ACL 2020 | 微软亚洲研究院精选论文带你一览NLP前沿!


编者按:自然语言处理顶会 ACL 2020 将于7月5日-10日在线举行。本届大会中,微软亚洲研究院共有22篇论文被录取,内容涵盖机器翻译、文本生成、机器阅读理解、事实检测、人机对话等领域。本文精选了6篇有代表性的论文为大家介绍。

端到端语音翻译的课程预训练
Curriculum Pre-training for End-to-End Speech Translation
链接:https://arxiv.org/abs/2004.10093
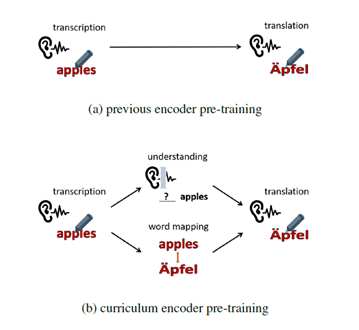
端到端语音翻译(Speech Translation, ST)利用一个神经网络模型将一段源语言语音直接翻译为目标语言的文本。这个任务对模型编码器带来很大负担,因为它需要同时学习语音转录(transcription)、语义理解(understanding)和跨语言语义匹配(mapping)。已有工作利用语音识别(Automatic Speech Recognition, ASR)数据上进行预训练以获得更强大的编码器。然而,这种预训练方式无法学习翻译任务所需要的语义知识。受到人类学习过程的启发,本文提出了一种课程预训练(Curriculum Pretraining)的方式。如图1所示,在学习语音翻译之前,模型首先学习一门基础课程用于语音转录,随后学习两门用于语义理解和单词映射的高级课程,这些课程的难度逐渐增加。
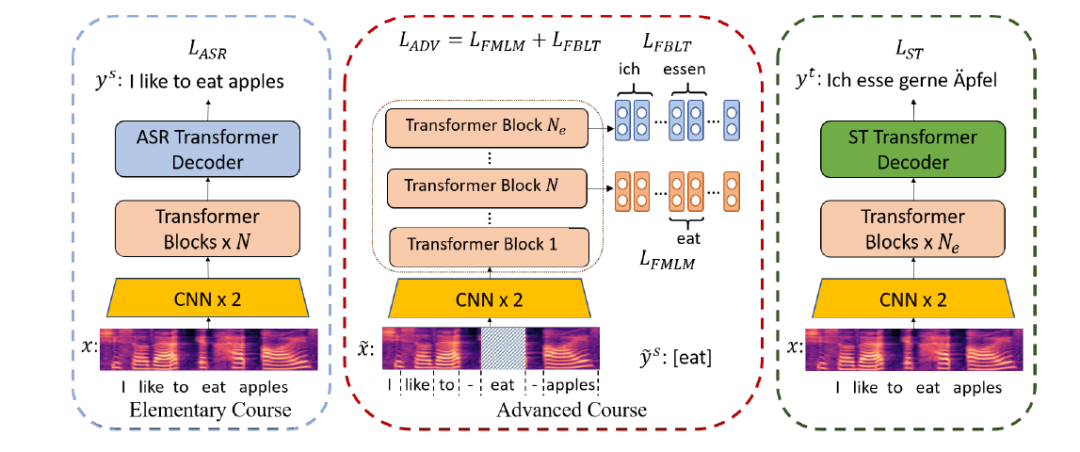
图2:训练过程
如图2所示,训练过程分为三个阶段:首先利用语音识别任务作为基础课程;然后在高级课程中,我们提出了两种任务,分别命名为 Frame-based Masked Language Model (FMLM) 和 Frame-based Bilingual Lexicon Translation (FBLT)。在 FMLM 任务中,首先将源语言语音和单词做对齐,然后随机遮蔽部分单词对应的语音片段,并令模型预测正确的单词。在 FBLT 任务中,我们使模型预测每个语音片段所对应的目标语言单词。这两个任务在编码器的不同层进行;最终,将模型在语音翻译数据上进行微调。实验表明,课程预训练的方法在英德和英法语音翻译数据集上都取得了明显改进。
SimulSpeech: 端到端同声传译系统
SimulSpeech: End-to-End Simultaneous Speech to Text Translation
