资源 | 带自注意力机制的生成对抗网络,实现效果怎样?
选自GitHub
机器之心编译
参与:杨洁湫、李亚洲
在前一段时间,Han Zhang 和 Goodfellow 等研究者提出添加了自注意力机制的生成对抗网络,这种网络可使用全局特征线索来生成高分辨率细节。本文介绍了自注意力生成对抗网络的 PyTorch 实现,读者也可以尝试这一新型生成对抗网络。
项目地址:https://github.com/heykeetae/Self-Attention-GAN
这个资源库提供了一个使用 PyTorch 实现的 SAGAN。其中作者准备了 wgan-gp 和 wgan-hinge 损失函数,但注意 wgan-gp 有时与谱归一化(spectral normalization)是不匹配的;因此,作者会移除模型所有的谱归一化来适应 wgan-gp。
在这个实现中,自注意机制会应用到生成器和鉴别器的两个网络层。像素级的自注意力会增加 GPU 资源的调度成本,且每个像素有不同的注意力掩码。Titan X GPU 大概可选择的批量大小为 8,你可能需要减少自注意力模块的数量来减少内存消耗。
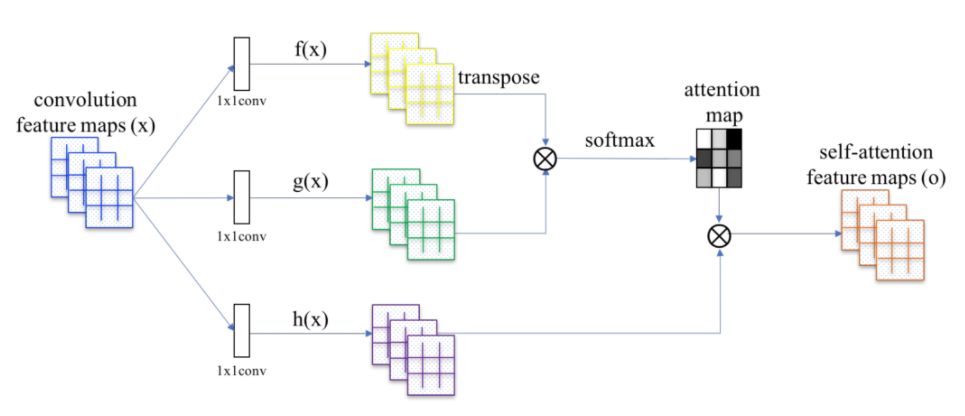
目前更新状态:
注意力可视化 (LSUN Church-outdoor)
无监督设置(现未使用标签)
已应用:Spectral Normalization(代码来自 https://github.com/christiancosgrove/pytorch-spectral-normalization-gan)
已实现:自注意力模块(self-attention module)、两时间尺度更新规则(TTUR)、wgan-hinge 损失函数和 wgan-gp 损失函数
结果
下图展示了 LSUN 中的注意力结果 (epoch #8):

SAGAN 在 LSUN church-outdoor 数据集上的逐像素注意力结果。这表示自注意力模块的无监督训练依然有效,即使注意力图本身并不具有可解释性。更好的图片生成结果以后会添加,上面这些是在生成器第层 3 和层 4 中的自注意力的可视化,它们的尺寸依次是 16 x 16 和 32 x 32,每一张都包含 64 张注意力图的可视化。要可视化逐像素注意力机制,我们只能如左右两边的数字显示选择一部分像素。
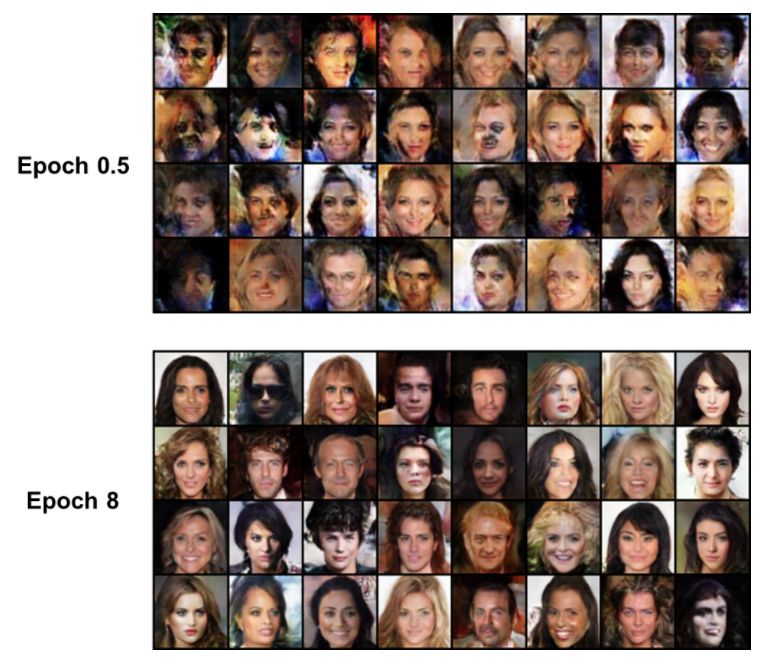
CelebA 数据集 (epoch on the left, 还在训练中):
LSUN church-outdoor 数据集 (epoch on the left, 还在训练中):

训练环境:
Python 3.5+ (https://www.continuum.io/downloads)
PyTorch 0.3.0 (http://pytorch.org/)
用法
1. 克隆版本库
$ git clone https://github.com/heykeetae/Self-Attention-GAN.git
$ cd Self-Attention-GAN
2. 下载数据集 (CelebA 或 LSUN)
$ bash download.sh CelebA
or
$ bash download.sh LSUN
3. 训练
$ python python main.py --batch_size 6 --imsize 64 --dataset celeb --adv_loss hinge --version sagan_celeb
or
$ python python main.py --batch_size 6 --imsize 64 --dataset lsun --adv_loss hinge --version sagan_lsun
4. 享受结果吧~
$ cd samples/sagan_celeb
or
$ cd samples/sagan_lsun
每 100 次迭代生成一次样本,抽样率可根据参数 --sample_step (ex,—sample_step 100) 控制。
论文:Self-Attention Generative Adversarial Networks

论文地址:https://arxiv.org/abs/1805.08318
在此论文中,我们提出了自注意生成式对抗网络(SAGAN),能够为图像生成任务实现注意力驱动的、长范围的依存关系建模。传统的卷积 GAN 只根据低分辨特征图中的空间局部点生成高分辨率细节(detail)。在 SAGAN 中,可使用所有特征点的线索来生成高分辨率细节,而且鉴别器能检查图片相距较远部分的细微细节特征是否彼此一致。不仅如此,近期研究表明鉴别器调节可影响 GAN 的表现。根据这个观点,我们在 GAN 生成器中加入了谱归一化(spectral normalization),并发现这样可以提高训练动力学。我们所提出的 SAGAN 达到了当前最优水平,在极具挑战性的 ImageNet 数据集中将最好的 inception 分数记录从 36.8 提高到 52.52,并将 Frechet Inception 距离从 27.62 减少到 18.65。注意力层的可视化展现了生成器可利用其附近环境对物体形状做出反应,而不是直接使用固定形状的局部区域。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




