实录 | 英伟达自动驾驶中国区负责人董方亮:关于AI Car的思考
本文转载自公众号“汽车AI科技”(Auto_AI_Tech)
近日,由腾讯汽车主办的“源计划”媒体赋能学院第一期在北京举行。作为首批特邀五家媒体之一,量子位全程参与了“源计划”课程的打造与设计。

腾讯汽车主编陈瑶在现场表示,希望通过“源计划”实现连接与赋能,让看似微小的个体有效结合,实现能力叠加。同时实现自动驾驶厂商与媒体的联动,共同探讨自动驾驶未来的发展。

作为首期课程的受邀嘉宾,英伟达自动驾驶中国区负责人董方亮详解了英伟达在自动驾驶领域的布局与思考。董方亮表示,作为一家聚焦视觉领域的公司,英伟达从2016年开始公司的战略便开始向人工智能倾斜,而自动驾驶也是其中最重要的场景之一。
以下为董方亮现场分享实录:

英伟达是一个最早做传统的视觉计算的一家美国公司,我们这个公司的特点是公司非常专注,从最早做GPU开始一直专注在做视觉计算领域。随着时代的发展,在2006年我们的GPU应用于加速计算,这是一个崭新的领域,针对不同的视觉计算的市场是一个崭新的领域。在2016年英伟达顺应了AI时代的发展,我们整个的处理器、公司的平台向AI去倾斜,所以现在英伟达不光是一家视觉计算的公司,其实是一家AI计算的公司。(关于英伟达的转型,我们曾有过报道:历史转折中的英伟达:百亿豪赌出奇迹 实习生项目救主)
从这个图可以简单看一下公司的发展,从最早的游戏卡到专业GPU加速到后面的AI计算,这个图简单讲了英伟达的发展过程,也说明了我们公司现在是站在了AI计算比较有力的位置。

我们可以对自动驾驶有一个简单概念。自动驾驶时代到来的需求是什么?通过现在的交通状况,我们可以看到自动驾驶可以应用在乘用车和商用车。
因为现在的交通路况包括对人的伤害、交通死亡率,如果自动驾驶时代能够到来的话,第一是提高了安全性、保护了人类的生命,第二是因为自动驾驶能够提高整个车的利用率,第三是自动驾驶时代又能够开发不一样的人类生活方式,这是我们觉得自动驾驶时代给全人类带来的不一样的地方。
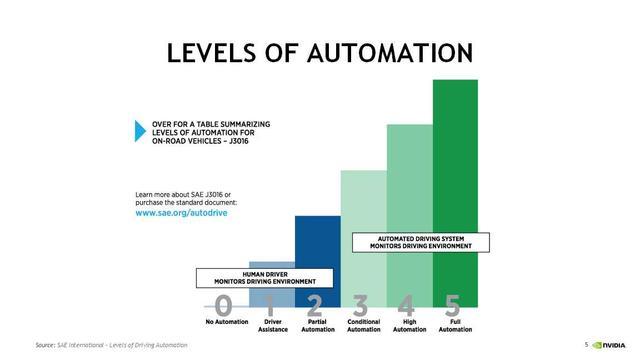
既然讲到自动驾驶,我们有一个简单的概念,就是自动驾驶的等级。SAE有五个等级,从2级以下主要指的还是ADAS,也就是辅助驾驶的市场。从3级是真正开始自动驾驶的市场,当然这是人还在坐在驾驶的位置,然后车去驾驶。
3级主要还是特定的路段,比如特定的告诉或者停车场去自动泊车的一种应用场景。包括一些特殊场景的园区车、物流车,这个是可以算到3级自动驾驶。到4级和5级以后又有了比较明显的区别,第一是4级以后要求的是其实是不需要方向盘的,也就是由车载的计算系统和车载系统去直接做接管,这样就带来了两个问题,人是否能信任车载自己去驾驶的系统,第二个问题是车载系统需要非常高的驾驶能力,能够真正代替人,然后安全性、可靠性也得到保障,3级、4级、5级需要做大量的工作。
我们谈到了识别就要谈到算法,传统的算法是用已有的几何学和数学的公式不断地计算特征,不断地计算物体的特征。这样的问题在哪里呢?
第一,编程的水平要非常高,因为你也要用算法去实现已有的数学理论的功能。
第二,世界是千变万化的,很难用一个算法去识别,比如说识别一把椅子。人看一眼知道是沙发,但是是不是上面一个半圆下面是平的就是沙发呢?不一定。你用算法去表达识别是非常困难的。如果用真正写算法的方式,相当于要去做穷举,可能要在算法里面写一千个沙发的特征,你才知道什么是沙发,否则的话你就是出错。
在识别的领域有没有更好的方法?比较幸运的是今天因为深度学习技术的到来,所以我们发现深度学习去做识别的时候效率很高,只要你有很多有效的数据去做训练,训练的网络很好,这样就可以达到非常好的识别效果。这种识别其实是科研界一直在去做的,其实在2012年以后应用GPU去做大量的深度学习的计算,很多是在做这种识别,也就是监督是网络训练。起码自动驾驶的第一步识别是有比较好的方法,这个是用深度神经网络去做识别。
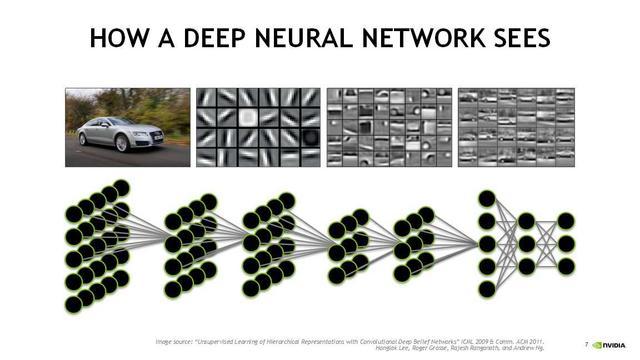
这一页是神经网络大概的原理,一个神经网络去做识别的时候是怎么样做到的。底下是所谓的神经网络,神经网络的理论性概念其实是科学家去提出觉得人脑的神经原和神经原之间的反射弧的连接,我们就认为一个计算节点是一个神经原,神经原和神经原是通过反射弧去做连接。这是科学家对人脑假说式的方式,很幸运的是这种假说在今天识别的领域是非常成功,无论人脑是否真正按照这种方式去做,基于深度神经网络识别的模式和方法被证明非常高效和可靠。
上面神经网络原理这个图是讲通过一个神经网络怎么样训练去做照片的识别,其实如果没有学的话,有的时候看起来不知道这个图在表达什么。神经网络不断层数增加的时候,其实是用前面的前层网络抓的是边角小的特征点,后面的网络跟前面的网络会把前层网络的特征值融合到后面,大概的理解是这样的。所以一层一层是说从特征不断地一层一层向一个纸,比如你有十张纸,每一个纸画不同的部分,十张叠加起来是一个完整的图像。
这是一个原始的汽车,浅层的神经网络看到的前面的特征,然后把不断的特征做叠加,最后会识别出车,所以这是神经网络大概比较浅显的一种解释。
我们发现用AI去做识别是实现自动驾驶的第一步,这是一个非常好的步骤。我们可以简单把自动驾驶的任务做一个分解,第一个就是感知。起码我们相对于人开车的时候坐在车里面,第一步也得知道世界是怎么样的才能去驾驶,所以我们把它放到感知里。
第二步,当你在路上的时候,我们把车作为一个反映体的话,对的是整个世界。在路面上有很多行人、车,包括有交通标识,哪些是静态的,哪些是动态的,哪些能够对驾驶造成影响,这个需要系统做一个判断和做一个比较。