链接:https://www.aclweb.org/anthology/2020.acl-main.350.pdf
同声传译是指在不打断讲话者的情况下,同步地将源语言的语音翻译成目标语言的文字或语音,这种翻译方式被广泛应用于大型国际会议等场景。随着机器翻译技术的发展,基于机器的同声传译准确率有了极大的提高,并逐渐投入到实际使用中。以往的多数研究专注于从源语言文字到目标语言文字的同声传译,这些方法需要结合实时的语音识别形成级联模型来完成翻译。这种级联模型的翻译流程比较复杂,而且语音识别的错误会传播到翻译模型里形成错误累积影响精度。
本文首次提出了直接从源语言语音翻译到目标语言文字的端到端同声传译系统 SimulSpeech。端到端的同声传译面临几下几点挑战:首先,与离散化的文字相比,语音是连续的信号,因此需要对语音做词边界的自动分割,从而判断何时对源语言语音片段进行翻译;其次,与理解源语言文字相比,模型理解源语言语音的难度更大。为了解决上述挑战,在模型层面上,为了构建语音到文字同声传译框架,SimulSpeech 引入了基于 CTC 的实时分割方法和 wait-k 的策略;在方法层面上,为了降低理解源语言语音的难度,我们引入了知识蒸馏和注意力蒸馏。
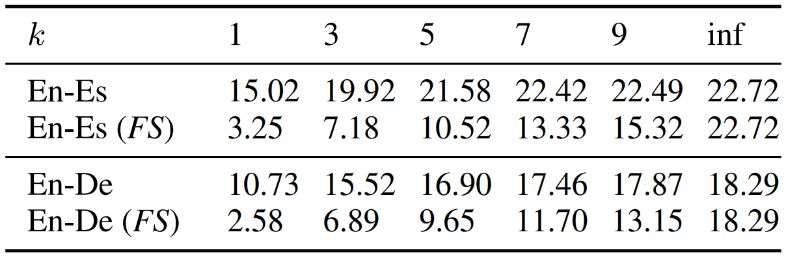
表1:SimulSpeech 在不同 k 下的 BLEU 分数比较。FS 代表使用整句训练(即不使用 wait-k 策略)的模型
在 MuST-C 英-西、英-德语音翻译数据集上的实验表明(如表1),SimulSpeech 在较小的 k 下(k 越小,同声传译的时延越低)也能取得比较好的翻译精度,当 k 逐渐增大时,SimulSpeech 的翻译精度接近非同声传译的翻译精度。我们也将SimulSpeech 同传统的级联模型进行比较(如表2和图3),可以看到在实时性要求比较高的条件下(k 较小),在相同的 k 下,SimulSpeech 方法比级联模型精度更高(表2);在相同的翻译精度下,SimulSpeech 方法比级联模型时延更小(图3),显示了我们的方法在语音到文字同声传译任务中的有效性。
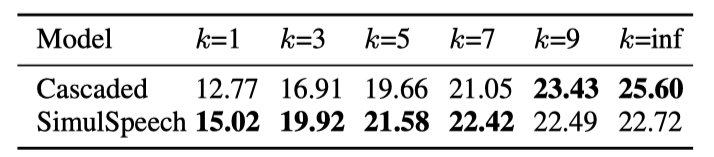
表2:SimulSpeech 同两阶段级联模型的 BLEU 分数比较
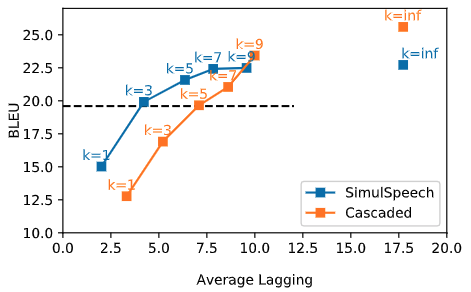
图3:SimulSpeech 同两阶段级联模型的平均延迟比较
基于量子变分自编码器的面向证据的推理文本生成
