演讲实录 | 张钹院士:深度学习与信息安全,如何从“事后诸葛亮”到“防患于未然”?
转自 北京得意音通
7月31日在清华大学举办的“人工智能与信息安全”清华前沿论坛暨得意音通信息技术研究院成立大会上,有6位来自不同领域的特邀嘉宾受邀前来,为大家带来精彩的演讲。
本章为中国人工智能学会组建的科学传播专家团队--人工智能及其应用团队首席科学传播专家张钹院士演讲实录。按照张院士要求,文章采用文字+PPT的形式发布。

张钹
清华大学计算机系教授,中国科学院院士。1958 年毕业于清华大学自动控制系,2011 年汉堡大学授予自然科学荣誉博士。曾任清华大学学位委员会副主任,参与创建智能技术与系统国家重点实验室。现任微软亚洲研究院技术顾问。参与人工智能、人工神经网络、机器学习等理论研究,将这些理论应用于模式识别、知识工程与机器人等技术研究。曾获国家教委高等学校出版社颁发的优秀学术专著特等奖、 ICL 欧洲人工智能奖等。

本文经张钹院士授权,如需转载请联系后台。
以下为讲座文字整理版及PPT演示
(全文共7000字,阅读时间约12分钟。)

演讲题目:深度学习与信息安全
张钹:很高兴有机会来演讲,今天我要讲的两个都是最热门的话题,一个是深度学习,一个是信息安全。我讲的主题是:人工智能改变信息安全的未来;信息安全促进人工智能的未来发展。

“入侵检测”可以带动大多数信息安全问题
信息安全包含的内容非常之多,有网络安全、主机和存储器安全、身份认证、入侵检测等等。我今天围绕入侵检测问题进行讨论。
为什么选这个题目?入侵检测、身份认证等,本质上是模式识别问题。入侵检测,要判断是入侵、非入侵;身份认证要判断是本人、非本人,可以说如果是“本人”代表不是入侵,“非本人”则代表入侵。因此“入侵检测”可以代表大多数的信息安全问题。
人工智能最重要的进展是在模式识别方面。深度学习用得最好的、效果最好的地方也是模式识别。因此我选这样一个话题来谈信息安全,有一定的代表性。

解决网络攻击智能化新挑战仍需借助AI
信息安全面临非常大的挑战。人工智能既有助于信息安全,同时也给信息安全带来非常大的危险。因为同样的,进攻方、入侵方完全可以利用人工智能技术来加强进攻能力。随着网络的扩大,可能被入侵的地方或被进攻的地方越来越多,漏洞越来越多,缺陷也越来越多,所以进攻的次数也会越来越多。现在已经有利用人工智能技术——攻击的智能化,制造一种病毒或入侵的手段,可以自动寻找网络的缺陷进行进攻。有了人工智能技术以后,进攻方产生各种各样新的进攻手段越来越快。进攻非常频繁、出现的频率非常之高。这就带来一个问题,我们如何面对新的挑战?唯一的办法就是借助于人工智能技术。

