学界 | 不设目标也能通关「马里奥」的AI算法,全靠好奇心学习
选自arXiv
作者:Yuri Burda等
机器之心编译
参与:高璇、晓坤
在强化学习中,设计密集、定义良好的外部奖励是很困难的,并且通常不可扩展。通常增加内部奖励可以作为对此限制的补偿,OpenAI、CMU 在本研究中更近一步,提出了完全靠内部奖励即好奇心来训练智能体的方法。在 54 个环境上的大规模实验结果表明:内在好奇心目标函数和手工设计的外在奖励高度一致;随机特征也能作为强大的基线。
通过与任务匹配的奖励函数最大化来训练智能体策略。对于智能体来说,奖励是外在的,并特定于它们定义的环境。只有奖励函数密集且定义良好时,多数的 RL 才得以成功实现,例如在电子游戏中的「得分」。然而设计一个定义良好的奖励函数非常困难。除了「塑造」外在奖励外,也可以增加密集的内在奖励,即由智能体本身产生奖励。内在奖励包括使用预测误差作为奖励信号的「好奇心」和阻止智能体重新访问相同状态的「访问计数」。其思想是,这些内在奖励通过引导智能体对环境进行有效地探索,以寻找下一个外在奖励,从而缩小与稀疏外在奖励间的差距。
强化学习算法依赖外在于智能体的工程环境奖励。但是,用手工设计的密集奖励来对每个环境进行标注的方式是不可扩展的,这就需要开发智能体的内在奖励函数。好奇心是一种利用预测误差作为奖励信号的内在奖励函数。在本文中:(a)对包括 Atari 游戏在内的 54 个标准基准环境进行了第一次大规模的纯好奇心驱动学习研究,即没有任何外在奖励。结果取得了惊艳的性能,并在许多游戏环境中,内在好奇心目标函数和手工设计的外在奖励高度一致。(b)研究了使用不同的特征空间计算预测误差的效果,表明随机特征对于许多流行的 RL 游戏基准来说已经足够了,但是学习特征似乎泛化能力更强 (例如迁移到《超级马里奥兄弟》中的新关卡)。(c)展示了随机设置中基于预测的奖励的局限性。
代码和模型链接:https://pathak22.github.io/large scale-curiosity/
1 引言
强化学习(RL)已经成为训练智能体以完成复杂任务的一种普遍的方法。在 RL 中,通过与任务匹配的奖励函数最大化来训练智能体策略。对于智能体来说,奖励是外在的,并特定于它们定义的环境。只有奖励函数密集且定义良好时,多数的 RL 才得以成功实现,例如在电子游戏中的「得分」。然而设计一个定义良好的奖励函数非常困难。除了「塑造」外在奖励外,也可以增加密集的内在奖励,即由智能体本身产生奖励。内在奖励包括使用预测误差作为奖励信号的「好奇心」和阻止智能体重新访问相同状态的「访问计数」。其思想是,这些内在奖励通过引导智能体对环境进行有效地探索,以寻找下一个外在奖励,从而缩小与稀疏外在奖励间的差距。
