权重不确定的概率线性回归
作者 | Ruben Winastwan
编译 | VK (磐创AI)
来源 | Towards Data Science

当你学习数据科学和机器学习时,线性回归可能是你遇到的第一个统计方法。我猜这不是你们第一次使用线性回归了。因此,在本文中,我想讨论概率线性回归,而不是典型的/确定性线性回归。
但在此之前,让我们简要讨论一下确定性线性回归的概念,以便快速了解本文的主要讨论要点。
线性回归是一种基本的统计方法,用来建立一个或多个输入变量(或自变量)与一个或多个输出变量(或因变量)之间的线性关系。
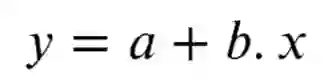
上式中,a为截距,b为斜率。x是自变量,y是因变量,也就是我们要预测的值。
a和b的值需要用梯度下降算法进行优化。然后,我们得到了一条自变量和因变量之间最合适的回归直线。通过回归线,我们可以预测任意输入x的y的值。这些是如何建立典型的或确定性的线性回归算法的步骤。
然而,这种确定性的线性回归算法并不能真正描述数据。这是为什么呢?
实际上,当我们进行线性回归分析时,会出现两种不确定性:
-
任意不确定性,即由数据产生的不确定性。 -
认知的不确定性,这是从回归模型中产生的不确定性。
我将在文章中详细阐述这些不确定性。考虑到这些不确定性,应采用概率线性回归代替确定性线性回归。
在本文中,我们将讨论概率线性回归以及它与确定性线性回归的区别。我们将首先看到确定性线性回归是如何在TensorFlow中构建的,然后我们将继续构建一个包含TensorFlow概率的概率线性回归模型。
首先,让我们从加载本文将使用的数据集开始。
加载和预处理数据
本文将使用的数据集是car的MPG数据集。像往常一样,我们可以用pandas加载数据。
import pandas as pd
auto_data = pd.read_csv('auto-mpg.csv')
auto_data.head()
以下是数据的统计汇总。
接下来,我们可以使用下面的代码查看数据集中变量之间的相关性。
import matplotlib.pyplot as plt
import seaborn as sns
corr_df = auto_data.corr()
sns.heatmap(corr_df, cmap="YlGnBu", annot = True)
plt.show()
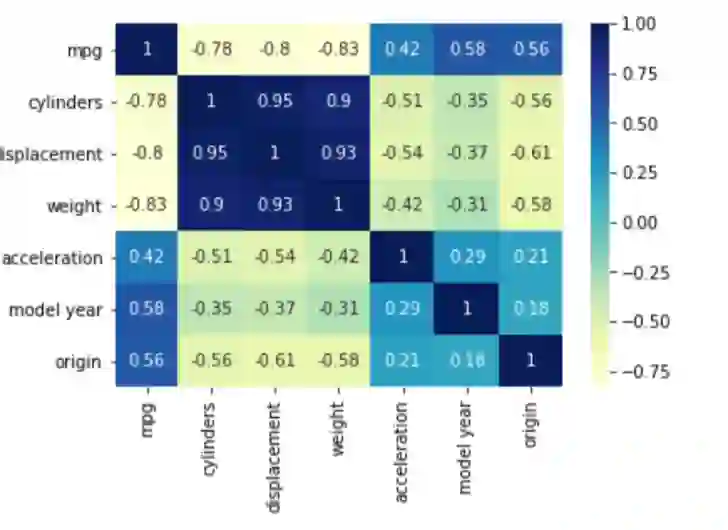
现在如果我们看一下相关性,汽车的每加仑英里数(MPG)和汽车的重量有很强的负相关性。
在本文中,为了可视化的目的,我将做一个简单的线性回归分析。自变量是车的重量,因变量是车的MPG。
现在,让我们用Scikit-learn将数据分解为训练数据和测试数据。拆分数据后,我们现在可以缩放因变量和自变量。这是为了确保两个变量在相同的范围内这也将提高线性回归模型的收敛速度。
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
x = auto_data['weight']
