人类的本质是计算机?大四本科生测试1800人:98%的人和机器想法一致

新智元AI技术峰会倒计时3天
新智元将于3月27日在北京泰富酒店举办“2019新智元AI技术峰会——智能云•芯世界”,聚焦智能云和AI芯片发展,重塑未来AI世界格局。
同时,新智元将现场权威发布若干AI白皮书,聚焦产业链的创新活跃,助力中国在世界级的AI竞争中实现超越。
参会二维码:

新智元报道
来源:Nature Communications
编辑:金磊、张乾
【新智元导读】约翰霍普金斯大学的最新研究发现:人类可能在像计算机一样思考。这样研究的作者、大四学生周正隆等人对1800人做了实验,结果显示98%的人倾向于像计算机那样回答问题。
人类的本质不是复读机,可能是计算机。
长期以来,人们想方设法研究让计算机像人类一样思考,比如做视觉识别。但是,约翰霍普金斯大学的最新研究发现:人类可能在像计算机一样思考。
不信先来做一组测试。
第一题:你觉得计算机会把下图认成什么?

A.交通信号灯
B.电话
答案是:
·
·
·
·
·
·
·
·
A

第二题:你觉得计算机会把下图认成什么?

A.货运车
B.校车
答案是:
·
·
·
·
·
·
·
·
B

你是不是都选对了?
还有几道题,读者可以点击下面的视频测试。
我们知道,即使是像自动驾驶汽车那样功能强大的计算机,只要把某些图像的像素稍作改动,摄像头就可能被欺骗,例如会把黑人识别成猩猩、把香蕉识别成烤面包机等等,这些机器似乎以人类永远无法想象的方式错误地识别物体。
但真的是这样吗?
约翰霍普金斯大学的测试视频显示,75%的人其实选的跟计算机一样,并且他们还对1800人做了八组实验,发现98%的人倾向于像计算机那样回答问题。

换句话说:虽然我们看不见,但其实人类知道计算机在想什么,因为人类可能在像计算机一样思考。
这项研究是由约翰霍普金斯大学大四本科生周正隆(Zhenglong Zhou,音译)等人提出来,主要证明计算机错误识别物体的缺陷可能并不像人们想象的那么糟糕。研究也提供了一个新的视角,以及一个可以探索的新的实验范式。

这项研究论文发表在最新的Nature Communications上,周正隆是第一作者。
论文地址:
https://www.nature.com/articles/s41467-019-08931-6
计算机视觉领域存在一个关键的盲点:有可能故意制造出神经网络无法正确看到的图像。这些图片,被称为对抗性或愚弄性的图片。
其中,对抗性图像中有两类特别引人注目,它们可以被粗略地称为“欺骗”图像(“fooling” image)和“扰动”图像(“perturbed” image),如下所示:

