【图文实录】旷视首席科学家孙剑:计算机视觉的变革和挑战
主讲人:孙剑 | 旷视科技首席科学家
量子位 屈鑫 编辑整理
【本讲直播地址】http://c.m.163.com/news/l/173789.html
周三晚,北京大学“人工智能前沿与产业趋势”第三讲,本期旷视研究院院长孙剑授课主题为“计算机视觉的变革与挑战”,分享了计算机视觉和深度学习领域的一些研究进展。
最后,孙剑与北大人工智能创新中心主任雷鸣就计算机视觉领域的现状及发展进行了深入交流和讨论,也为未来想在计算机视觉领域工作、从事研究的同学给出了建议。

课程导师:雷鸣,天使投资人,百度创始七剑客之一,酷我音乐创始人,雷鸣先生现在致力于人工智能相关研究,孵化和投资。他任北京大学信科人工智能创新中心主任,并开设研究生课程“人工智能前沿与行业趋势课程”,以连接人工智能科研和产业需求。同时,他已经孵化并投资了数家人工智能相关的初创公司。雷鸣2000年获得北京大学计算机硕士学位,2005年获得斯坦福商学院MBA学位,同时也是“千人计划”特聘专家。
主讲嘉宾:孙剑,自2002年以来在CVPR, ICCV, ECCV, SIGGRAPH, PAMI五个顶级学术会议和期刊上发表学术论文100+篇,Google Scholar 引用 40,000+次,H-index 68,两次获得CVPR Best Paper Award (2009, 2016)。同时,2017年孙剑带领旷视研究院,击败谷歌、Facebook、微软等AI巨头企业,获得 COCO & Places 图像理解国际大赛三项冠军(COCO物体检测、人体关键点,Places物体分割)。
计算机视觉的发展
旷视科技从创立到现在一直在做计算机视觉,希望把用机器看懂照片,看懂视频这件事情做深做透。旷视科技是在大范围的人工智能领域中,专注在视觉领域。
人工智能分语音、语义、视觉,视觉是在中国落地最大、公司最多、投资额也是最大的方向。因为视觉的输出有非常多,而语音的核心只是把一段声波变成文字,输入输出都很单一。
计算机视觉和人工智能的关系
第一, 它是一个人工智能需要解决的很重要的问题。
第二, 它是目前人工智能的很强的驱动力。因为它有很多应用,很多技术是从计算机视觉诞生出来以后,再反运用到AI领域中去。
第三, 计算机视觉拥有大量的量子AI的应用基础。
我们比较关心的是这几个核心问题:分类、检测、分割。分类是指把照片中的物体分类,比如这张照片里是有猫还是有狗;而检测就是看图片中的物体都在哪;分割是指标记像素,看它们来自于哪个游离的物体,比如标记图片,使医生更清楚这个病变器官是什么样的。这些对于图片的技术都可以用到视频上,目前实际应用场景中80%都是解决这三个问题。