y = auto_data['mpg']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state=5)
min_max_scaler = preprocessing.MinMaxScaler()
x_train_minmax = min_max_scaler.fit_transform(x_train.values.reshape(len(x_train),1))
y_train_minmax = min_max_scaler.fit_transform(y_train.values.reshape(len(y_train),1))
x_test_minmax = min_max_scaler.fit_transform(x_test.values.reshape(len(x_test),1))
y_test_minmax = min_max_scaler.fit_transform(y_test.values.reshape(len(y_test),1))
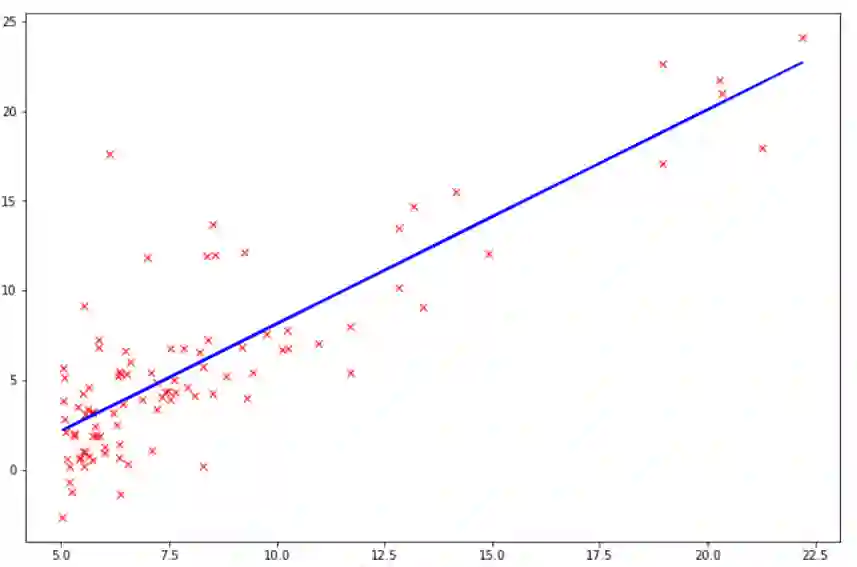
现在如果我们将训练数据可视化,我们得到如下可视化:
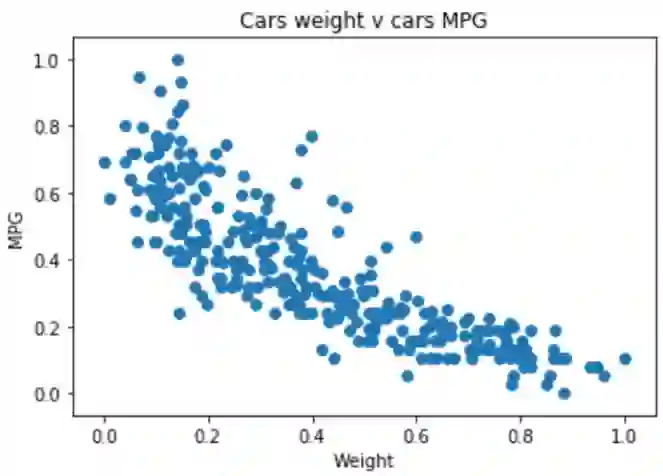
太棒了!接下来,让我们继续使用TensorFlow构建我们的确定性线性回归模型。
基于TensorFlow的确定性线性回归
用TensorFlow建立一个简单的线性回归模型是非常容易的。我们所需要做的就是建立一个没有任何激活函数的单一全连接层模型。对于成本函数,通常使用均方误差。在本例中,我将使用RMSprop作为优化器,模型将在100个epoch内进行训练。我们可以用下面的几行代码构建和训练模型。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.losses import MeanSquaredError
model = Sequential([
Dense(units=1, input_shape=(1,))
])
model.compile(loss=MeanSquaredError(), optimizer=RMSprop(learning_rate=0.01))
history = model.fit(x_train_minmax, y_train_minmax, epochs=100, verbose=False)
在我们训练了模型之后,让我们看看模型的损失来检查损失的收敛性。
def plot_loss(history):
plt.plot(history.history['loss'], label='loss')
plt.xlabel('Epoch')
plt.ylabel('Error')
plt.legend()
plt.grid(True)
plot_loss(history)
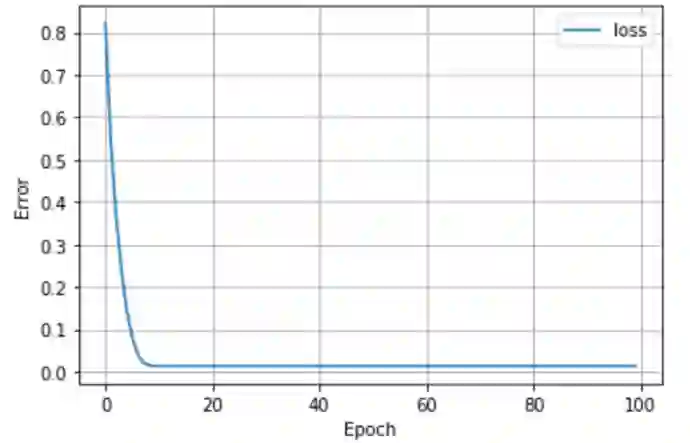
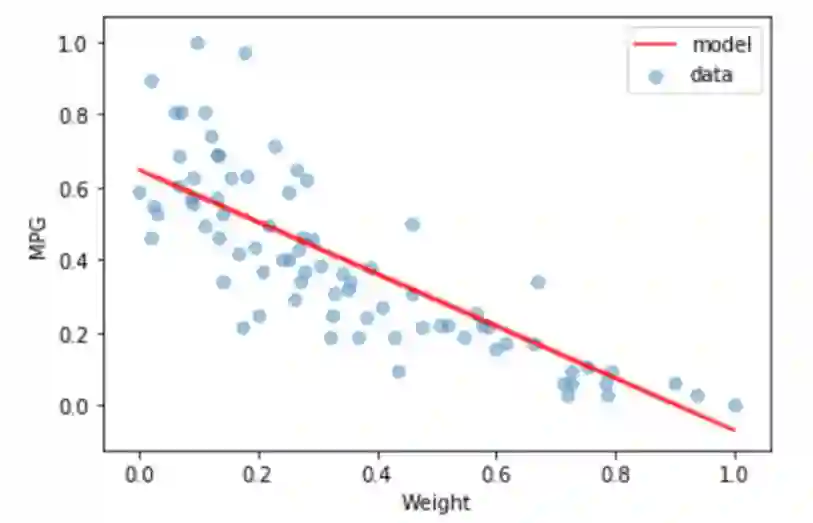
看来损失已经收敛了。现在,如果我们使用训练过的模型来预测测试集,我们可以看到下面的回归线。
就是这样。我们完成了!