a.间接编码的“欺骗”图像。b.直接编码“欺骗”图像。c.扰动对抗图像。d. LaVAN攻击可以导致机器对自然图像进行错误分类。e.“鲁棒的”对抗性图像是从多个角度错误分类的3D对象的呈现。
欺骗图像:是毫无意义的模式,被机器视觉系统归类为熟悉的对象。例如,一组有方向的线条可以被归类为“棒球”,或者一个彩色的电视静态图像可以被称为“犰狳”。
扰动图像:通常可以被准确而直接地分类(例如,雏菊的普通照片,或者手写的数字6),但是被机器稍微扰动一下,就会产生完全不同的分类(例如,美洲虎,或者手写的数字5)。
对抗性图像是一个大问题,它们不仅可能被黑客利用,造成安全风险,而且,人们本能地认为,人类不会像机器那样对图像进行分类,人类和机器看到的图像非常不同。
尽管经常有人断言,对抗性图像“完全无法被人类眼睛识别”,但很少有研究通过测试人类在这类图像上的表现来积极探索这一假设。与此同时,在什么条件下可以有效地比较人类和机器的性能,这一点从来都不清楚,特别是因为这类机器视觉系统通常只有有限的标签可以应用于这类图像。
为此,周正隆等人引入了一种“机器思维理论(machine-theory-of-mind)”任务,询问人类是否能够推断出机器视觉系统将分配给给定图像的分类。
人类的任务是“像机器一样思考”并确定为每个图像生成了哪个标签。
周正隆等人对任务进行了八次实验,探索人类对五种不同对抗性图像集的理解。在这8个实验中,涵盖了各种各样的对抗性攻击,以及核心实验设计的几个变种。实验发现,人类受试者能够预测机器对对抗性刺激的分类。结论是,人类的直觉比机器分类更加可靠。
由于篇幅有限,本文只介绍八个实验中的前三个。
实验1:用foil标签欺骗图像
第一个实验采用48张欺骗图像来进行“机器思维理论”任务。这些图像是由进化算法产生的,用来混淆一个极具影响力的图像识别CNN——AlexNet,并将它们归类为“Pinwheel(风车)”和“bagel(百吉饼)”等熟悉的对象。
在每一项试验中,受试者都看到了一张欺骗图像,并选择他们认为机器为该图像生成的两个标签中的任何一个,如下图所示。
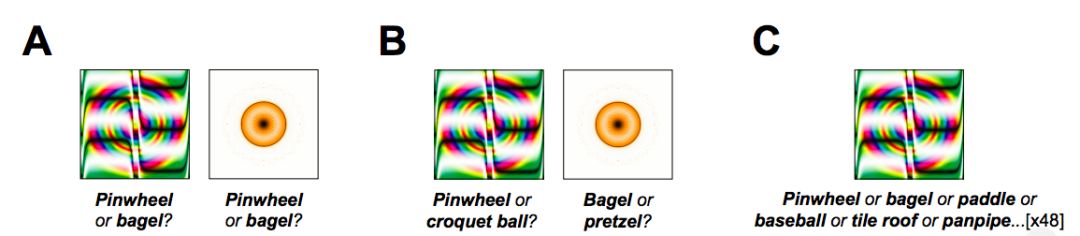
图2
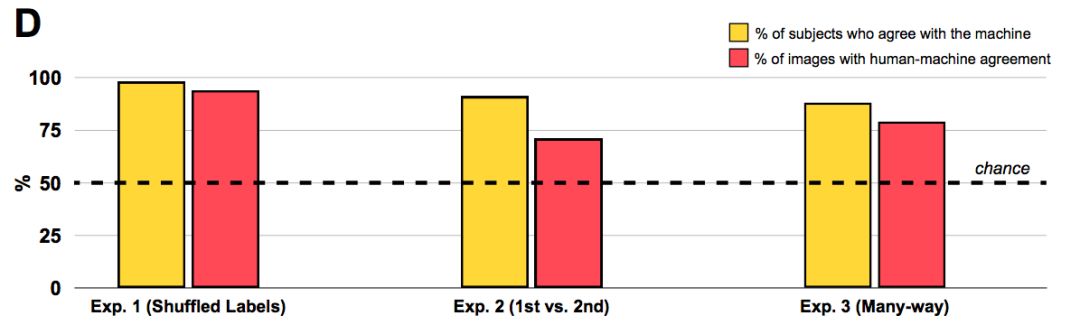
值得注意的是,人类观察者强烈倾向于机器所选择的标签,而不是foil标签:分类的“准确性”(即,与机器分类一致)为74%,远高于50%。
也许更有说服力的是,98%的观察者选择机器的标签的几率高于随机比率,这表明人们惊人地对机器的选择是普遍认同的。
这一初步结果表明,人类观察者可以大致区分CNN用于将欺骗图像分类为熟悉对象的特征。
实验2:首选 vs. 次选
这种能力到底有多强呢?
虽然实验1中的受试者可以将机器选择的标签与随机标签区分开来,但是这种实现,可能不是通过辨别图像与其CNN生成的标签之间的任何有意义的相似性,而是通过识别它们之间非常肤浅的共性来实现的。
为了询问人类是否能够理解机器所做出的微妙区分,实验2将CNN的首选标签与随机标签进行了对比。
例如,考虑到图2中的圆形金色斑点,AlexNet在“bagel(百吉饼)”之后的下一个选择是“pretzel(椒盐卷饼)”,它同样意味着弯曲的金色物体。因此,便得到了每个被欺骗的图像排名第二的选项,并让实验2中的观察者在机器的首选项和次选项之间做出选择。
同样,人类观察者同意机器的分类:91%的观察者倾向于选择机器的首选项而不是次选项,71%的图像显示人机一致(下图中间柱形)。
显然,人类能够从对抗性图像中识别出更深层次的特征,从而将CNN的主要分类与替代分类区分开来。
此外,这一结果还表明,即使在图像标签的排序上,人类和机器也表现出重叠,这表明,CNN的次选项对人类来说也是比较直观的。
实验3a:多种方式分类
上述实验表明,人类可以从相关备选方案中识别机器的首选标签。
然而,这两项研究都涉及仅有两种选择的有限情况;相比之下,图像识别CNN通常在对这样的图像进行分类时是从数百或数千个标签中进行选择。 若是在更不受约束的情况下,人类在图像分类时是否会做出与机器一样的选择呢?
即使在这些苛刻的条件下,88%的受试者以高于概率的速度选择了该机器的标签。此外,在一项受机器学习文献中排名第5的测量方法启发的分析中,我们发现63%的图像中,机器的标签是人类选择的前五名中的一员。
换句话说,即使单个最受欢迎的人类选择标签不是CNN的首选标签,第二,第三,第四或第五最受欢迎的人类选择标签(48种可能的选择中)通常与CNN的首选标签相匹配。
实验3b:“这是什么?”
之前的研究更接近于CNN在图像分类中所面临的任务,即在众多图像中选择一个标签进行分类。
然而,之前所有的实验都与CNN的任务有另一个不同之处:CNN选择一个与图像最匹配的标签,而我们的人类受试者被要求预测机器的标签,而不是自己给图像贴标签。如果人类的任务只是简单地直接对图像进行分类,他们还会同意CNN的分类吗?
实验3b通过改变任务说明来研究这个问题:不是让受试者“像机器一样思考”并猜测机器的首选标签,而是简单地向他们展示图片,并问他们“这是什么?”
在每次试验中,屏幕上都会出现一张图片,受试者被问到“如果你必须为它选一个标签,你会选什么?”(有48种标签)。
再次,人类的判断和机器的分类融合在一起:90%的受试者同意机器,81%的图像显示人机一致。这些结果表明,人类破译对抗性图像的能力并不取决于我们的“机器思维理论”任务的特性,而人类的表现反映了对机器(错误)分类的普遍认同。
接下来的四个实验分别是:
电视静态图像;
被扰动的数字;
自然图像和局部扰动;
3D对象。
详细内容可以查看原文章:
https://www.nature.com/articles/s41467-019-08931-6#rightslink
目前的研究结果表明,人类的直觉是机器如何对图像进行分类的可靠信息来源——即使是那些专门用来欺骗机器的对抗图像。
这意味着,在将图像与标签关联时,人类和机器在优先级的图像特性上至少存在某种有意义的相似性。
对抗性图像的存在让人怀疑,最近开发的机器视觉系统在如何对图像进行分类方面是否与人类有任何真正的相似之处,以及此类模型是否可以被秘密攻击。目前的结果表明,这种挑战人机相似性的概念可能并不像看上去的那么简单。
更加熟悉对抗性图像的空间可能会让人们更好地预测机器的分类,也许未来的工作可能决定如何最好地准备和训练人类检测和破译这些图像。
以上就是周正隆等人发表在Nature Communications上的论文主要内容。