Evidence-Aware Inferential Text Generation with Vector Quantised Variational AutoEncoder
链接:https://arxiv.org/abs/2006.08101
推理文本生成旨在理解日常事件并推断事件本身相关的常识性知识,如事件发生的原因、参与者的意图和情绪等。常识性推理的能力在多种 NLP 任务中具有重要的意义,如在文本生成中,能够理解事件之间的因果关系,从而生成合理的文本;在智能对话中,可以通过对话内容来推理出用户的意图和情感,有效地提高对话质量。
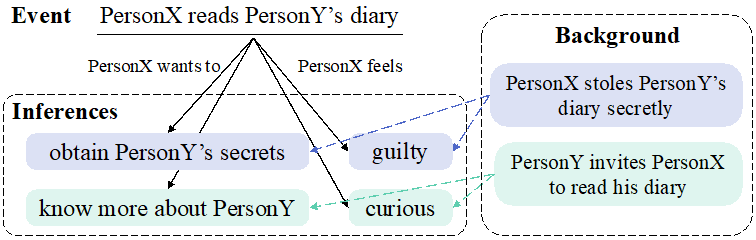
图4:推理文本生成示例
上图给出了该任务的一个具体例子,给定一个事件,该任务主要生成合理的推理文本,如事件的原因和结果等知识。从上述的例子可以看出,对于同一事件,在不同的背景下,参与者心理的状态也是不一样的。因此,背景知识在该任务中提供了重要的线索,可以帮助我们推断出合理的文本并且能够在不同背景知识下从多个角度进行推理,但值得注意的是在当前的数据集中背景知识并不存在。
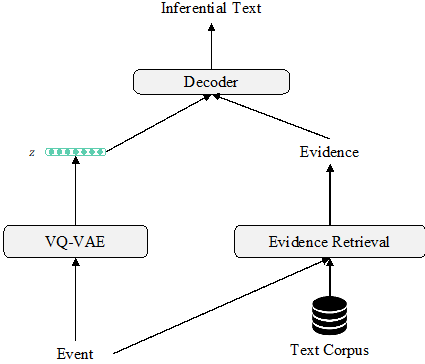
图5:EA-VQ-VAE 整体框架
在本文中,我们提出了一种面向证据的推理文本生成的方法(EA-VQ-VAE),从语料库中自动寻找有用的背景知识,用来帮助模型的生成。整体框架上图所示。给定一个事件 Event,首先通过量子变分自编码器(VQ-VAE)得到具有语义信息的离散潜变量 z,然后从一个大规模的语料库中寻找包含事件和该事件上下文的证据。最后解码器利用具有该事件语义信息的潜变量 z 选择语义相关的证据作为背景知识,从而指导推理文本的生成。
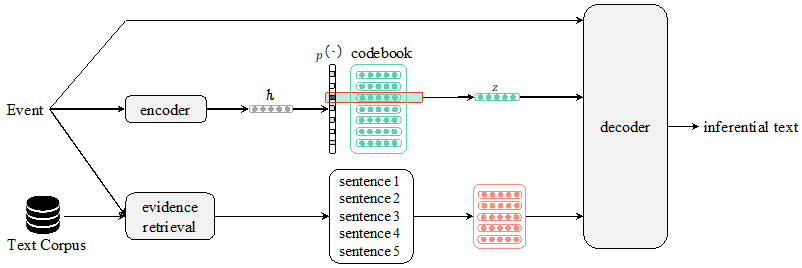
图6:EA-VQ-VAE 模型结构
上图是 EA-VQ-VAE 模型的结构,该模型是一个建立在量子变分自编码器(VQ-VAE)框架下的编码-解码(encoder-decoder)模型,该模型主要分为三个部分:第一部分是 VQ-VAE,首先通过编码器将事件编码成隐变量 h,然后在 codebook 中根据先验分布 p(z|x) 得到潜变量 z,该潜变量通过训练 VQ-VAE 可以获得推理文本的语义信息,该语义信息将被用来选择相关语义的证据并将其作为背景知识;第二部分是检索证据,我们使用 Elastic Search 工具搜索包含该事件及其上下文的前 k 个证据 C={c_1,c_2…,c_k},并通过两层的 transformer 编码成隐变量 H_C={h_c1,h_c2…,h_ck};最后根据上下文概率分布 p(c_k |z) 获得语义相关的上下文 c 作为背景知识,然后将上下文 c 和事件 x 拼接起来通过解码器生成文本,该论文使用了预训练好的 GPT2 作为解码器。