但如果完全没有外在奖励呢?发展心理学家认为内在动机(即好奇心)是人类发展早期阶段的主要动力:婴儿看似无目标的探索,其实可以学习到终身有益的技能。从玩《我的世界》到参观动物园,都没有外在奖励。调查表明,在特定环境中,仅使用内在奖励对智能体进行预训练,可以使它在新环境下对新任务进行微调时学习得更快。然而到目前为止,仅利用内在奖励的学习还未被系统地研究过。
在本文中,研究者对只由内在奖励驱动的智能体进行了大规模的实证研究。他们选择了 Pathak 等人提出的基于动力的好奇心的内在奖励模型,因为它可扩展、可简化并行,所以非常适用于大型实验。该方法的中心思想是将内在奖励看作在预测智能体当前状态的行为结果时的误差,即智能体学习的正向动力的预测误差。研究者深入研究了 54 个环境中基于动力的好奇心:如图 1 中的电子游戏、物理引擎模拟和虚拟 3D 导航任务。

图 1:54 个环境中的研究快照。研究者证明了智能体能够在不使用外在奖励或结束信号而只利用好奇心的情况下取得进展。
为了更好地理解好奇心驱动学习,研究者进一步研究了决定好奇心驱使学习表现的关键因素。在高维原始观测空间(如,图像)中预测未来状态还是颇具挑战的,但最近研究显示,辅助特征空间中的学习动力会改善这个结果。然而如何选择嵌入空间也是个关键又开放的问题。通过系统的控制变量研究,研究人员检验了编码智能体观测的不同方法,使智能体可以在只由好奇心驱动时也有优良表现。为保证动态在线训练的稳定性,嵌入空间应该:(a)维数紧凑;(b)保留足够的观测信息;(c)是观测的平稳函数。研究证明,通过随机网络对观察结果进行编码是一种简单而有效的技术,可用于在许多流行的 RL 基准中建模好奇心。这可能表明许多流行的 RL 视频游戏测试平台在视觉上并不复杂。有趣的是,虽然随机特征足以让玩家在训练中表现出色,但学习特征似乎泛化能力更好(如在《超级马里奥兄弟》中创造新的游戏关卡)。
总结:(a)研究者对好奇心驱动在各个环境中的探索进行了大量研究,包括: Atari 游戏、超级马里奥兄弟、Unity 中的虚拟 3D 导航、多人乒乓以及 Roboschool 环境。(b)研究者广泛研究了基于动力的好奇心的特征空间:随机特征、像素、反向动力学和变分自编码器,并评估了对未知环境的泛化能力。(c)最后讨论了基于好奇心的公式直接预测误差的局限性。他们发现,如果智能体本身是环境中随机源,那么它可以在没有任何实际进展的情况下奖励自己。研究人员在一个 3D 导航任务中证明了这种限制,其中智能体控制了环境的不同部分。
