华为云刷新深度学习加速纪录:128块GPU,10分钟训练完ImageNet
点击上方“公众号”可以订阅哦!
深圳市未来产业促进会副会长单位:华为技术有限公司
来源:dawn.cs.stanford.edu
来源:dawn.cs.stanford.edu
编辑:文强
【导读】华为云ModelArts在国际权威的深度学习模型基准测试平台斯坦福DAWNBenchmark上取得了当前图像识别训练时间最佳成绩,ResNet-50在ImageNet数据集上收敛仅用10分28秒,比第二名成绩提升近44%。华为自研了分布式通用加速框架MoXing,在应用层和TensorFlow、MXNet、PyTorch等框架之间实现再优化。ModelArts公测地址:https://www.huaweicloud.com/product/modelarts.html
日前,斯坦福大学发布了DAWNBenchmark最新成绩,在图像识别(ResNet50-on-ImageNet,93%以上精度)的总训练时间上,华为云ModelArts排名第一,仅需10分28秒,比第二名提升近44%。
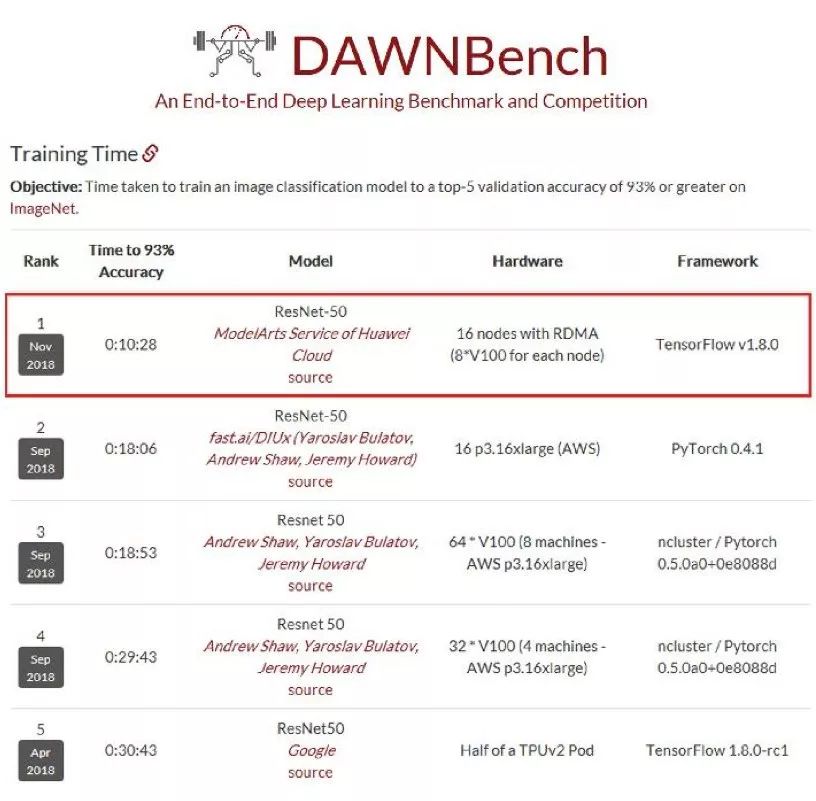
斯坦福大学DAWNBenchmark图像识别训练时间最新成绩,华为云ModelArts以10分28秒排名第一,超越了fast.ai、谷歌等劲敌。来源:dawn.cs.stanford.edu/benchmark/
作为人工智能最重要的基础技术之一,近年来深度学习逐步延伸到更多的应用场景。除了精度,训练时间和成本也是构建深度学习模型时需要考虑的核心要素。然而,当前的深度学习基准往往以衡量精度为主,斯坦福大学DAWNBench正是在此背景下提出。
斯坦福DAWNBench是衡量端到端深度学习模型训练和推理性能的国际权威基准测试平台,提供了一套通用的深度学习评价指标,用于评估不同优化策略、模型架构、软件框架、云和硬件上的训练时间、训练成本、推理延迟以及推理成本,吸引了谷歌、亚马逊AWS、fast.ai等高水平队伍参与,相应的排名反映了当前全球业界深度学习平台技术的领先性。
正是在这样高手云集的基准测试中,华为云ModelArts第一次参加国际排名,便实现了更低成本、更快速度的体验。
为了达到更高的精度,通常深度学习所需数据量和模型都很大,训练非常耗时。例如,在计算机视觉领域常用的经典ImageNet数据集(1000个类别,共128万张图片)上,用1块P100 GPU训练一个ResNet-50模型, 耗时需要将近1周。这严重阻碍了深度学习应用的开发进度。因此,深度学习训练加速一直是学术界和工业界所关注的重要问题,也是深度学习应用的主要痛点。