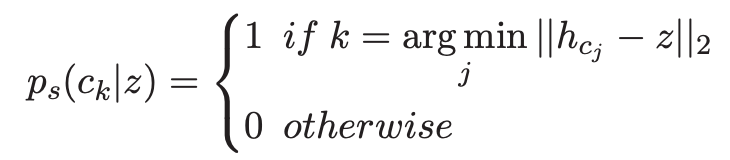
该论文在 ATOMIC 和 Event2Mind 数据集中进行实验,在自动评测和人工评测中,均取得了最好的成绩。
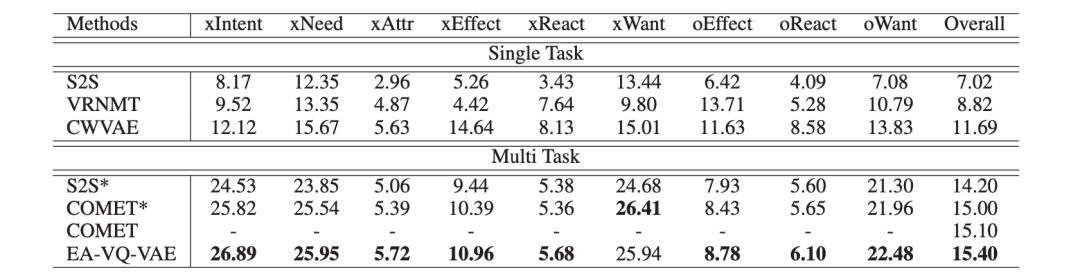
表3:在 ATOMIC 数据集上的实验结果
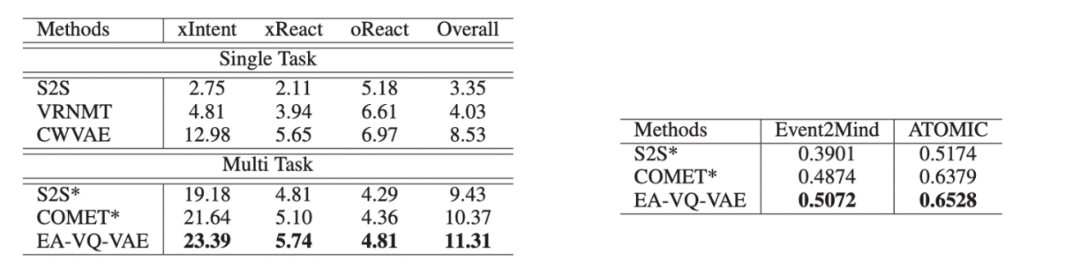
表4:在 Event2Mind 数据集上的实验结果
通过样例分析可以看出,该模型能够描述推理的过程。如下图所示,给定一个事件 “PersonX 离开家”,该模型首先通过 VQ-VAE 得到两个潜变量 z_29 和 z_125。然后通过在同一潜变量赋值下的文本进行词云化能够可视化潜变量的语义。可以看出 z_29 捕捉到积极的语义,如 “play” 和 “friend”。最后根据该语义找到相近的上下文,从而指导文本生成。
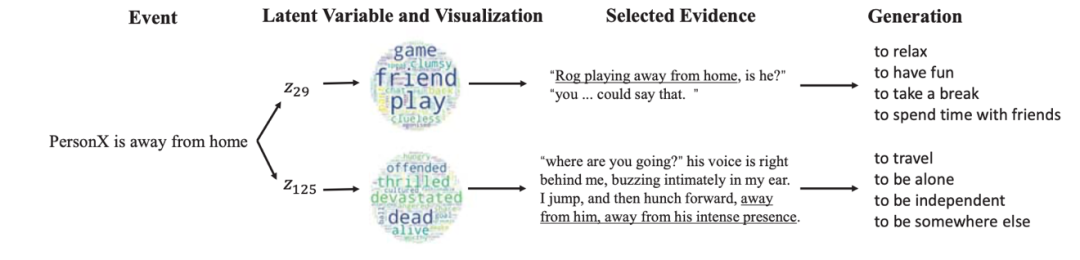
图7:EA-VQ-VAE 样例分析
LogicalFactChecker:利用图模块化网络建模逻辑操作的事实检测
LogicalFactChecker: Leveraging Logical Operations for Fact Checking with Graph Module Network
链接:https://arxiv.org/abs/2004.13659
社交网络的发展使得信息的高效分享成为了可能,但也为虚假信息的恶意传播提供了机会。随着机器生成模型的蓬勃发展,这个情况也变得愈发恶劣。网络上的虚假信息可能会影响人们对于重要社会事件的看法并造成很多负面影响,包括影响政治选举等。因此,自动识别网络上的虚假信息有至关重要的社会意义。
根据 Waheeb et al. [https://dl.acm.org/doi/fullHtml/10.1145/3313831.3376213] ,事实检测(fact checking)是网络虚假信息监测的相关技术中最为有效的。我们此次在 ACL 上发表了两篇关于事实检测的文章,其中一篇关注于非结构化文本的事实检测任务的论文在此前文章中已做过介绍。本篇论文主要关注基于结构化数据的事实检测。