这张图是斯坦福大学发起的“AI100”的研究,他们估计在2015-2030年这15年间,人工智能有可能在以上8个方面取得突破,或者说这8个方面是人工智能重要的应用领域,其中有一个就是公共安全。因此,信息安全领域肯定是人工智能最近15年重要的应用方向。
那么,如何利用人工智能技术特别是深度学习技术来进行入侵检测呢?
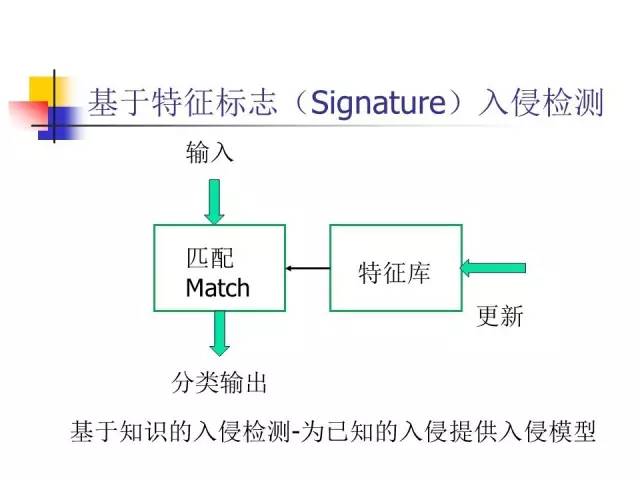
基于特征标志的入侵检测
入侵检测怎么做?
传统的做法,无论是防病毒也好,防入侵等其他形式的攻击也好,基本上用的是基于特征标志的方法,把各种各样已知入侵的特征组成一个特征库,当数据进来以后,如果跟这个特征库中的某个特征匹配上,就认为是入侵。
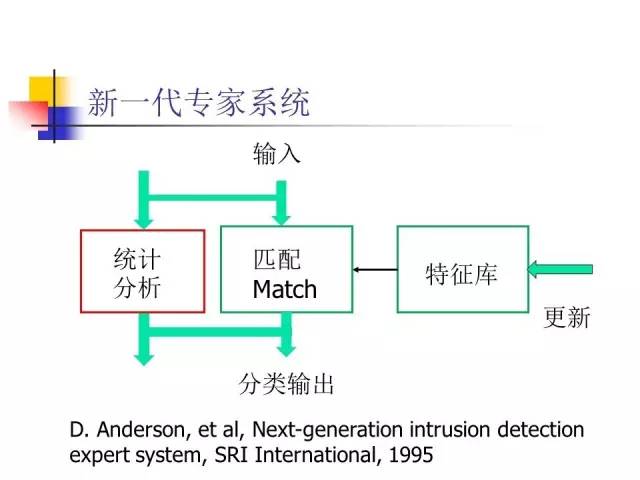
新一代专家系统
从人工智能角度来看,基于特征标志的入侵检测实际上是一个简易的专家系统,特征库相当于知识库,通过人工编程方法把特征写入特征库,然后对输入数据的特征进行匹配,匹配上了就算找到入侵。这显然是一个最简单的、没有推理的专家系统。
专家系统的方法有一个非常大的缺点,即就事论事,也就是说只能针对已知的入侵,新的入侵只有发生之后,事后才有可能去发现它的特征,然后进行特征库的更新。所以特征库要不断更新,更新包括两方面内容:
第一,把不需要的、没用的特征去掉,因为有的攻击是针对一定的软件版本的,当软件升级,漏洞补上以后,它的特征就无用了。这些多余的特征必须去掉,以保证系统的效率。
第二,需要把新发现的入侵的特征加进特征库。
为了更快地发现新的入侵,提出了第二代专家系统。在系统中增加一个统计分析,用来分析数据流的异常行为,比如说数据量突然增加等等,从中发现可能存在新的入侵。这种系统也存在缺点,通常误报率很高。比如数据流量突然增加了,可能是正常的,但是也有可能发出警报。
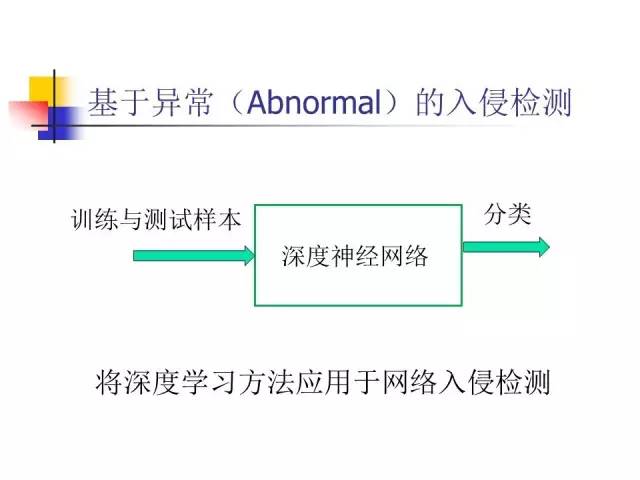
基于异常的入侵检测
先谈把传统统计机器学习的方法应用于基于异常分析的入侵检测,即采用机器学习的方法进行“入侵”的学习和判断。做法比较简单,对已知的入侵,先人工抽取一些特征,经过机器学习之后,机器就会根据所选择的特征对是否是入侵进行判断。这叫做“有监督学习”,它的优点是有一定推广能力,即针对已知入侵的变种,只要变化不是很大,仍然可以鉴别出来。如果变化很大的话,还是辨别不出来。所以这种方法原则上也只能检测已知的入侵方式。
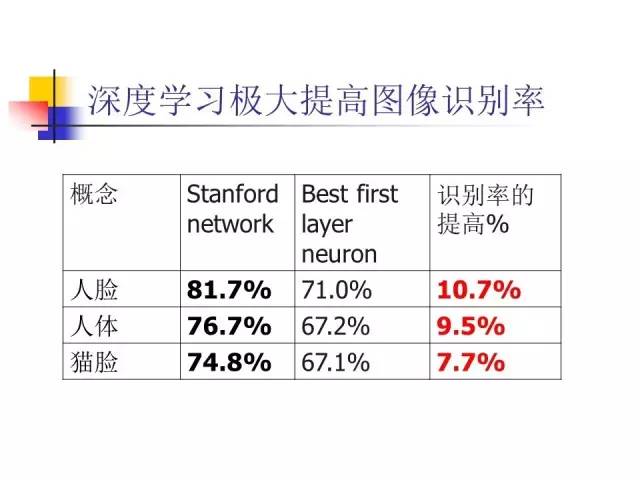
深度学习极大提高图像识别率
实际上深度学习很简单,只是把原来神经网络的层次增加。可是加多层次以后,却发现两个没有想到的现象:
第一,识别率提高非常之多,提高了两位百分数,这在模式识别里非常罕见。我们过去要提高1%-2%,需要花好长时间,这里只要把神经网络层次增加了,居然性能提高这么多,这是出乎大家意料的。