视觉也是人工智能刚开始时要解决的问题。
视觉研究的发展
视觉的研究主线是怎样去表示一张照片。有很多方法,比较早期的方法叫分人自知的方法,比如人分为头、身体、胳膊,头分为眼睛、鼻子、嘴,整体是由部分组成的,这个方法先后研究了很多年。有很多人工智能的知识应用在这个方法里,但是可做的目标有限,对人、手结构性比较好的可以用这个方法,而很多动物上就无法使用。
90年代时,神经网络第一次能够在小应用上使用。但是很快,研究神经网络方法的人越来越少。 SVMs出来以后,直接输入进行SVMs训练,这种方法的结果跟神经网络的方法很相近。可能是由于当时数据级的不敏感,很多方法可能结果都差不多。但是今天神经网络在这上面效果非常好,远好于SVMs的方法。
还有一些研究图像表示是用学习的方法去学习图像表示,比如右边,让机器学习方法来找一些组合,表示出图像,或者是物体。
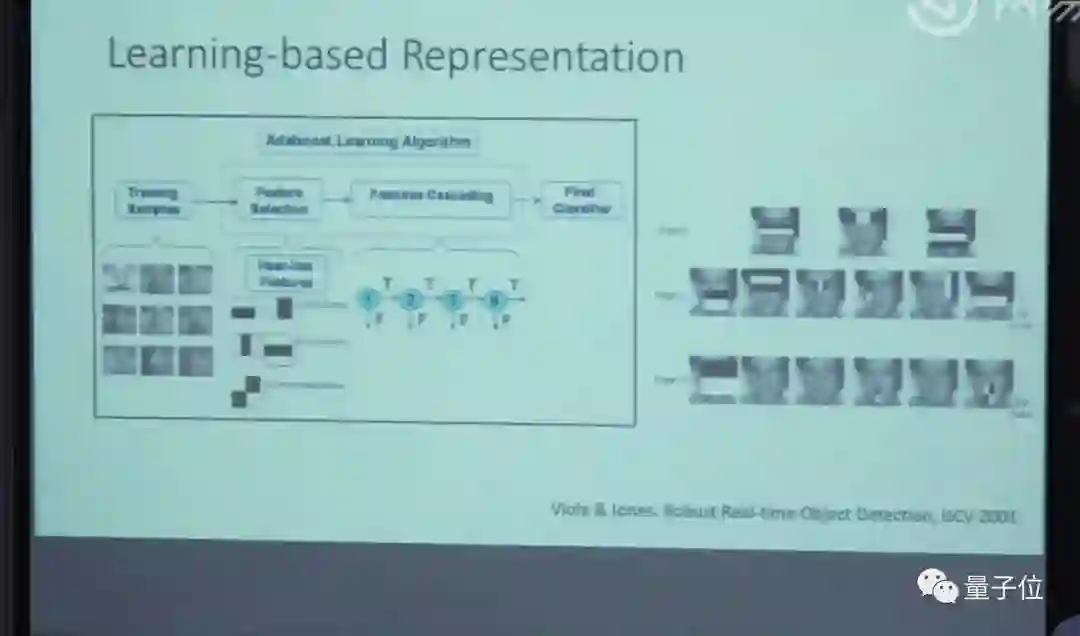
再后来,又新出来一个方法。这个方法是在深度学习之前计算机视觉常用的方法:Features Engineering,这个方法当时是最好的方法。这种方法特色是说Feature人工设计的,后面是SVM,所以大多数做图像分类的都在设计Feature,谁的Feature又快又好,能力又强,谁的方法整体性就好。
这整个体系有个问题。这是一些变化的组合,但是变化的层数比较少,是很短的序列。现在计算机视觉或者是图像视觉是深度卷积神经网络。相对应的两个非常有反差:短序列手工设计,和长序列非手工设计。
最早神经网络叫做感知机,它只有一层,但当时大家就觉得能解决很多问题。很快就被人质疑,随后有人提出了多层感知机。
中间很大的里程碑:BP算法的出现,这个算法是说怎么样自动调整网络里面所有的参数。这个算法其实被不同人在不同时间发明。
但它依然没有兴旺起来,原因有两个:一、存在SVMs这样的方法,理论又好,效率又好,当时还比不过SVMs这些方法。二、优化很困难,很难呈现结果。
在几年前,很多人仍然相信:神经网络是不好的,一个非常深的神经网络是不能够被训练的。 这个魔咒这些年逐渐被打破了。最早Hinton在1996年的Paper提出了layer by layer和unsupervised pre-training的方法,虽然这些方法今天都不用了,但在当时对大家的一个激励。还有计算力的进步,计算力不同也会产生一定的区别,最近几年在Speech、Image、NLP等领域都产生了很大突破。
深度学习
深度学习概念