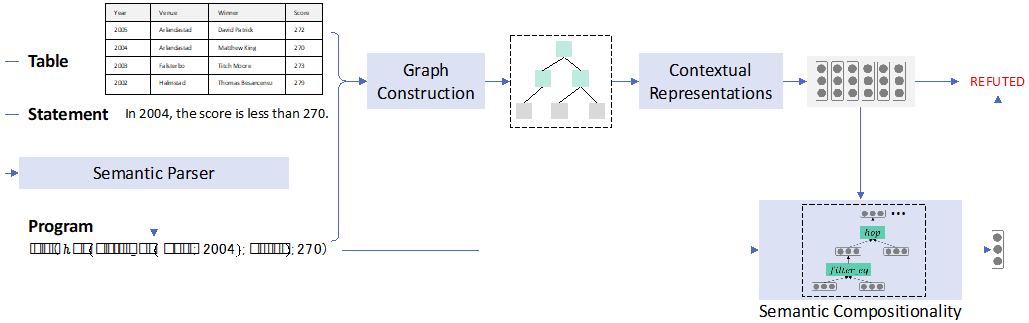
图8:Logical Fact Checker 步骤
我们提出了一个在神经网络中建模逻辑操作的方法: Logical Fact Checker,方法主要分为四个步骤。首先,给定一个表格和声明,使用语义解析器(Semantic Parser)去生成一个可在表格上执行的程序,该程序由预先定义好的逻辑操作组成。下图给出一个程序生成的例子。
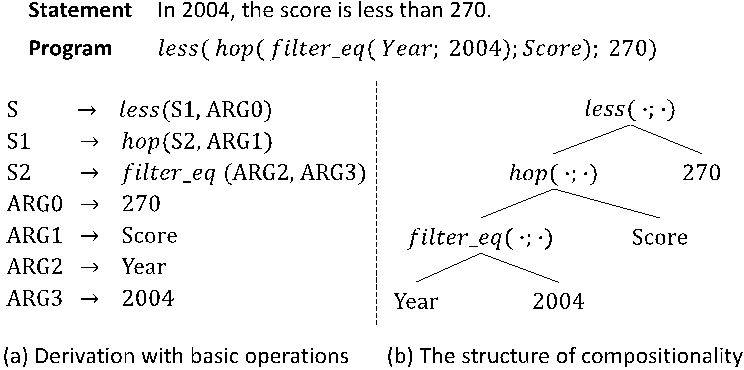
图9:程序生成示例
接下来,为了表示声明、表格以及生成程序之间的语义结构化关系,我们构建了一个图。节点来自于声明中的实体,表格中的行列和内容,还有程序中的参数。边指代了含义相同的节点之间的联系。
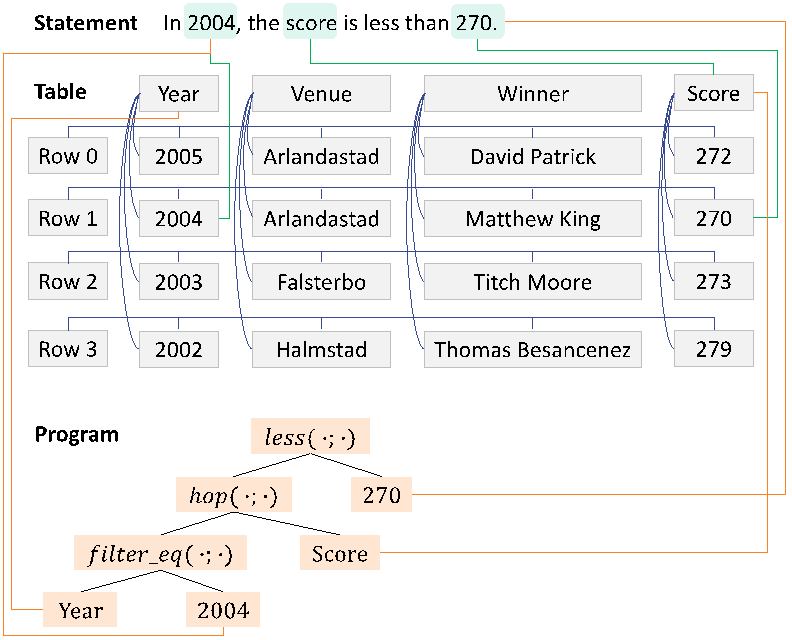
图10:声明、表格以及生成程序之间的语义结构化关系示意图
根据构建的图,我们定义了基于图的注意力机制矩阵(attention mask metric)。矩阵中的每一行代表和当前词汇相关内容的位置(如临近的内容和相关的节点)。矩阵被用于 BERT 编码器的自注意力机制中(self-attention mechanism),以学习图增强的词汇表示(Contextual Representation)。
之后,我们通过图模块化网络(Graph Module Network)去学习基于逻辑操作的语义组合性。
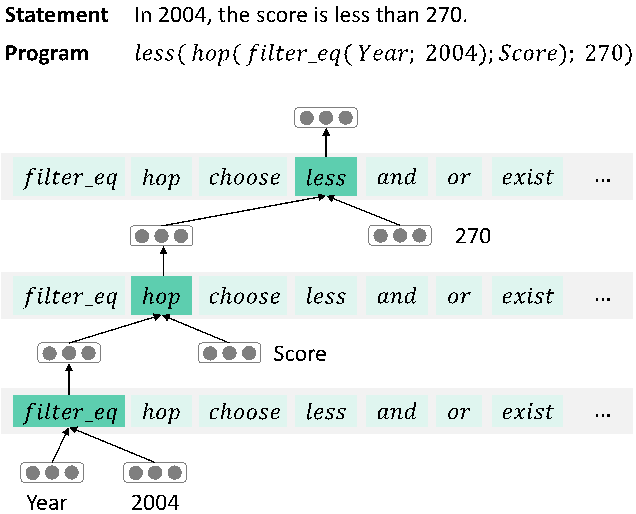
图11:图模块化网络的推理过程
上图展示了图模块化网络的推理过程。每一个逻辑操作都对应网络中一个有独立参数的模块。我们用词向量表示去初始化逻辑操作的参数表示,然后根据程序的结构自底向上地使用图模块网络进行动态的语义组合以获得更高层级的表示。然后使用最终生成的表示来预测事实真假性。
论文在基于表格的事实检测的代表性数据集 TABFACT 上进行实验。可以看出,该方法超越了基于文本匹配的模型 Table-BERT, 也超过了基于语义解析的模型 LPA,并取得了最好的性能。
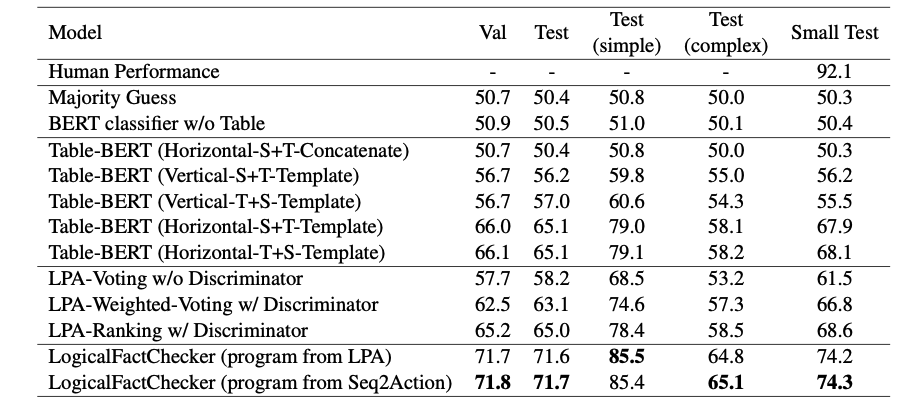
表5:在数据集 TABFACT 上实验的结果
消融实验也证明了图增强词汇表示学习模块和基于逻辑操作的语义组合模块都为模型带来了性能提升。
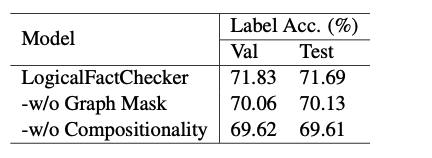
表6:消融实验
下图的样例分析展现了我们的系统(1)能找到声明和逻辑操作之间的对应关系(比如 “most points” 对 “argmax”)(2)能抽取出正确的程序,并且利用程序的语义组合性对声明的真假性作出正确的预测。

