在消费级 GPU 上运行大规模模型是机器学习社区正面临的挑战。
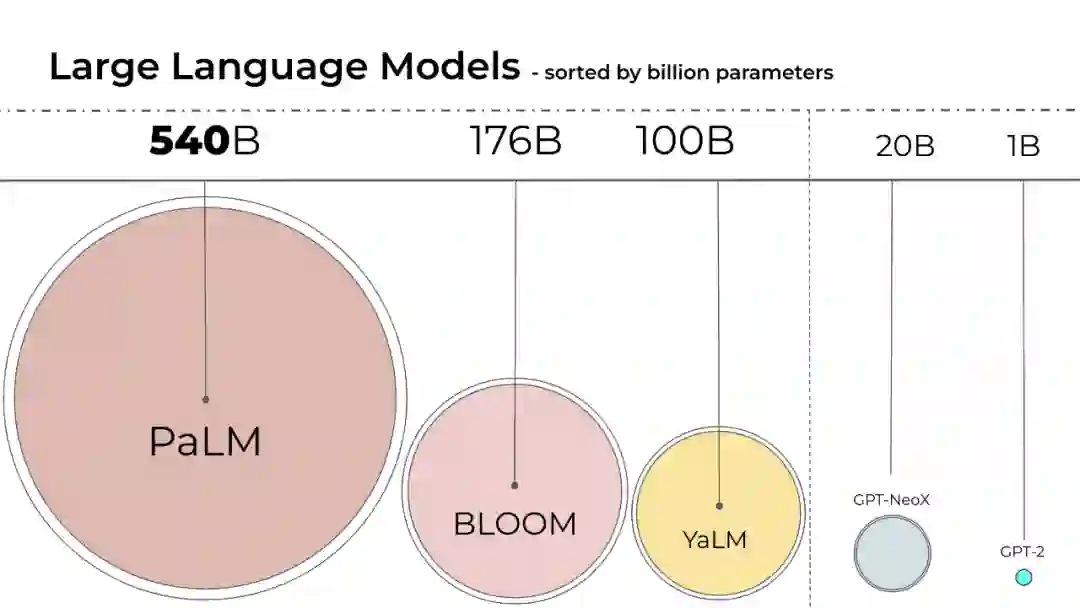
语言模型的规模一直在变大,PaLM 有 540B 参数,OPT、GPT-3 和 BLOOM 有大约 176B 参数,模型还在朝着更大的方向发展。
![]()
这些模型很难在易于访问的设备上运行。例如,BLOOM-176B 需要在 8 个 80GB A100 GPU(每个约 15000 美元)上运行才能完成推理任务,而微调 BLOOM-176B 则需要 72 个这样的 GPU。PaLM 等更大的模型将需要更多的资源。
我们需要找到方法来降低这些模型的资源需求,同时保持模型的性能。领域内已经开发了各种试图缩小模型大小的技术,例如量化和蒸馏。
BLOOM 是去年由 1000 多名志愿研究人员在一个名为「BigScience」的项目中创建的,该项目由人工智能初创公司 Hugging Face 利用法国政府的资金运作,今年 7 月 12 日 BLOOM 模型正式发布。
使用 Int8 推理会大幅减少模型的内存占用,却不会降低模型的预测性能。基于此,来自华盛顿大学、Meta AI 研究院等(原 Facebook AI Research )机构的研究员联合 HuggingFace 开展了一项研究,试图让经过训练的 BLOOM-176B 在更少的 GPU 上运行,并将所提方法完全集成到 HuggingFace Transformers 中。
![]()
-
论文地址:https://arxiv.org/pdf/2208.07339.pdf
-
Github 地址:https://github.com/timdettmers/bitsandbytes
该研究为 transformer 提出了首个数十亿规模的 Int8 量化过程,该过程不会影响模型的推理性能。它可以加载一个具有 16-bit 或 32-bit 权重的 175B 参数的 transformer,并将前馈和注意力投影层转换为 8-bit。其将推理所需的内存减少了一半,同时保持了全精度性能。
该研究将向量量化和混合精度分解的组合命名为 LLM.int8()。实验表明,通过使用 LLM.int8(),可以在消费级 GPU 上使用多达 175B 参数的 LLM 执行推理,而不会降低性能。该方法不仅为异常值对模型性能的影响提供了新思路,还首次使在消费级 GPU 的单个服务器上使用非常大的模型成为可能,例如 OPT-175B/BLOOM。