在全面了解环境信息的时候,我们怎么样去做预测?所谓的预测就是中期、短期和长期的预测,这种预测主要是为了对驾驶的策略做一个辅助和判断。当人开车的时候人眼就够了,当你坐在车里的时候你就知道你在什么位置。但是对于车来讲是不行的,所以车需要一个高精度地图,高精度地图不是传统意义上的地图,大家简单理解它是超距的传感器。通过高精地图可以把静态物体包括坐标的信息都放在里面,这样可以知道车的精确位置。这个精确位置,可以保证你做驾驶的策略和怎么样去做判断。在有高精地图配合的情况之下,定位、路径规划就是水到渠成的事情。
我们把AI、自动驾驶功能做了分解之后,发现这些功能需要强大的计算平台来完成。如果是计算力不够的情况之下,自动驾驶是很难去实现的。我们可以想一想这么复杂的人脑,人脑是很复杂的机构,人自己去开车的时候尤其在路况复杂的时候都需要全神贯注,全神贯注意味着我们的大脑在高速运转,你要不断地看路上的信息。从这一点上来看,自动驾驶对计算的要求是自然的过程,是一个正确的选择。
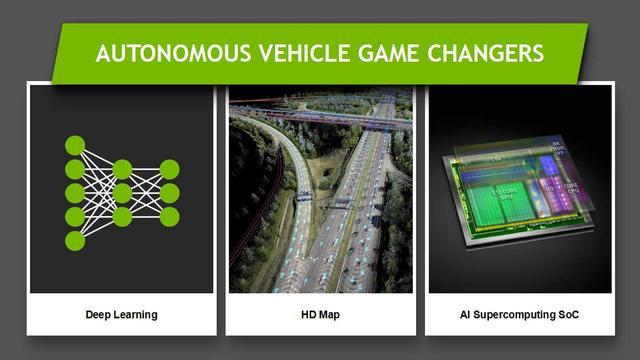
刚才讲过把自动驾驶分解到几种场景,自动驾驶其实对比之前的辅助驾驶ADAS是完全不一样的方式去实现。通过刚才把自动驾驶分成几个模块之后,发现自动驾驶很大程度上依赖于深度学习,因为深度学习在做感知的时候有很好的效率和准确度。第二是自动驾驶是依托于高精度地图。第三是自动驾驶一定是对AI计算、计算力有很强的要求。
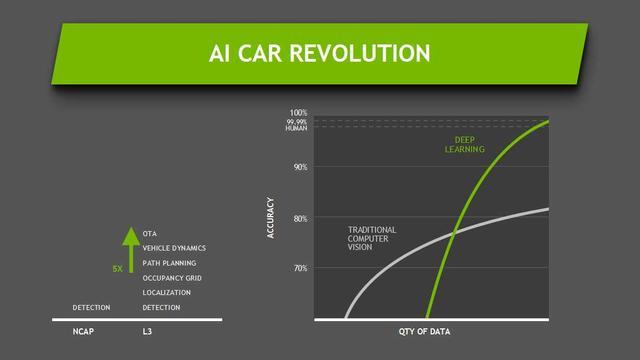
我们自己总结了一下,我们把自动驾驶起了一个比较好听的名字,叫做AI Car的演进。AI Car从三级开始,其实包括了检测、定位。我们有战略网格到车身姿态到OTA,这是三级的主要功能。三级主要的功能就会比二级在计算力的需求上,光是计算力就要高5倍,甚至5倍都不够,所以这还取决于很多算法。包括三级是否在某些特定场景做的,因为即使在特定场景做到3级自动驾驶是非常不容易,因为有变道等等都非常困难。
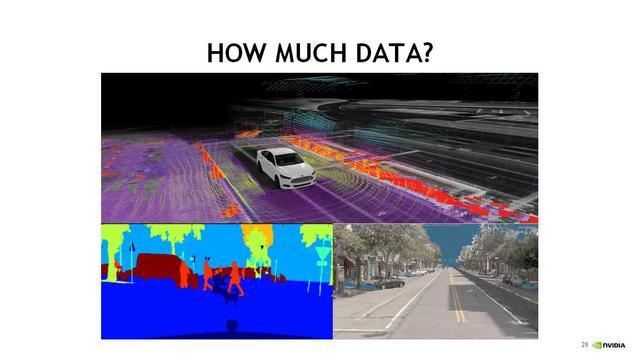
这是一个简单功能的演示,这个车在路口可以看到这些物体,这些物体中包括人,哪些是静态的,哪些是动态的,哪些对行驶方向是有干扰的,或者是影响驾驶。
这是在做路径规划和车身动态,最后是OTA,就是把实时的信息传给车。OTA是非常重要的,尤其在车的行驶中,车的系统是不能重启的。OTA对于技术的要求和系统架构有非常高的要求。
刚才讲了三级自动驾驶,我们往四级自动驾驶去看的时候加入了一些新的场景,比如说限定的城区,基本上要求整个机器系统去做驾驶,人几乎不参与。对故障率有非常严苛的要求,包括安全性、稳定性和冗余星有非常高的要求。在这种情况下,计算力有50倍或50倍以上的提高。因为需要依靠更大、更强的计算资源来保证这个功能能够实现,这个功能的实现必须速度要快,不能反应很慢。比如说简单的用摄像头去做检测,1个摄像头和10个摄像头对计算力的要求不一样。第二是你每秒处理多少帧是不一样的,比如每秒处理30帧以上,但是你可能每秒处理两三帧或三五帧,这样是不行的。像速度低和速度高对本身自动驾驶的意义是不一样的,因为速度低的时候做判断是很容易做,因为不行的话就停了,像机器人不行就停了,停了也不会伤人。但是车不行,车停了也不能解决问题,所以对计算的要求完全不一样。
计算的要求不一样、算法的不一样,造成了整个系统构建时候的考虑因素是不一样的。