图12:样例分析
RikiNet: 阅读维基百科页面进行自然问答
RikiNet: Reading Wikipedia Pages for Natural Question Answering
链接:https://arxiv.org/abs/2004.14560
阅读长文档进行开放域问题回答是自然语言理解领域的一个挑战。针对 Google 的 Natural Question 任务,本文提出了一个新的模型 RikiNet(意为 Reading Wikipedia 的神经网络模型),阅读维基百科的整个页面进行自然问答。RikiNet 的单模型首次在 Natural Question 上双指标超过单人类,其集成模型提交时在 Natural Question Leaderboard 取得了双指标第一名。
随着机器阅读理解模型和问答模型的发展,越来越多的模型性能在多个数据集上超过了人类。Google Natural Question(NQ)于19年被提出,为开放域问答提出了新的挑战。如图13所示,该任务给定一个用户在 Google 搜索引擎中输入的自然问题,以及与该问题最匹配的维基百科页面,要求模型预测出回答该问题的长答案(即该页面中的某一个段落)和短答案(即某一个 answer span),以及是否存在长答案或短答案。
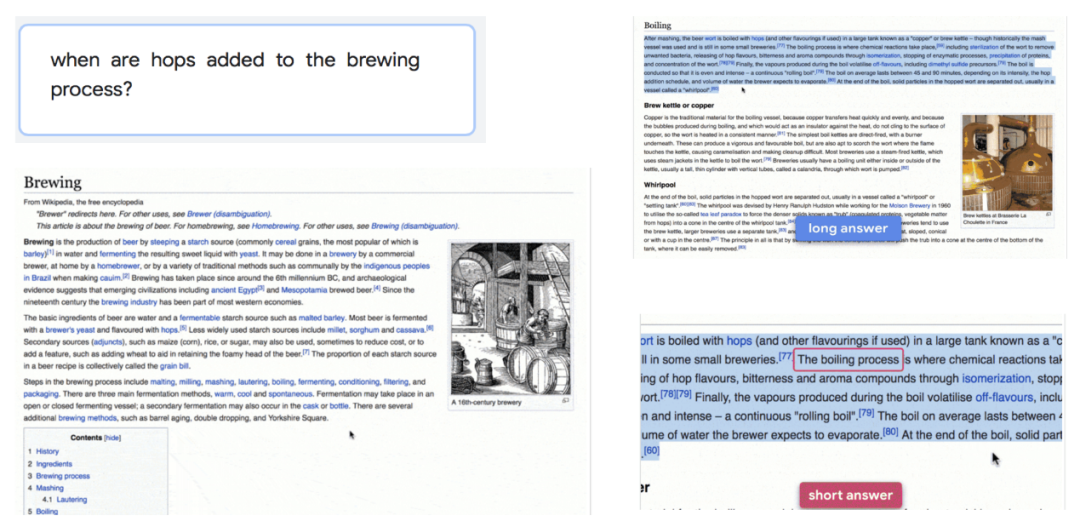
图13:Google Natural Question
如图14所示,RikiNet 模型由两部分组成:(1)动态的段落双重注意力阅读器(Dynamic Paragraph Dual-attention Reader, DPDA reader),通过利用一系列互补的注意力机制和预训练语言模型对文档和问句进行编码,以得到上下文相关的问句表示,token-level 和 paragraph-level 的文档表示;(2)多层级的级联答案预测器(Multi-level Cascaded Answer Predictor,MCAP),利用 DPDR 输出的多层级表示,以级联的结构依次预测长答案、短答案和答案类型。
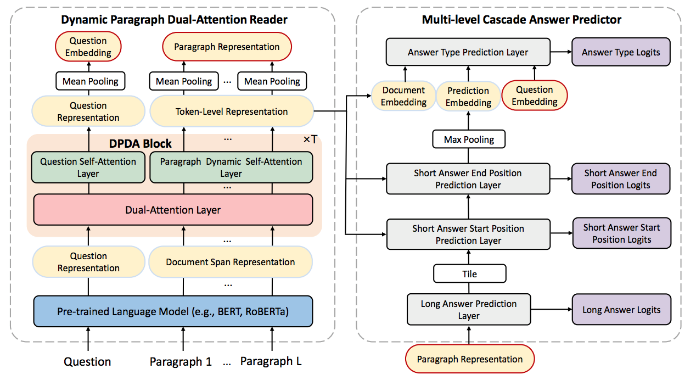
图14:RikiNet 模型构成