人工智能的重要突破
第二个出乎大家意料的,可以算是人工智能的重要突破。过去搞模式识别,比如人脸识别,我们必须去寻找判别不同人脸的特征,人工选择特征,这是比较难的。因为我们通常说不清楚怎么去区别张三和李四,张三、李四脸部的特征是怎么的?有了深度学习以后,我们只要输入原始数据,机器会自动选取特征。这种方法自然也可以用到入侵检测,因此有了深度学习方法,可以不需要“选择特征”的专业知识。
大家为什么对深度学习寄予这么大的希望,因为运用深度学习可以解决“知其然不知其所以然”的问题。过去人工智能只能解决“知其然又知其所以然”的问题,这类问题很有限。但是知其然不知其所以然的问题很多,模式识别一般属于这类问题。
比如,声音识别,我们通常说不清楚张三的声音和李四的声音有什么区别,你为什么能判断出是你父母说的话,它的特征是什么,说不出来。传统的学习方法只能通过不断的试错,最终找到合适的特征。有了深度学习以后就不用了,只要有足够的样本,完全可以让机器自动找到所需的特征。正是这一点不仅给我们带来好处,也带来很多问题。深度学习实际上并不完美。

深度学习方法的优势
无需人工寻找特征,机器自动选择特征。


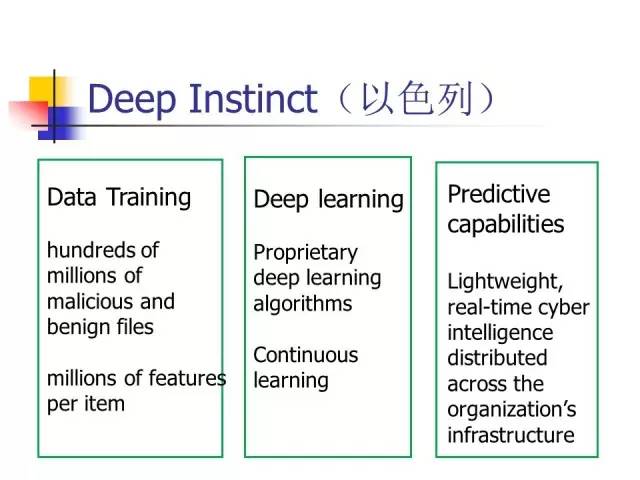
正因为如此,很多公司都往这个方向走。目前IBM最主要的是把两项技术引进Watson系统,一个是人工智能,一个是区块链技术。大家认为这是解决安全问题的两大杀手锏,第一个是区块链技术,从底层来保证数据的安全,不被篡改、不被盗窃。区块链和人工智能两个技术结合起来,有可能得到一个真正的安全系统。

基于深度学习方法的局限性(不可解释性、鲁棒性差、需要大量的训练样本、推广能力差)
现在看看应用深度学习带来的问题,这些问题主要由于深度学习不需要专业知识所引起的。不需要专业知识虽然给我们带来方便,但是也带来了很大的问题。深度学习需要大量的数据,这些数据必须是完整的、确定性的等等。换句话讲,如果数据缺损,缺损的内容就学不到了。还有不可解释性、鲁棒性差、推广能力差等。这些都是方法本身带来的。

下面用一些例子来说明深度学习的缺陷。比如,这是一个“物体识别”系统,向它输入一组噪音,系统却判断为知更鸟、猎豹等等,而且不能做出解释,因为它是一个“黑箱”学习方法。因为没有专业知识,只能盲目的黑箱式的学习,并且没法解释,这种系统就很难进行人机交互了,人就很难判断其结果是对还是不对。所以一旦机器做出错误的决策、错误的判断,人无法进行纠正,因为他不能理解(解释),这一点非常危险。

鲁棒性非常差。例,原来是熊猫,只要加了一点特定的噪声,在人看起来还是熊猫,但是机器看起来却是长臂猿,也就是说,“熊猫“加上一点干扰,就成为长臂猿,这是鲁棒性差的表现。这种系统很容易被攻击,也带来了一些问题。

推广能力差。例,我们需要大量的学习样本,如,猫,必须给出不同背景下面的猫,让机器学习,学完以后,虽然能认识相似背景下的猫。可是如果拿一个没有见过的背景下的猫,机器就不认识了。这就是说,深度学习训练的样本越多,推广能力却越差。这是大家没有想到的。
现在人工智能唯一引起骄傲的,在不加约束条件下,声称可以战胜人类的,恐怕只有像Alpha Go这样的程序了。许多时候说,机器超过人类,都是有条件的。语音识别超过人类,也是在一定的条件下面这么说的。如有噪声的话,语音识别率马上跟人没法比。问题出在什么地方?还是出在我们用的方法本身,因为深度学习推广能力比较差。
回到信息安全问题:当机器学会判别若干攻击方法之后,如果攻击方法稍加变化,机器就判别不了。

信息安全面临的挑战
如何解决这个问题?这是目前正在研究的课题,即:如何提高模式识别的鲁棒性,以及应对变化的能力。让入侵检测不再是”事后诸葛亮“,而是”防患于未然“。人工智能在其中能起什么作用?

入侵检测方法
入侵的检测方法有两种:第一,通过人工编程,找到它的特征,进行检测。第二,通过学习进行检测。这两个方法都有其弱点。第一个方法只能检测已知的入侵,第二个方法虽然检测得比较快、比较方便,但是推广能力很有限。目前发展的趋势是把这两个方法结合起来。即把知识驱动的方法跟数据驱动的方法结合起来,才有可能解决刚才讲的那些问题。