深度学习为什么叫深度学习?就是因为里面的层数很多,层数多了就叫深。AlexNet在2012年,做了一个八层的网络。这之前,大多数的网络只有三层,但是这个方法当时是受到质疑的。过了两年,一个牛津大学的研究组,把深度推到了20层;然后2015年微软研究团队做了个ResNet:152层的网络。
网络有多少层数今天已经不重要了,其中的基本思想是:学习一个很深的神经网络,是要学习一个映射。相邻几层之间的映射变化不大,这是很直观的想法。变化不大的话,我们就用残差学习的方法,不要直接学习重构网络,而是学习它的变化,变化比直接学会更容易。
训练过程中,是由浅到深的动态。在早期训练过程中,可能是训练浅层网络,在后期时训练深层网络。因为早期浅层网络没办法帮助训练深层网络。
深度学习的效果
这样的深度算法网络,有什么样的效果?这是ImageNet:斯坦福的李飞飞教授,带着他的学生建立的数据集。2000多万张照片,有10几万类,这些照片都是从图像中爬下来的,这个数据库比以前用的更小的数据库真实,主要在上面做分类。

深度学习解决的问题
多层的网络能解决什么问题?意味着什么问题?CVPR 2016最佳论文奖,它解决了深度学习的优化问题。虽然说神经网络是一个很古老的技术,但是它在今天可以通用,是中间一点一滴的进步造成的,包括数据越来越大,计算力越来越好。但是做的这个残差网络是说,这个网络的体系结构要对优化友好。然后结合前人的工作积累在一起,才有了今天可以反复训练,效果非常好的系统。