具体来说,DPDA reader 首先使用预训练语言模型获得问句和文档的上下文表示,再通过多层 DPDA Block 对问句和文档进一步建模。每一个 DPDA Block 分别对问句进行自注意力机制建模,对文档进行段落动态自注意力机制建模。其中,段落动态自注意力机制由两个自注意力掩码矩阵叠加组成:a. 段落掩码,使得当前 token 只与相同段落的 token 执行注意力交互,以生成段落级别的表示;b.动态掩码,由掩码预测器动态产生掩码矩阵,使自注意力机制更关注于重要的信息。在得到词级别的表示后,我们将位于相同段落的 token 通过池化操作得到相应的段落表示,并通过池化操作得到问句表示、文档表示。
上述多层级的表示将通过 MCAP 以级联的方式依次预测长答案、短答案的起始位置、结束位置和答案类型,该级联的方式能够充分利用不同答案的预测信息,以完成 NQ 任务的多个目标。
我们将基于 BERT 和 RoBERTa 的 RikiNet 模型与之前的模型进行比较,包括 IBM AI,Google AI 在 NQ 任务上提出的模型。如表7所示,我们的单模型首次在长答案(LA)和短答案(SA)的 F1 分数上超过单人类,并且集成模型在提交时取得了 NQ leaderboard 双指标第一名。
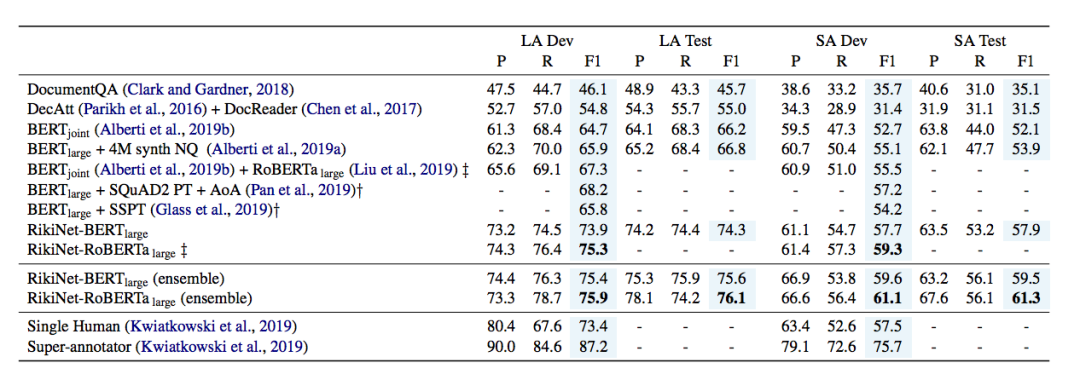
表7:NQ 数据集模型结果
我们进一步对模型进行 ablation study。首先在保留 BERT 的情况下对 DPDA reader 进行分析和实验,包括去除相应的注意力机制、block 层数、动态注意力词数,结果如表8左所示。同时我们也对 MCAP 进行了进一步的消融实验,并比较了不同的预测层和级联顺序,结果如表8右所示。
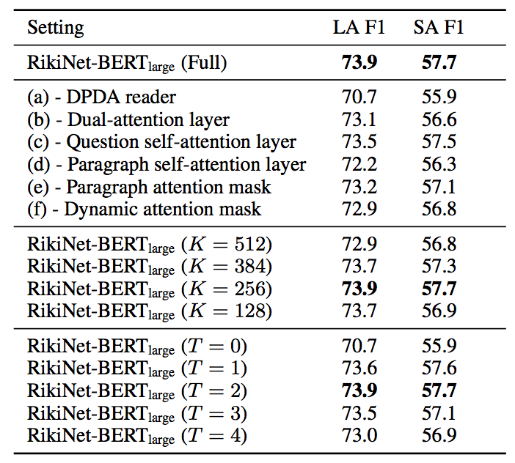
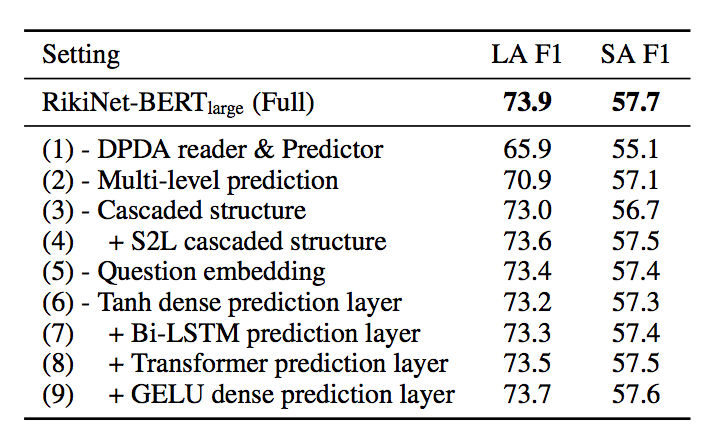
表8:消融实验结果
基于相互个性感知的对话生成
You Impress Me: Dialogue Generation via Mutual Persona Perception
链接:https://arxiv.org/abs/2004.05388
个性化对话生成(Personalized Dialogue Generation)是对话生成领域近几年的一个研究热点(Zhang et al. 2018)。一般来讲,个性的引入可以帮助对话生成模型产生更一致的、更有趣的回复。然而大部分已有工作仍像对待普通开放域对话生成那样,关注模型生成回复的流畅性,较少关注对话中对话者之间的互动和了解。相比于已有工作,我们显式地建模了对话者之间的了解,从而使得对话生成的结果更加有趣,且更加符合对话者的个性。