![]()
机器学习模型的大小取决于参数的数量及其精度,通常是 float32、float16 或 bfloat16 之一。float32 (FP32) 代表标准化的 IEEE 32 位浮点表示,使用这种数据类型可以表示范围广泛的浮点数。FP32 为「指数」保留 8 位,为「尾数」保留 23 位,为数字的符号保留 1 位。并且,大多数硬件都支持 FP32 操作和指令。
而 float16 (FP16) 为指数保留 5 位,为尾数保留 10 位。这使得 FP16 数字的可表示范围远低于 FP32,面临溢出(试图表示一个非常大的数字)和下溢(表示一个非常小的数字)的风险。
出现溢出时会得到 NaN(非数字)的结果,如果像在神经网络中那样进行顺序计算,那么很多工作都会崩溃。bfloat16 (BF16) 则能够避免这种问题。BF16 为指数保留 8 位,为小数保留 7 位,意味着 BF16 可以保留与 FP32 相同的动态范围。
理想情况下,训练和推理应该在 FP32 中完成,但它的速度比 FP16/BF16 慢,因此要使用混合精度来提高训练速度。但在实践中,半精度权重在推理过程中也能提供与 FP32 相似的质量。这意味着我们可以使用一半精度的权重并使用一半的 GPU 来完成相同的结果。
但是,如果我们可以使用不同的数据类型以更少的内存存储这些权重呢?一种称为量化的方法已广泛用于深度学习。
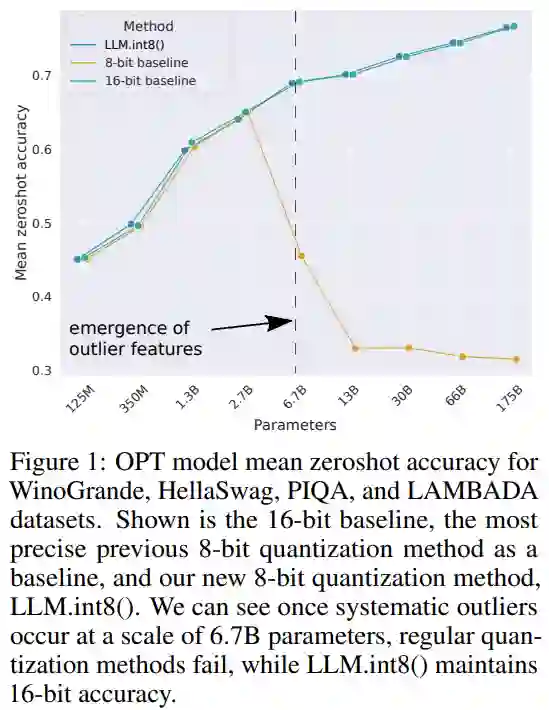
该研究首先在实验中用 2-byte BF16/FP16 半精度代替 4-byte FP32 精度,实现了几乎相同的推理结果。这样一来,模型减小了一半。但是如果进一步降低这个数字,精度会随之降低,那推理质量就会急剧下降。
为了弥补这一点,该研究引入 8bit 量化。这种方法使用四分之一的精度,因此只需要四分之一模型大小,但这不是通过去除另一半 bit 来实现的。
![]()
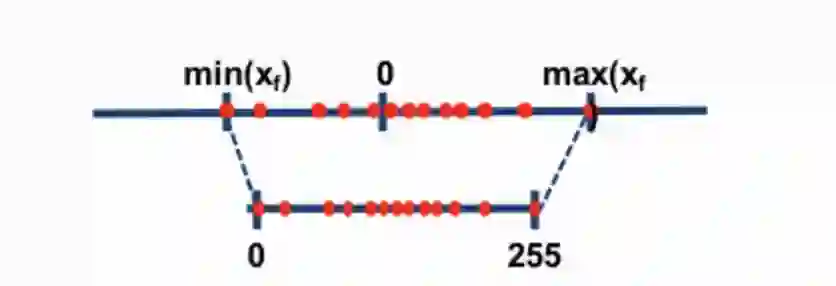
两种最常见的 8-bit 量化技术为 zero-point 量化和 absmax(absolute maximum)量化。这两种方法将浮点值映射为更紧凑的 int8(1 字节)值。