知识驱动方法需要知识,当你对需要解决的问题的规律了解很少,甚至不了解时,又如何做好这项工作呢?知识驱动属白箱方法,要求你对所要解决的问题有透彻的了解。数据驱动需要充分的数据,可以不需要领域知识。可是,在实际问题里,这两点(完全知识与完全数据)都很不容易达到。通常情况是掌握的知识有限,掌握的数据也有限,介乎这两者之间,我们只有通过这两种方法的结合来解决。
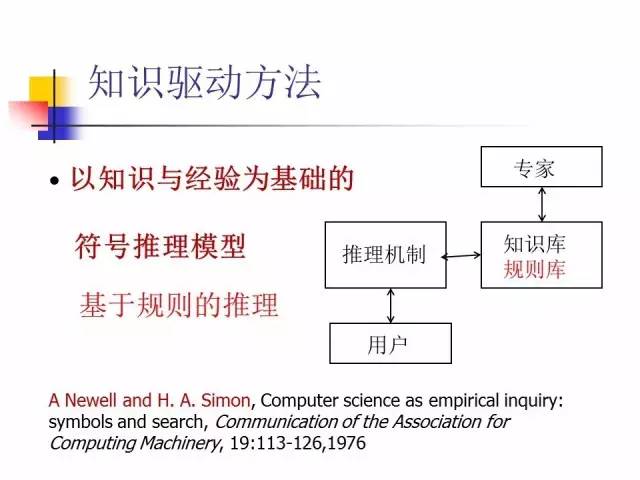

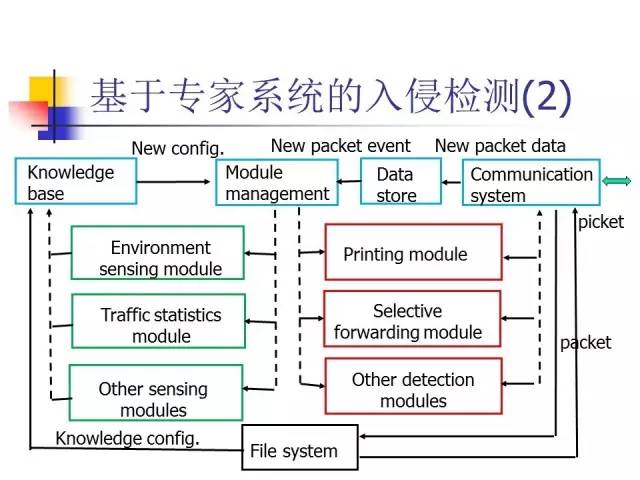
知识驱动方法:知识库+推理机制
知识驱动方法要建立很大的特征库(或知识库),但只有特征的知识是很不够的,所以基于专家系统的入侵检测的发展方向是,建立完善的知识库和推理机制,把我们对于入侵的了解变成一个知识,然后根据知识进行推理,这样就有可能去发现新的、没见过的入侵方式。这些工作正在研究过程中,最新研究表明:通过这些方法,确实可以对入侵进行更好的检测。
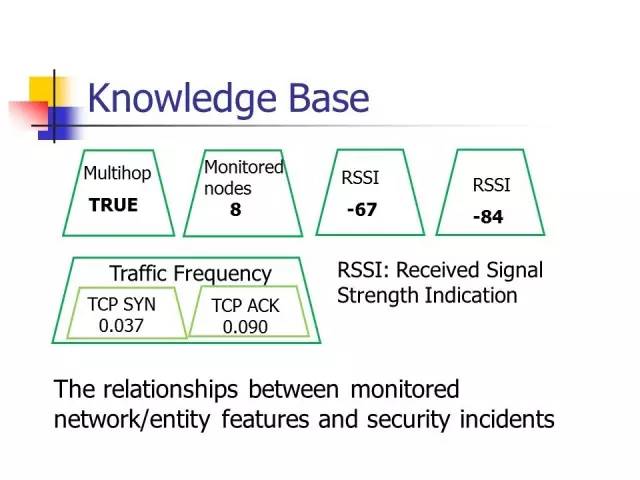
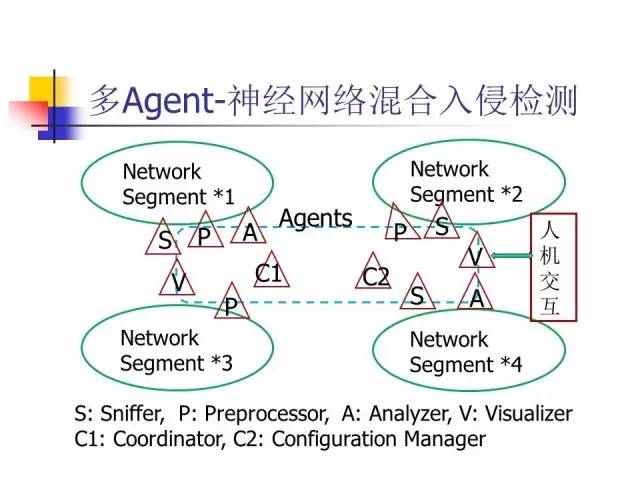