这篇论文提出了一个 Transmitter-Receiver 的框架来显式建模对话者之间的了解,其中 Transmitter 负责对话生成,而 Receiver 负责个性了解。在这个框架下,我们引入一个新颖的概念“相互个性感知”,来刻画对话者之间的信息交流,即对话者对彼此个性的了解程度。众所周知,高效的沟通能够让对话的双方充分了解并达成共识,所以相互个性感知的提升在一定程度上也代表了对话质量的提高。为了达成这个目标,我们首先按照传统的监督学习来训练Transmitter,然后让两个训练好的 Transmitter 通过互相对话进行自我学习(self-play)。在它们对话若干轮后,借助 Receiver 提供的个性感知奖励微调 Transmitter。
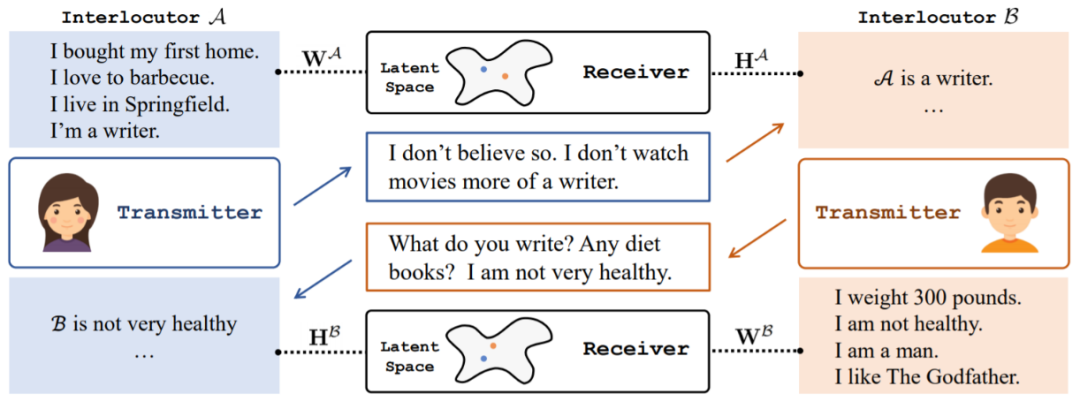
图15:Transmitter-Receiver 框架示意图
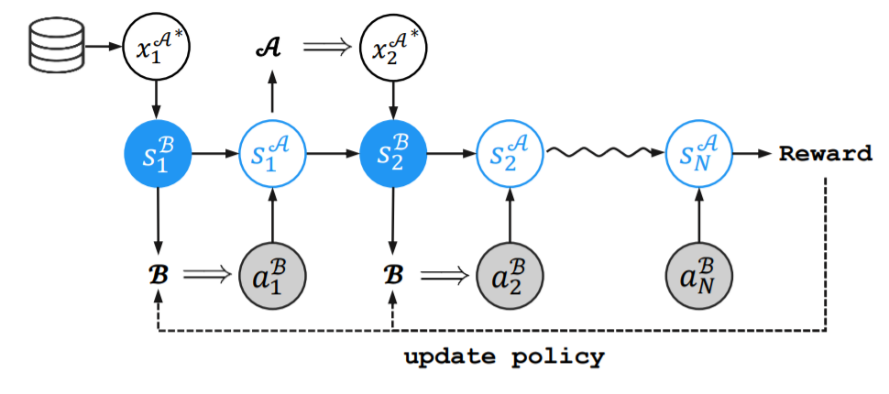
图16:自我学习(self-play)流程示意图
Transmitter 采用的是 GPT 架构(Radford et al. 2018),它以当前说话者的个性、整个对话的历史作为输入,逐步解码生成回复。Receiver 则被设计来准确衡量两个人的对话中有多少信息是与个性相关。然而,训练数据中并没有这样的监督信息,为此,我们采用对比学习范式来训练 Receiver。具体而言,每次随机采样一个干扰(distractor)个性,Receiver 需要学习到当前对话与干扰项的关联度远低于与当前个性的关联度。
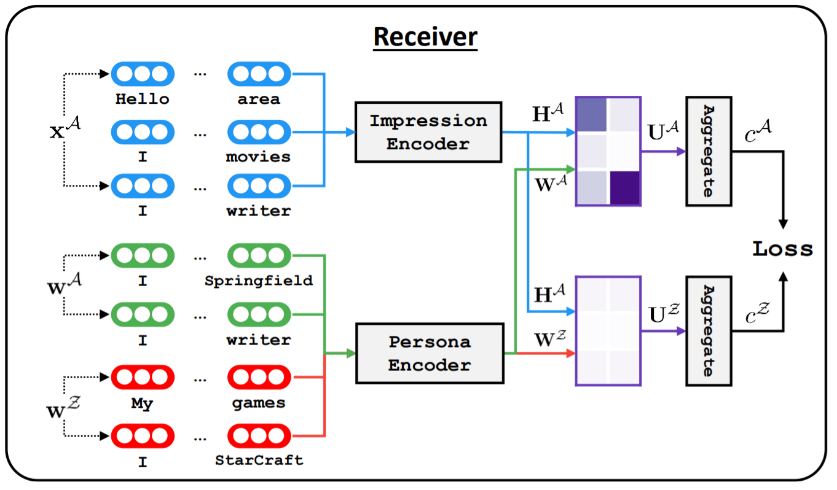
图17:对比学习训练 Receiver
在个性化对话生成数据集 Persona-Chat 上,我们的模型在 PPL(困惑度)和 F1 指标中都取得了比基线模型更好的结果,在后续的人工评测中也取得了最好的效果。值得注意的是,Lost in Conversation 和 Transfertransfo 也是基于 GPT 来生成对话,它们与我们模型的区别在于它们没有引入相互个性感知。
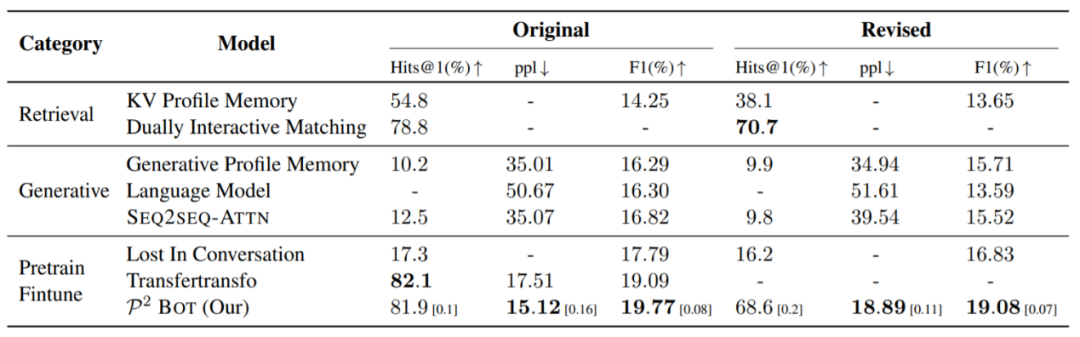
表9:不同模型在 Persona-Chat 数据集上的自动评测结果
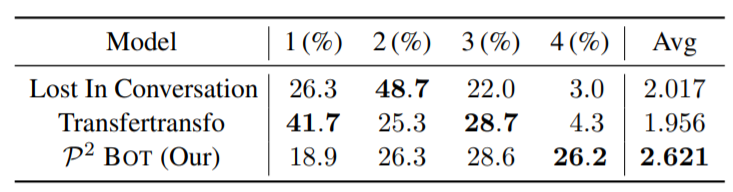
表10:不同模型的人工评测结果
时间
7月10日(星期五)下午13:30-16:50
报名方式
扫码进入大会报名主页面 > WAIC 云端峰会注册

你也许还想看: