媒体级、关联级的域间差异,使得互补的单媒体语义知识和跨媒体关联知识能够有效迁移;(2)提出了渐进迁移机制,通过自适应反馈的域间一致性度量,以迁移难度从小到大为原则进行迭代样本选择,使得迁移过程能够逐渐减小跨媒体域间差异,提高了模型的鲁棒性与检索准确率。方法的总体框架如图 1 所示,下面分别简要介绍。
1. 两级迁移网络:
大规模跨媒体数据集中存在着两种有价值的知识:(1)如果独立地看每个媒体,其中的每种媒体数据中都含有丰富的单媒体语义知识。(2)如果综合地去看所有媒体,不同媒体之间的关联模式也蕴含着丰富的跨媒体关联知识。针对上述两个重要且互补的方面,本文提出了两级迁移网络进行知识迁移。在媒体级迁移中,通过最小化两个域的同种媒体之间的表示分布差异,实现单媒体语义知识的迁移;在关联级迁移中,通过最小化两个域中共享网络层之间的表示分布差异,实现跨媒体关联知识的迁移。通过上述两方面的结合,达到单媒体语义知识与跨媒体关联知识的跨域共享。
2. 渐进迁移机制:

算法 1:本文提出渐进迁移机制的算法流程。
由于跨媒体数据集具有复杂的媒体内、媒体间关联,且源域和目标域的语义标签空间不一致,使得两个域之间的差异很大。对于目标域来说,部分样本和源域具有较明显的一致性,知识迁移较为容易,而某些样本的知识迁移则较为困难。如果同等对待所有训练样本,可能对知识迁移带来噪声甚至误导信息。因此,我们提出渐进式迁移机制(如算法 1 所示),以源域模型为指导,以迁移难度由小到大为原则进行自适应样本选择,在迭代反馈中逐渐减小域间差异,利用跨媒体数据的知识迁移解决跨媒体训练样本不足的问题。
三、实验
本文采用我们构造的大规模跨媒体数据集 XMediaNet 为源域。XMediaNet 包括 200 个语义类别的超过 10 万个标注数据,涵盖图像、文本、视频、音频和 3D 图形。XMediaNet 具有明确的语义类别,均为具体的物体(如 Dog、Airplane 等),避免了语义混淆。数据来自著名网站如 Wikipedia, Flickr, Youtube, Findsounds, Freesound, Yobi3D 等。在本文中,我们使用 XMediaNet 数据集的图像、文本数据作为源域,以 3 个广泛使用的小规模跨媒体数据集作为目标域进行跨媒体检索实验,包括以图像检索文本、以文本检索图像的双向交叉检索实验。在实验比较上,以 MAP 值为评测指标,与 12 个现有方法进行比较,结果表明本文提出的 DCKT 方法在 3 个数据集上均取得了最好的检索准确率(如表 1 所示)。
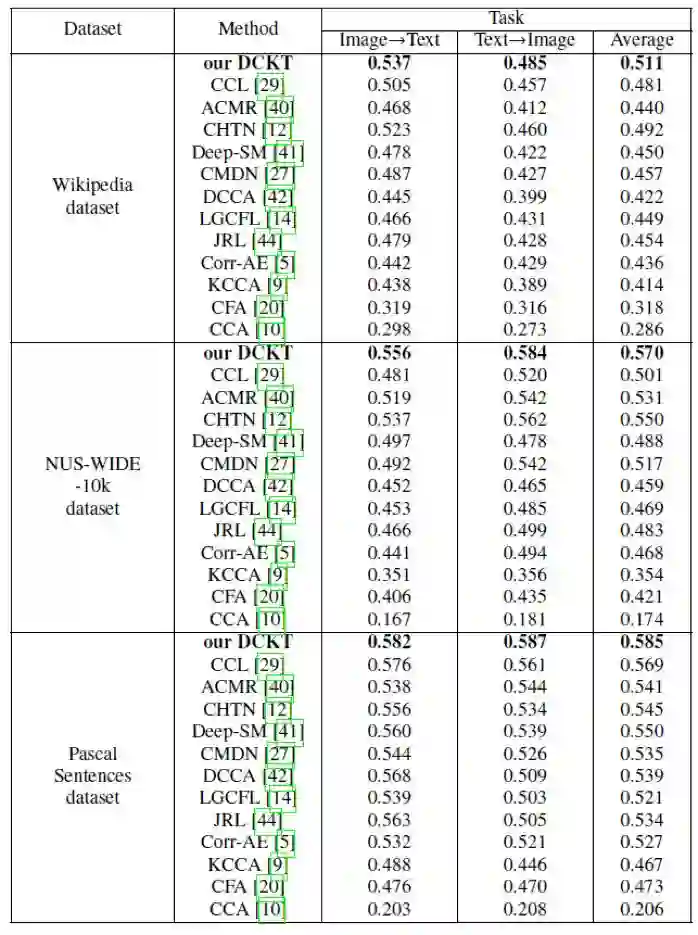
表 1:本文方法和现有方法在 3 个数据集上的检索 MAP 值。
论文: Deep Cross-media Knowledge Transfer(深度跨媒体知识迁移)

本文 arXiv 链接:https://arxiv.org/abs/1803.03777
课题组主页:http://www.icst.pku.edu.cn/mipl
课题组 Github 主页(已发布团队 IEEE TIP, TMM, TCSVT, CVPR, ACM MM, IJCAI, AAAI 等论文代码):https://github.com/PKU-ICST-MIPL
摘要:跨媒体检索是旨在进行跨越图像、文本等不同媒体类型的信息检索。跨媒体检索的准确率往往依赖于有标注的训练数据,然而由于跨媒体训练样本的收集与标注非常困难,如何从已有数据中迁移有价值的知识以提高新数据上的检索准确率,成为了跨媒体检索走向实际应用的一大挑战。本文提出了深度跨媒体知识迁移方法,能够基于大规模跨媒体数据进行知识迁移,提升小规模跨媒体数据上的模型训练效果。本文的主要贡献包括:(1)提出了两级迁移网络,通过同时最小化媒体级、关联级的域间差异,使得互补的单媒体语义知识和跨媒体关联知识能够有效迁移;(2)提出了渐进迁移机制,通过自适应地反馈域间的一致性度量,以迁移难度从小到大为原则进行迭代样本选择,使得迁移过程能够逐渐减小跨媒体域间的差异,提高了模型的鲁棒性与检索准确率。以大规模跨媒体数据集 XMediaNet 为源域,以 3 个广泛使用的小规模跨媒体数据集为目标域展开知识迁移与检索的实验,本文所提方法均有效提高了跨媒体检索的准确率。

本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