周正隆等人的研究给人们研究计算机眼中的世界提供了一种新的思路。
实际上,Ian Goodfellow等人在去年的时候也做过探索解决对抗性图像的研究,在研究中,构建了从计算机视觉模型转移到人类视觉系统的对抗性示例。

在这篇论文中,Ian Goodfellow等人利用了机器学习、神经科学和心理物理学三个核心思想:
首先,使用最新的黑匣子对抗性示例构造技术,为目标模型创建对抗性示例,而无需访问模型的体系结构或参数。
其次,调整机器学习模型以模仿人类的初始视觉处理,使得对抗性示例更有可能从模型转移到人类观察者。
第三,在时间限制的环境中评估人类观察者的分类决策,以便甚至可以检测到对人类感知的微妙影响。
研究发现跨计算机视觉模型传递的对抗性例子确实成功地影响了人类观察者的感知,从而揭示了计算机视觉模型与人类大脑之间共享的一类新幻想。
论文地址:
https://arxiv.org/abs/1802.08195
行文至此,引出另外一个话题:AI眼中的世界到底是什么样子?
最近,谷歌与OpenAI共同创建了Activation Atlases(激活地图),这是一种可视化神经元之间相互作用的新技术。通过使用特征反演(feature inversion)来可视化一个图像分类网络中数以百万计的激活。
换言之,神经网络图像分类的黑匣子终于被打开了。
详细文章请点击下图了解Activation Atlases的原理。

你认为人类的本质是什么?
【2019新智元 AI 技术峰会倒计时3天】
2019年的3月27日,新智元再汇AI之力,在北京泰富酒店举办AI开年盛典——2019新智元AI技术峰会。峰会以“智能云•芯世界“为主题,聚焦智能云和AI芯片的发展,重塑未来AI世界格局。
同时,新智元将在峰会现场权威发布若干AI白皮书,聚焦产业链的创新活跃,评述AI独角兽影响力,助力中国在世界级的AI竞争中实现超越。
参会二维码
活动行链接:http://hdxu.cn/9Lb5U
点击文末“阅读原文”,马上参会