这篇论文里面优化的问题,深度学习的三大问题。
第一个问题是表述能力的问题。也就是这个模型本身有多少能力的问题。
第二个问题是,假如系统有这个能力,算法能不能找到这个最优解?能把参数调合适吗?
第三个问题是推广能力的问题,推广能力的问题又分成两类:弱推广能力和强推广能力。机器学习研究的基本问题是:训练数据和测试数据的统计是同分布的。弱推广能力是指,如果训练数据和测试数据不同分布,就不管了。强推广能力是指,真正理解了这件事情的表示,遇到新的训练数据集统计、分布和训练数据集,也可以去做。
去年AlphaZero他们也用了残差网络来做AlphaZero核心的技术。
视觉发展时间线
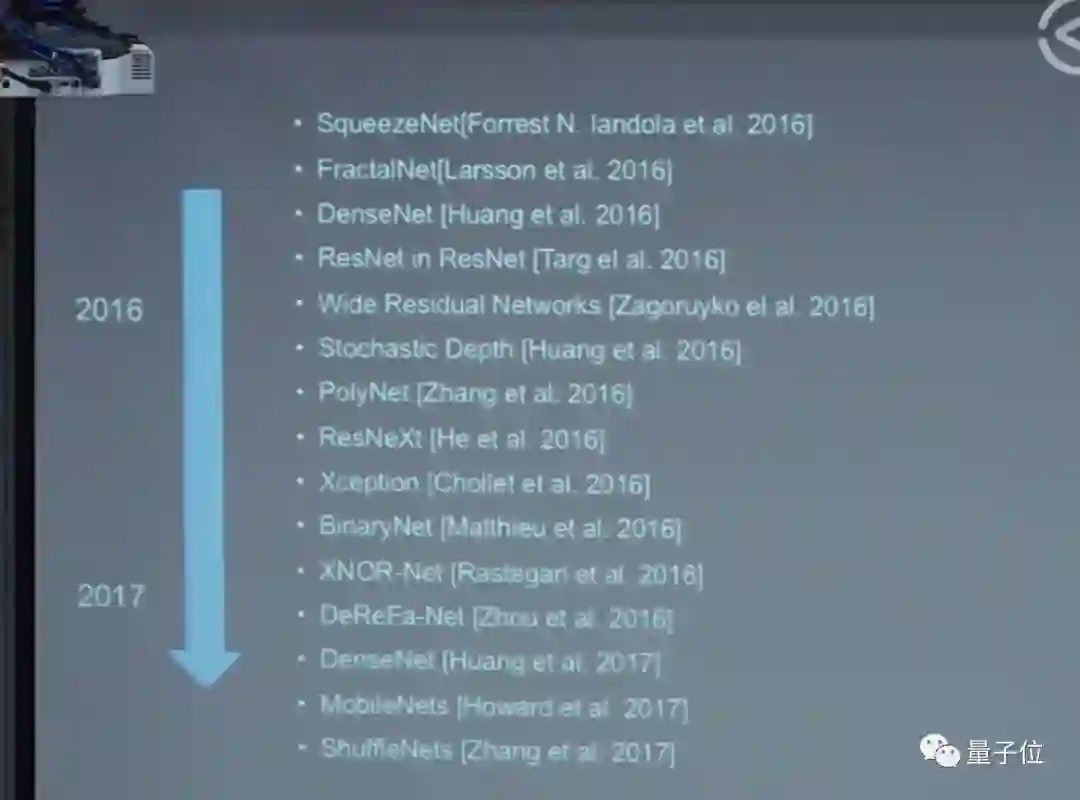
这是视觉识别常用的从2012年到2016年的网络结构,表现出了图像分类很大的变化,最近的新趋势是大家逐渐开始用机器来设计这些网络结构。
视觉的检测