在深度学习的基础上,加上智能agent模块,就可以自动寻找特征和问题。将深度神经网络与agent技术结合在一起,体现了知识驱动跟数据驱动结合起来的方向。


AlphaGo的成功源自何处?
Alpha Go大家讲的非常多了,有些地方宣传得有点神秘。实际上,下围棋这件事对计算机来讲是不难的,对人来讲倒有些难。为什么对计算机来讲不难呢?因为它满足以下四个条件:确定性、完全性、问题边界清晰以及有大量的数据和经验。凡是满足这四条,对计算机来讲都比较容易,尽管这个问题可能非常复杂,但是计算机处理信息的速度比人快,因此做起来比人容易。过去为什么觉得难?因为没有找到一个合适的办法,因此过去的围棋程序只能跟业余棋手下,错在我们使用下象棋的方法来下围棋。
下象棋是利用知识与经验的推理过程。马这么走,大师们能说清楚为什么这么走。围棋不然,白子为什么落在这个地方?说不清楚,这是一种棋感或直觉。所以深蓝打败了卡斯帕洛夫,不是计算机打败了人类,而是大量的大师在一起打败了一个大师,因为编制和调整象棋程序时有很多象棋高手参与,包括利用了卡斯帕洛夫过去下棋的经验,所以深蓝实际上汇聚了许多大师的智慧,包括卡斯帕洛夫的智慧在内,打败了卡斯帕洛夫。
围棋不是如此,围棋的编程人员最高的是业余五段,少数懂得一点围棋,大多数人不懂围棋。所以Alpha Go打败了李世石或其他冠军,是真正意义上机器打败了人。为什么?我们从分析深度学习入手,深度学习取得成功来自三个因素:数据、计算能力(计算资源)和人工智能算法。人工智能算法是非常重要的,很多人忽视了,但我这里不讲,只讲数据。


AlphaGo的启示
首先把过去大师们下过的棋局学一遍,一共约3000万个棋局,用有监督学习方法,大概花了两个多礼拜。光有这一点,似乎难以与大师抗衡。关键是第二步,自己跟自己下,在跟李世石比赛之前,也就下了两三千万个棋局,所以李世石还能赢一盘。到后来跟其他大师下的时候,它已经下了接近20亿棋局。所以有时大师很尴尬,因为有的棋局大师们根本没有见过,但是Alpha Go已经下过很多次了。换句话说,人类大师一生中只能下百万级的棋局,而Alpha Go下过几十亿级的棋局。
亿级的棋局是如何生成?靠强化学习、自学习。这给我们启示:通过强化学习自己产生数据、自己学习。人工智能的方法可以帮助我们产生数据,可以产生真实数据(正样本)、也可以产生虚假数据(负样本),这就给入侵和反入侵同时提供机会。入侵者利用这一条,产生很多假数据欺骗计算机,防守方利用同样原理产生数据(真的和假的)来训练自己,提高鉴别能力。
这就是矛和盾的关系,没有永远安全的盾,也没有什么都能攻破的矛。人工智能给我们提供了机会,让矛与盾在相互对抗中发展。