在我们说AI CAR,把车外驾驶功能解决了很多的情况下,车内的智能也很重要。这是我们公司的一个产品辅助驾驶CarPlay,其实是辅助驾驶。这个辅助驾驶不一样在哪儿呢?它是内置的摄像头,摄像头可以判断司机的眼睛有没有盯着方向盘或前端,第二看是否疲劳。第三是能够进行语音交互,还能读唇,这个读唇仅仅是英文,对中文是无效的。这个算法是牛津的,国内还没有。但是这是一个很酷的功能,真正坐到车里以后跟它做车内的交互,这样更能带来车内的体验提高以及有用户粘性。
这一页是真正在感知的时候,车的感知和人是不一样的。从车的角度去看这个世界是不一样,不光是激光点,包括手下角是分类,看哪些是人或者是车,哪些是对驾驶会造成影响的,就会有这种分类。
这是给大家一个比较简单的概念,整个自动驾驶对传感器、感知、感知算法、感知计算要求非常高。

上图是目前NVIDIA的合作伙伴在使用我们的方案,包括奥迪、特斯拉、戴姆勒、百度等。
今天的分享就到这里,谢谢大家!
— 完 —
加入社群
量子位AI社群9群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot3入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot3,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI
վ'ᴗ' ի 追踪AI技术和产品新动态