曾任Kaggle总裁和首席科学家的澳大利亚数据科学家和企业家Jeremy Howard,与其他几位教授共同组建了AI初创公司fast.ai,专注于深度学习加速。他们用128块V100 GPU,在上述ImageNet数据集上训练ResNet-50模型,最短时间为18分钟。
最近BigGAN、NASNet、BERT等模型的出现,预示着训练更好精度的模型需要更强大的计算资源。可以预见,在未来随着模型的增大、数据量的增加,深度学习训练加速将变得会更加重要。
只有拥有端到端全栈的优化能力,才能使得深度学习的训练性能做到极致。
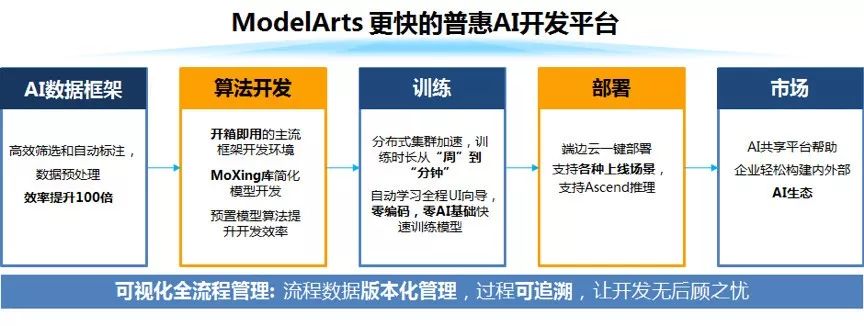
华为云ModelArts功能视图
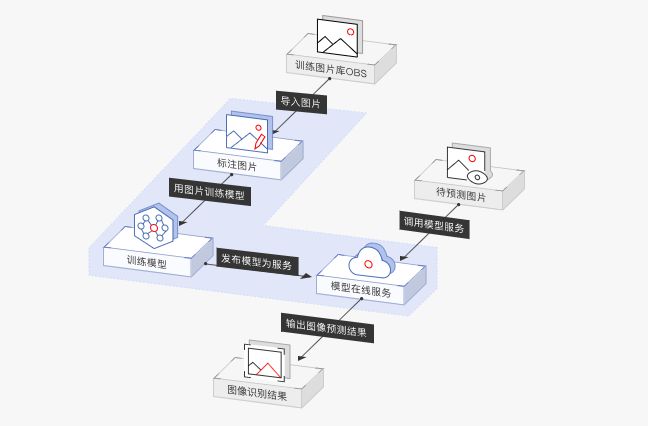
华为云ModelArts是一站式的AI开发平台,已经服务于华为公司内部各大产品线的AI模型开发,几年下来已经积累了跨场景、软硬协同、端云一体等多方位的优化经验。
ModelArts提供了自动学习、数据管理、开发管理、训练管理、模型管理、推理服务管理、市场等多个模块化的服务,使得不同层级的用户都能够很快地开发出自己的AI模型。
为什么ModelArts能在图像识别的训练时间上取得如此优异的成绩?
答案是“MoXing”。
在模型训练部分,ModelArts通过硬件、软件和算法协同优化来实现训练加速。尤其在深度学习模型训练方面,华为将分布式加速层抽象出来,形成一套通用框架——MoXing(“模型”的拼音,意味着一切优化都围绕模型展开)。
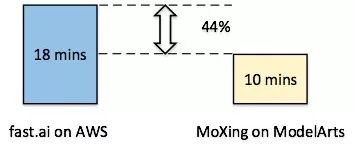
采用与fast.ai一样的硬件、模型和训练数据,ModelArts可将训练时长可缩短到10分钟,创造了新的纪录,为用户节省44%的时间
MoXing是华为云ModelArts团队自研的分布式训练加速框架,它构建于开源的深度学习引擎TensorFlow、MXNet、PyTorch、Keras之上,使得这些计算引擎分布式性能更高,同时易用性更好。
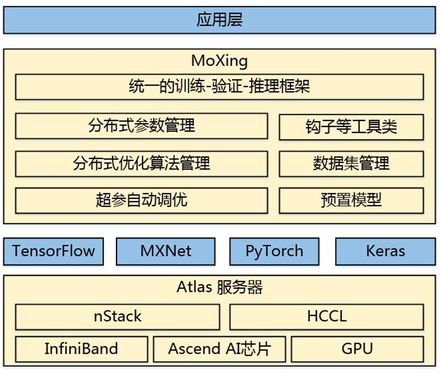
华为云MoXing架构图
MoXing内置了多种模型参数切分和聚合策略、分布式SGD优化算法、级联式混合并行技术、超参数自动调优算法,并且在分布式训练数据切分策略、数据读取和预处理、分布式通信等多个方面做了优化,结合华为云Atlas高性能服务器,实现了硬件、软件和算法协同优化的分布式深度学习加速。
有了MoXing后,上层开发者可以聚焦业务模型,无需关注下层分布式相关的API,只用根据实际业务定义输入数据、模型以及相应的优化器即可,训练脚本与运行环境(单机或者分布式)无关,上层业务代码和分布式训练引擎可以做到完全解耦。