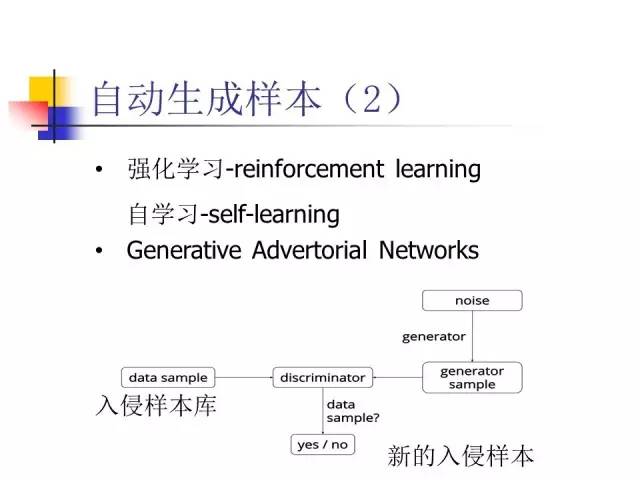
自动生成样本可以欺骗机器识别系统
我们看两个例子。第一个,阿拉伯数字手写体的识别,系统是用深度学习的方法构造的,能识别0到9手写体数字,声称这个系统的识别率比人还强。但是利用遗传算法产生一组样本,实际上是噪声。我们看左边第一列样本,计算机能以99.99%的确定性认定是0;第二列认定是1;第三列认定是2等等。也就是说,可以造出来假样本欺骗机器识别系统。即可以制造一套攻击的手段,让入侵检测系统误认为是正常的。