例如,在 zero-point 量化中,如果数据范围是 -1.0——1.0,量化到 -127——127,其扩展因子为 127。在这个扩展因子下,例如值 0.3 将被扩展为 0.3*127 = 38.1。量化通常会采用四舍五入(rounding),得到了 38。如果反过来,将得到 38/127=0.2992——在这个例子中有 0.008 的量化误差。这些看似微小的错误在通过模型层传播时往往会累积和增长,并导致性能下降。
![]()
虽然这些技术能够量化深度学习模型,但它们通常会导致模型准确率下降。但是集成到 Hugging Face Transformers 和 Accelerate 库中的 LLM.int8(),是第一种即使对于带有 176B 参数的大型模型 (如 BLOOM) 也不会降低性能的技术。
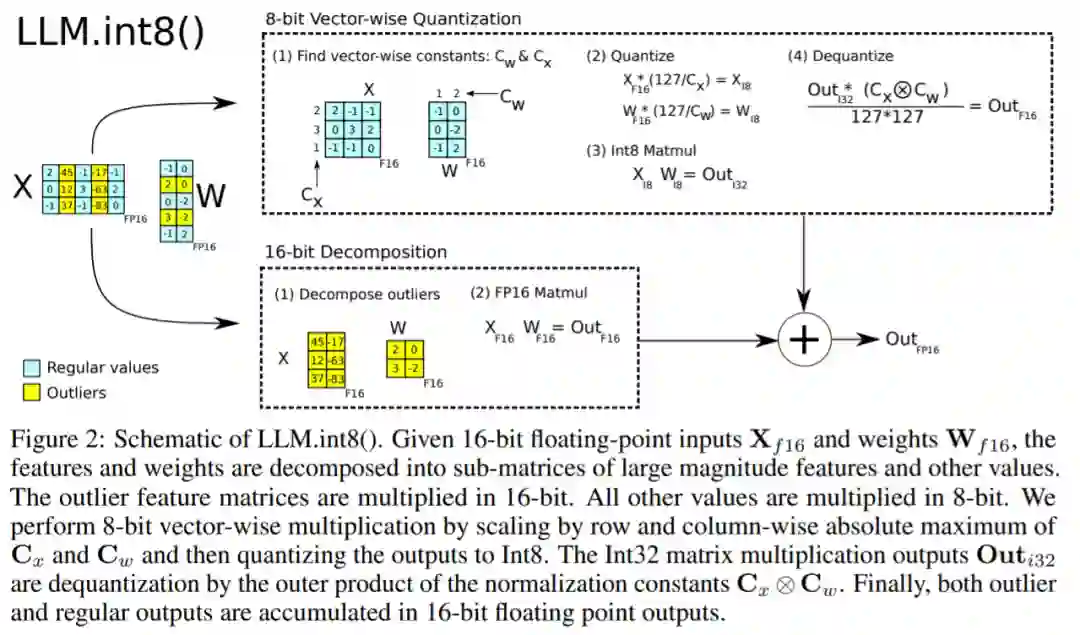
LLM.int8()算法可以这样解释,本质上,LLM.int8()试图通过三个步骤来完成矩阵乘法计算:
-
从输入隐藏状态中,按列提取异常值(即大于某个阈值的值)。
-
将 FP16 中的异常值与 int8 中的非异常值进行矩阵乘法。
-
在 FP16 中对非异常值进行去量化,将异常值和非异常值相加,得到完整的结果。
![]()
最后,该研究还关注了一个问题:速度比原生模型更快吗?
LLM.int8() 方法的主要目的是使大型模型更易于访问而不会降低性能。但是,如果它非常慢,那么用处也不大了。研究团队对多个模型的生成速度进行了基准测试,发现带有 LLM.int8() 的 BLOOM-176B 比 fp16 版本慢了大约 15% 到 23%——这是完全可以接受的。而较小的模型(如 T5-3B 和 T5-11B)的减速幅度更大。研究团队正在努力提升这些小型模型的运行速度。
![]()
掌握「声纹识别技术」:前20小时交给我,后9980小时……
《声纹识别:从理论到编程实战》中文课上线,由谷歌声纹团队负责人王泉博士主讲。
课程视频内容共 12 小时,着重介绍基于深度学习的声纹识别系统,包括大量学术界与产业界的最新研究成果。
同时课程配有 32 次课后测验、10 次编程练习、10 次大作业,确保课程结束时可以亲自上手从零搭建一个完整的声纹识别系统。
课程目前还在
首周优惠中
,欢迎对声纹领域感兴趣的同学一起学习。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com