论文:Large-Scale Study of Curiosity-Driven Learning

论文地址:https://arxiv.org/pdf/1808.04355v1.pdf
摘要:强化学习算法依赖外在于智能体的工程环境奖励。但是,用手工设计的密集奖励来对每个环境进行标注的方式是不可扩展的,这就需要开发智能体的内在奖励函数。好奇心是一种利用预测误差作为奖励信号的内在奖励函数。在本文中:(a)对包括 Atari 游戏在内的 54 个标准基准环境进行了第一次大规模的纯好奇心驱动学习研究,即没有任何外在奖励。结果取得了惊艳的性能,并在许多游戏环境中,内在好奇心目标函数和手工设计的外在奖励高度一致。(b)研究了使用不同的特征空间计算预测误差的效果,表明随机特征对于许多流行的 RL 游戏基准来说已经足够了,但是学习特征似乎泛化能力更强 (例如迁移到《超级马里奥兄弟》中的新关卡)。(c)展示了随机设置中基于预测的奖励的局限性。
3 实验
3.1 无外在奖励的好奇心驱动学习
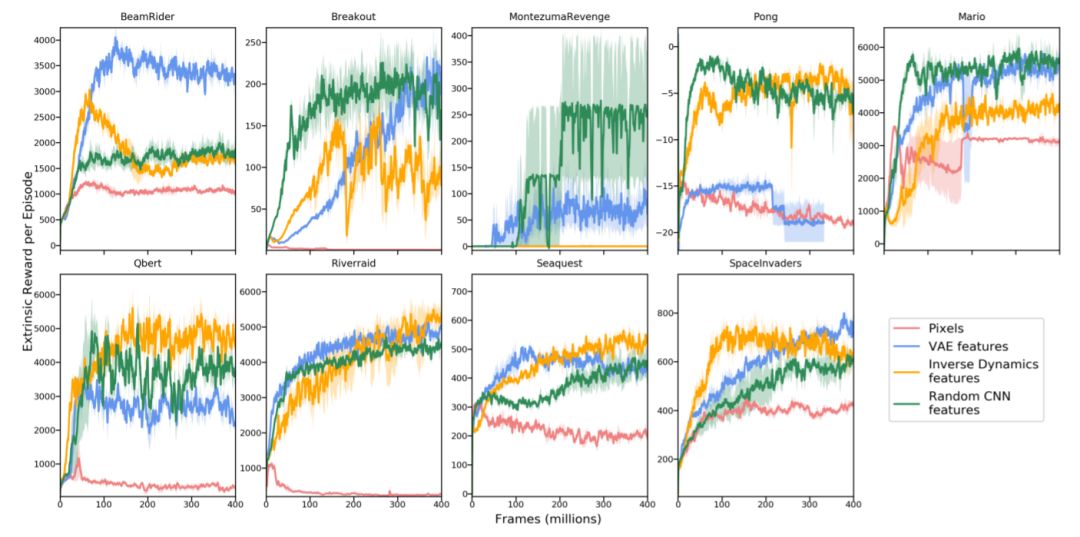
图 2:8 款 Atari 游戏和《超级马里奥兄弟》的特征学习方法对比。这些评估曲线显示了没有奖励或结束信号,仅是纯好奇心训练的 agent 平均奖励 (标准误差)。可以看到,纯好奇心驱动的 agent 无需外在奖励,就能够在这些环境中获得奖励。所有 Atari 游戏的结果都在图 8 的附录中。在像素上训练的好奇心模型在任何环境中都表现不佳,VAE 特征的表现要么与随机和反向动力特征相同,要么不如后者。此外在 55% 的 Atari 游戏中,反向动力训练的特征比随机特征表现得更好。有趣的是,好奇心模型的随机特征是一个简单却强大的基线,大致可在 Atari 的半数游戏中取得优良表现。
3.2 模型在《超级马里奥兄弟》新关卡的泛化能力
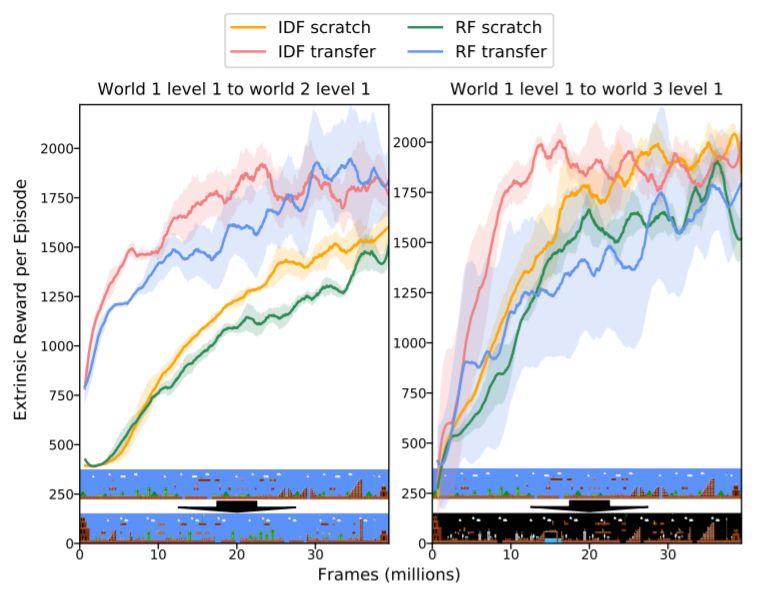
图 4:《马里奥》泛化实验结果。左图是 1-1 关到 1-2 关的迁移结果,右图是 1-1 关到 1-3 关的迁移结果。图下方是源和目标环境的地图。所有的智能体都是在无外在奖励的情况下训练出来的。
3.3 好奇心与稀疏的外在奖励
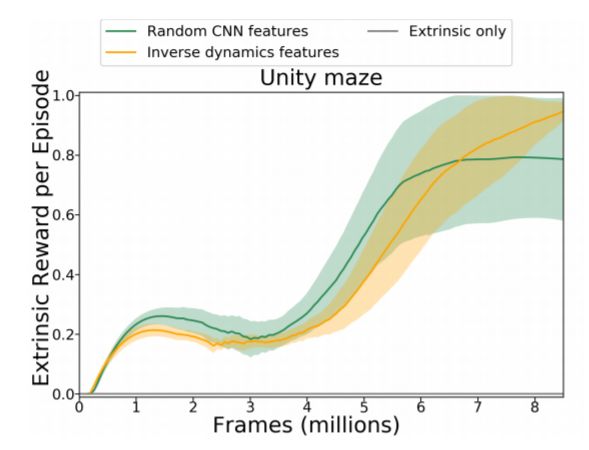
图 5:在最终外在奖励+好奇心奖励的训练中,在 Unity 环境下的平均外在奖励。注意,只有外在奖励的训练曲线始终为零。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