视觉检测非常有用。几年前,做人脸、车的识别,能到70、80分;到了今天,我们可以做很复杂的逻辑检测,训练数据也是足够多的。
最近几年,检测的趋势也是设计物体检测的框架,不光是指神经网络的结构,检测是更复杂的系统。
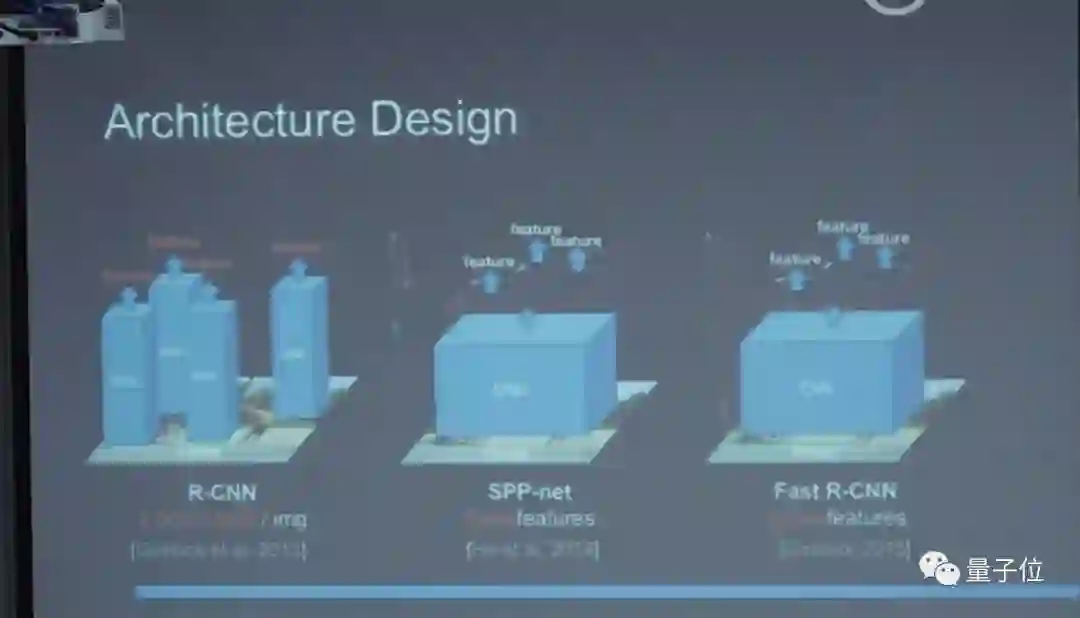
在2013年神经网络刚出来时,微软的一个名叫Rose的研究员做了一个方法:检测在图像中所有位置都让给CNN。我们之后所有东西都是基于这个思想,这也是物体检测中,最近几年最大的突破。
把前面和后面都做反常学习,Feature也重新更新了,效果很好,这就是Fast R-CNN。但是这里有一个问题:窗口还是人工设计的,其实也很慢。后来我们和Rose合作了第一个N2N的检测系统,不需要人工设计成这样的Feature,但框架还是需要设计。
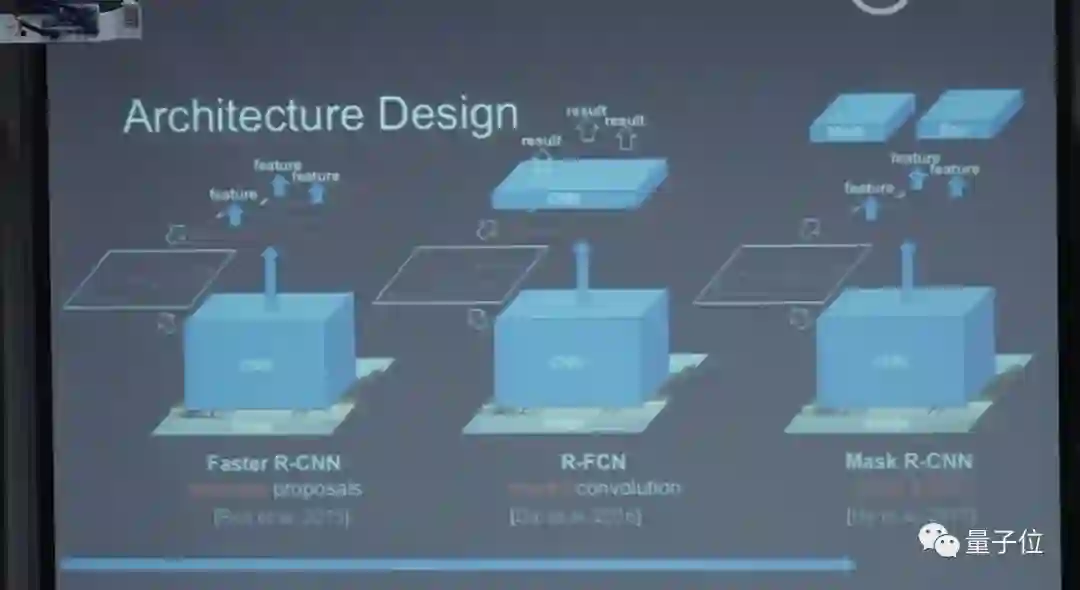
后来又更优化了一下,做了一个非常有效的一步法检测器设计,这个就是Mask R-CNN,目前是最好的物体检测系统。