深度学习加速属于一个从底层硬件到上层计算引擎、再到更上层的分布式训练框架及其优化算法多方面协同优化的结果,具备全栈优化能力才能将用户训练成本降到最低。
在模型训练这方面,华为云ModelArts内置的MoXing框架使得深度学习模型训练速度有了很大的提升。
下图是华为云团队测试的模型收敛曲线(128块V100 GPU,完成ResNet50-on-ImageNet)。一般在ImageNet数据集上训练ResNet-50模型,当Top-5精度≥93%或者Top-1 精度≥75%时,即可认为模型收敛。
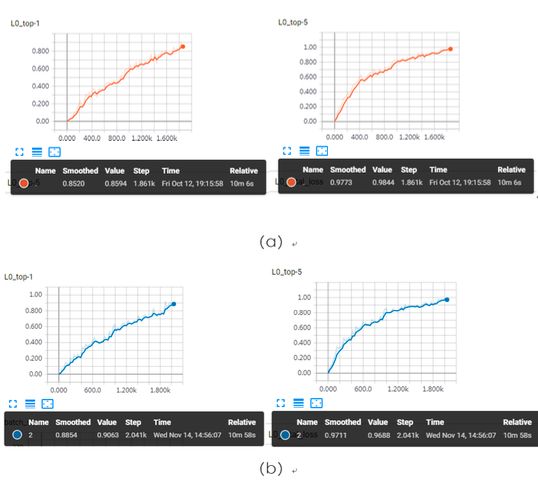
ResNet50-on-ImageNet训练收敛曲线(曲线上的精度为训练集上的精度):(a)所对应的模型在验证集上Top-1 精度≥75%,训练耗时为10分06秒;(b) 所对应的模型在验证集上Top-5精度≥93%,训练耗时为10分28秒。
Top-1和Top-5精度为训练集上的精度,为了达到极致的训练速度,训练过程中采用了额外进程对模型进行验证,最终验证精度如下表所示(包含与fast.ai的对比)。
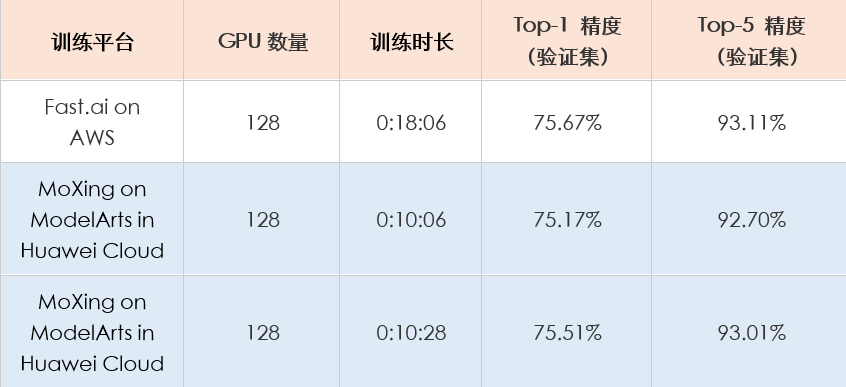
MoXing与fast.ai的训练结果对比
华为云团队介绍,衡量分布式深度学习框架加速性能时,主要看吞吐量和收敛时间。在与吞吐量和收敛时间相关的几个关键指标上,团队都做了精心处理:
在数据读取和预处理方面,MoXing通过利用多级并发输入流水线使得数据IO不会成为瓶颈;
在模型计算方面,MoXing对上层模型提供半精度和单精度组成的混合精度计算,通过自适应的尺度缩放减小由于精度计算带来的损失;
在超参调优方面,采用动态超参策略(如momentum、batch size等)使得模型收敛所需epoch个数降到最低;
在底层优化方面,MoXing与底层华为自研服务器和通信计算库相结合,使得分布式加速进一步提升
后续,华为云ModelArts将进一步整合软硬一体化的优势,提供从芯片(Ascend)、服务器(Atlas Server)、计算通信库(CANN)到深度学习引擎(MindSpore)和分布式优化框架(MoXing)全栈优化的深度学习训练平台。
ModelArts会逐步集成更多的数据标注工具,扩大应用范围,将继续服务于智慧城市、智能制造、自动驾驶及其它新兴业务场景,在公有云上为用户提供更普惠的AI服务。
注:投稿请电邮至124239956@qq.com ,合作 或 加入未来产业促进会请加:www13923462501 微信号或者扫描下面二维码:

文章版权归原作者所有。如涉及作品版权问题,请与我们联系,我们将删除内容或协商版权问题!联系QQ:124239956