图像检测的例子
我们也可以采用产生式对抗网络生成入侵样本,让入侵检测系统把入侵样本误判为非入侵。我们以图像为例设想一下可能的做法,比如,可以产生一些假的(疑似)“人脸”、假的场景,让系统误认为是真的。然后我们用生成的正负(真假)样本,来训练神经网络,以提高它的检测性能。为了提高入侵检测的性能,我们必须把矛和盾、入侵和反入侵技术结合起来,才有可能做到:从“事后诸葛亮”到“防患于未然”。
信息安全需要走人机结合这条路,不能把人完全排除在外,攻击发生在瞬息之间,几个毫秒的差错就能够引起很大的危害,特别是机器本身(包括深度学习)并不完美,很容易受到攻击,很容易受到欺骗,很容易受到干扰。在这种情况下,人怎么介入?这涉及到人工智能另外一个大家非常关心的问题,就是”人机合作“。
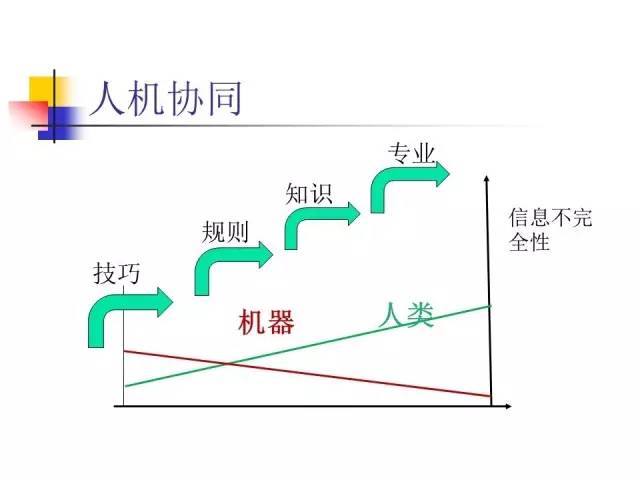
人机协同:走向可解释的人工智能
人机交互,过去大家比较强调的是“机器了解人”,现在看来这是不够的,更重要的是“人了解机器”。深度学习系统做出来的决策往往是不可解释的,人通常不理解。对于入侵检测来讲,有的时候并不知道机器做出的判断究竟是对还是错。所以今后人工智能的发展方向,是走向可解释的人工智能。系统必须告知人类:为什么它是一个入侵,把这个道理说出来。不仅能说what,还能说why。这是我们今后的方向。机器有了自我解释的能力,才能实现人机的结合。
总结:机器跟人类各有优缺点,简单、技巧性的工作机器做得比较好;涉及专业、知识等,人类就比较擅长。当然我们可以把知识、专业这些放到机器里面,让它像人一样来运用。但是机器毕竟随机应变的能力不如人类,这种情况下我们如何建造一个人机协同系统,是需要大家努力的。谢谢大家!
【现场提问环节】
提问:非常荣幸倾听您的报告。因为我现在做大数据,以后想往人工智能领域转,或者把大数据与人工智能结合,对我以后的研究方向有一些迷茫。能不能请您给我点拨点拨?
张钹:大数据有什么特点?过去大家讲到很多特点,核心都是围绕着数据量如何之大,变化如何之快等。其实这都没有抓住要害,其中有一条要害,并没有引起大家注意。因为我们现在讲的大数据特别是指网络上来自大众的数据,这个数据对人工智能才有意义。传统的气象数据,数据量也很大,但和我们这里谈的“大数据”有所不同。我们现在讲的大数据主要指生数据,即没有煮熟的(没有经过加工)的,不仅仅指非结构化,特别是指数据里面有价值的东西很少,大部分是无用的、比如造谣的、不符合事实的等等,这种数据我们过去没有遇到过。我们过去遇到是科学数据,最多在测量中引入一些噪声而已。这就给传统的处理方法带来困难。我们不能不遇到新的问题,比如,什么叫做“有用”?什么叫做“没用”?很难定义。也可以说,属于知其然不知其所以然的问题。
传统信息处理中的噪声很容易定义,比如,“白噪声”有很严格的数学定义,搞一个滤波器就很容易把它滤掉了。现在遇到了“垃圾邮件”,又怎么定义,什么是“垃圾”,什么是“非垃圾”?所以我们现在讲的大数据,确实需要用深度学习这类人工智能的方法来处理。
提问:非常感谢有机会跟您直接面对面学习。AI今后怎么走,您刚才讲的很多更多是基于集中式学习、基于中心化的,未来到5G或更广以后的网络空间,更多来自于边缘计算和分布式计算,怎么样和AI有一个结合点?
张钹:对分布式计算我不是很熟悉,我回答你前面一句话,人工智能今后怎么走?我讲过,人工智能现在比较容易解决的问题,需要满足四个条件:拥有大量的数据或知识;确定性;完备性(完全性或完全信息);单领域。这类问题只占现实问题的很小一部分。计算机容易解决的问题有,数值计算,下围棋(Alpha Go),下象棋(深蓝)等等属于这一类。如果这四个条件中有一个或者多个不满足,对人工智能来讲就困难了。所以人工智能未来研究的方向,就是当这四个条件中有一个或多个不满足时,我们怎么去解决它,这就主要涉及许多问题:
不确定信息的处理,不完全信息该如何处理等,下围棋、下象棋是完全信息,对方怎么下、你怎么下,大家都一清二楚,打桥牌就不是一回事了,这叫做不完全信息博弈,需要不同的解决办法。。
又比如领域扩大。最简单的例子是无人驾驶汽车,开始大家信心比较足,以为短期内就能实现。其实,马路的路况千变万化,是一种开放的环境,存在大量的不确定性和未知性的动态环境;车辆驾驶涉及的领域知识很宽,有马路、行人、自行车、路牌、信号灯等。现在的深度学习方法尽管本事很大,当遇到开放的环境时,也显得束手无策,因为机器不可能预先学习所有的路况,一旦出现新路况机器就难以应对了。
人工智能现在比较合理的做法是,我们不能只盯着“深度学习”这棵树,必须回过去想一想,人工智能在创立的前五十年都做了什么事,这些事今天不少是被遗忘和忽视了的。比如,知识表示、推理、强化学习、基于知识的学习等等。人工智能已经走过六十多年的路,我们不能只看到这十几年,而忘掉前五十年的历史,这段历史是由人工智能的先驱们开拓出来的,他们当时的想法多数并没有错,只是在当时的条件下,由于计算机能力弱、数据缺乏等原因,没有发展起来。我们应该回望前五十年的历史,重新审视当时的各种思想、方法与技术,把它们跟深度学习结合起来,以开拓人工智能的未来。
谢谢!