这是2017年COCO的比赛。在2015年Face++做到37.3;去年做到52.25,得了冠军。
COCO冠军
夺到冠军背后的工作是什么呢?
我们做了两个工作: 第一个是Megdet detection,它解决了如何用很多个显卡在一起测mini-batch的检测器问题。第二个是,Light-Head,它重新设计了Fast R-CNN的网络。
注:量子位曾邀请旷视研究院COCO竞赛冠军队,对相关论文进行解读,附送四份笔记:
第一期:COCO2017物体检测论文解读
第四期:被遮挡人脸区域的检测技术
计算
ShuffleNet

做了一个计算的轴,大家可以看中间是AlexNet,它的趋势是:越往右,清晰度越高,但是要求的网络计算复杂度越来越大;左边是低精度的,但是却是一个很大的需求。

针对低精度的运算,Face++去年做了一个工作是ShuffleNet,它是专门解决在低计算复杂度下如何能把精度做到最高程度的问题。ShuffleNet的设计原理是:把输入的channel拆成很多的组,拆成组以后做channel shuffle的操作,把信息交换,然后再做一个3D的shuffle卷积,然后再分组卷积。分组卷积可以很有效地降低计算复杂度,但会丢失一些性能,需要自主判断如何折中。
ShuffleNet有什么用呢?
举一个例子,旷视科技的产品:智能人像抓拍机。这个相机里面有一块FPGA的芯片,FPGA上运行着我们ShuffleNet人脸检测系统,它今天是业界唯一一款可以在高清图像下,每帧都做检测的一个智能终端相机。
Brain++
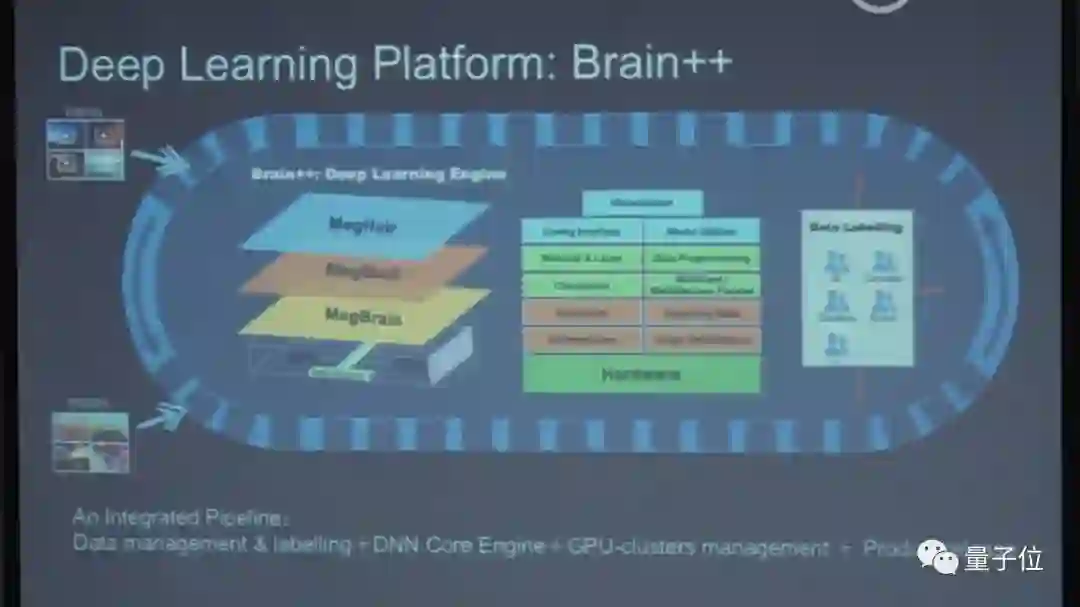
今天的GPU、CPU,不管在云上还是在端上带来很多变化,我们也很早就注意这方面的变化。Face++做了一个Brain++的一条系统,Brain++是指如果想训练神经网络,需要有一个GPU集群,然后需要有扩大的系统来管理这些软件,中间要有一个叫深度学习框架,比如TensorFlow,而我们做了一套叫Brain++,这是我们自己研制的深度学习框架。
为什么我们自己要研制一个深度学习框架?

一个原因是历史原因。当时TensorFlow还没出现,当时只有像caffe的第一代系统。现在的系统都是基于计算图做的,设计已经完全不一样了,我们当时自己做了一个框架,TensorFlow出来之后,大概也是类似的。
这也是公司的风格,要很系统化的做事情,应该是所有创业公司中唯一一家自研深度学习引擎并且全员使用,这两个条件是并列的关系。

也有很多应用,最重要的是人脸识别,这也是最早商业落地的应用。人脸识别以前是传统方法,现在是两种formulation来做。
基于人脸技术能做什么呢?

Face++前几年做了一个人工智能开放平台,把我们很多这样的能力都开放出来,放到云上,这个比微软、谷歌都更早一步。目前有几十万的开发者用户来使用这样的服务,超过一半的用户都是海外用户。
1:1的人脸验证应用在很多地方,Face++的Face ID身份认证服务,有非常多银行的、互联网金融的、出行的客户。

人脸是一个很小的部分,其中更大的应用就是城市大脑。城市大了,感知数据以后可以把这些感知数据形成有效的信息提取出来然后参与决策,不管是对政府还是对商业都是需要做,如果在街面的话可能是公共安防,如果市内的话可能就是商业、零售、地产。
雷鸣对话孙剑

你怎么看CV一些传统的方法,和现在深度学习的方法?以前的算法在深度学习中的贡献有多大?
今天我讲的是图像理解、图像识别的主要内容,其实CV领域包含的内容非常多,其中一大块就是3D,这个领域还是没有被深度学习所统治,甚至短期内可能也统治不了。它的基础是几何,像IPhone X其实也是3D成像的一个过程。
还有一方面叫做初期视觉,比如说把这张照片分辨率提高,把颜色调好。这一块现在处于混合状态,有很多传统方法在这种情况下起到很大的作用。
当然有新一代的方法出现的话,这些新的方法是诱变的,那可能是更健康的状态。
深度学习没有很强的可解释性,会不会对深度学习的应用上带来潜在的风险?
这是两方面,一方面是说,在我们实际应用中还没出现这样的对深度学习攻击的情况,比如说修改图片,很小修改就能够骗过我们的系统产生错误的输出,这个叫做对抗样本,对抗样本也有很多情况:有一种是,它知道这个是系统什么样的设计;一种是不知道你的系统是什么样的设计。目前还没有真的出现大规模,连小规模都没有出现过真的有人来攻击系统的情况。
第二个从方法本身来说,这并不是深度学习特有的问题,即便是一个先进的照片仪器,也依然会有这样的对抗样本出现。只是说大概以前对深度学习关注不够,现在大家有了更多的关注。
现在其实都处在论文状态,没有真正地有这样实际的驱动力量做这件事情。
过去很长时间的进展都在图片时代,但现在在逐渐进入视频时代,那视频处理上现在有些什么进展?未来在视频的理解、追踪、分类、感知、描述等等这些方面会有哪些进展?
视频做得比较多的是:把一段视频里做的事情分类。比如这个场景是在弹琴,还是做体育运动。这里面有一个基础方法是:对每张照片分类,然后把每张照片的分类结果加权在一起取一个平均,得出分类。我觉得这个分类还不够难,分类的类数还不够多,深度学习可能没有很好地挖掘视频里面的信息,通过图片的几个分类就做好了。
但是细小的分类是难度很大的,比如区别两个视频的舞种。
目前像抖音、快手,有一些视频分类的需求,主要是推荐、整理,在这些方面的话,还没有很好地驱动出更不一样的方法出现。
再深入的话,就是对里面每个运动的物体能够很好地定位、跟踪,比如说知道一辆车是从左边出来的,中间被另外一辆车挡住了,停留5秒钟又出来还是那辆车,这种整个的分析系统会涉及到很多的关联、推理、预测的问题。
你以前在微软研究院其实待了挺长时间,研究院的环境可能还是相对比较宽松,后来到了Face++,这个转换过程你有什么体验?有什么变化吗?
在微软研究院也做很多产品相关的事情,我自己研究的信念是:理解研究的问题,一方面把研究做好,一方面把研究的商业做好。所以对我来说的话,从微软到Face++,打造好Face++研究院的环境,我做的事情是非常类似的,只是说现在在实际应用中,看到了更多的问题。
如果环境太宽松,可能看到的都是学术界的一些问题,在产业的研究院中可以看到更多的问题。
另外,创业公司研究院第一任务是:这个研究需要有市场竞争力。以前我会觉得技术差不多就行,95和97是差不多的,已经能用了,用户体验可能也差不多。我到了创业公司研究院第一件事情就是,基础一定要做好。今天有研究院的公司大多数是To B的,这个技术给另外一个企业来用的,他们用这个技术做一个产品,当然会选择最好技术,哪怕就差2%,也希望能用最好的技术,很多时候不是钱的问题,是心理的问题。
在旷视,科研、工程包括还有产品,这些团队怎么能够无缝合作?会不会有一些矛盾?
这个是大的问题,大概会分成几块,研究院生成算法,需要模型文件,我们公司有专门的平台业务组,把这个模型做成在各个平台上用的SDK,然后产品组会在这些在不同的平台上加逻辑、场景应用,做出10个产品,这样相对就做了一定的结果化,这样的话大家效率会更高一些。
现在人脸识别应用非常广泛,未来再看三五年的话,从视觉落地的角度,你觉得在哪些大的领域会发展很快,尤其在落地的速度上、影响上,或者从商业的价值上会大行其道?
这个方面的话大概有两个轨迹,一个是哪个行业,哪个行业落地更容易,哪里摄像头最多,哪些产品是我们最去想,所以我们就应该以这样的轨迹去考察我们现在的产品。当然公司对场景发生的周期判断是不一样的,可能是对,也可能是错。
从现在实物上还是能看到除了基于人脸身份的识别和认证,从安防到身份鉴别领域用得特别多,也挺方便的。
另外像无人车、无人机、物流机器人这一类的应用还是蛮大的。
然后是在视觉医学上有些应用,也发展得也还算比较迅速。
作为一个学生,如果将来想从事视觉领域的一些工作,更多的是科研或者创业的,那现在应该怎么去对未来做一些准备?应该做一些什么事情将来进入到产业的时候能够做铺垫?
两个方面,一方面就是说,趁现在读一些书,然后看一看都可以做哪些事情,几本书我推荐一下,一是微软的研究人员写的一本书叫做《计算机视觉》,它是讲计算机视觉很多的算法,大家通过这本书可以了解,不是今天大家关心深度学习才是全部,其实还有好多其他的。
另外一本是《深度学习》,这本书翻译的团队是北大的张志华教授的团队,张志华教授是我师兄,我自己的机器学习理论跟张教授学的,我相信这本书翻译的质量是过关的。
最后,建议大家去公司实习。Face++离北大挺近,大家可以来交流一下。(笑)
观看直播
直播地址:
http://c.m.163.com/news/l/173789.html
点击文末左下角“阅读原文”可直接跳转到直播页面~
加课程群
及时获得课程全部信息和直播内容
讲座期间,可在群里向嘉宾提问~高含金量的问题主办方会请专家亲自回答,并在直播中播出
收获每天AI 最新资讯
温馨提示:扫描二维码加入(视觉)AI课程交流群,若上面的人数已满


下期预告
下周三晚18:40,北京大学“人工智能前沿与产业趋势”第四讲,将由英特尔中国研究院院长宋继强为大家授课。
独家媒体合作