正如我前面提到的,使用TensorFlow构建一个简单的线性回归模型是非常容易的。有了回归线,我们现在可以在任何给定的汽车的重量输入来近似的汽车的MPG。举个例子,假设特征缩放后的汽车重量是0.64。通过将该值传递给训练过的模型,我们可以得到相应的汽车MPG值,如下所示。

现在你可以看到,模型预测汽车的MPG是0.21。简单地说,对于任何给定的汽车重量,我们得到一个确定的汽车MPG值
然而,输出并不能说明全部问题。这里我们应该注意两件事。首先,我们只有有限的数据点。第二,正如我们从线性回归图中看到的,大多数数据点并不是真的在回归线上。
虽然我们得到的输出值是0.21,但我们知道实际汽车的MPG不是确切的0.21。它可以略低于这个值,也可以略高于这个值。换句话说,需要考虑到不确定性。这种不确定性称为任意不确定性。
确定性线性回归不能捕捉数据的任意不确定性。为了捕捉这种任意的不确定性,可以使用概率线性回归代替。
「TensorFlow」概率的概率线性回归
由于有了TensorFlow概率,建立概率线性回归模型也非常容易。但是,你需要首先安装tensorflow_probability库。你可以使用pip命令安装它,如下所示:
pip install tensorflow_probability
安装此库的先决条件是你需要拥有TensorFlow 2.3.0版本。因此,请确保在安装TensorFlow Probability之前升级你的TensorFlow版本。
针对不确定性建立概率线性回归模型
在本节中,我们将建立一个考虑不确定性的概率线性回归模型。
这个模型与确定性线性回归非常相似。但是,与之前只使用一个单一的全连接层不同,我们需要再添加一个层作为最后一层。最后一层将最终输出值从确定性转换为概率分布。
在本例中,我们将创建最后一层,它将输出值转换为正态分布的概率值。下面是它的实现。
import tensorflow_probability as tfp
import tensorflow as tf
tfd = tfp.distributions
tfpl = tfp.layers
model = Sequential([
Dense(units=1+1, input_shape=(1,)),
tfpl.DistributionLambda(
lambda t: tfd.Normal(loc=t[..., :1],
scale=tf.math.softplus(t[...,1:]))),
])
注意,我们在最后应用了一个额外的层TensorFlow概率层。该层将前一个全连接层的两个输出(一个为均值,一个为标准差)转化为具有可训练均值(loc)和标准差(scale)正态分布的概率值。
我们可以使用RMSprop作为优化器,但是如果你愿意,你也可以使用其他优化器。对于损失函数,我们需要使用负对数似然。
但是为什么我们使用负对数似然作为损失函数呢
负对数似然作为成本函数
为了对一些数据拟合一个分布,我们需要使用似然函数。通过似然函数,我们在给定我们在数据中尝试估计未知的参数(例如,正态分布数据的平均值和标准差)。

在我们的概率回归模型中,优化器的工作是找到未知参数的最大似然估计。换句话说,我们训练模型从我们的数据中找到最有可能的参数值。
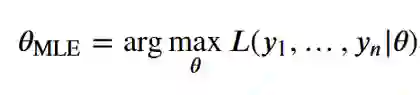
最大化似然估计和最小化负对数似然是一样的。在优化领域,通常目标是最小化成本而不是最大化成本。这就是为什么我们使用负对数似然作为代价函数。
下面是实现的负对数似然作为我们的自定义损失函数。
def negative_log_likelihood(y_true, y_pred):
return -y_pred.log_prob(y_true)
随机不确定性概率线性回归模型的训练与预测结果
现在我们已经构建了模型并定义了优化器以及loss函数,接下来让我们编译并训练这个模型。
model.compile(optimizer=RMSprop(learning_rate=0.01), loss=negative_log_likelihood)
history = model.fit(x_train_minmax, y_train_minmax, epochs=200, verbose=False);
现在我们可以从训练好的模型中抽取样本。我们可以通过下面的代码可视化测试集和从模型生成的示例之间的比较。
y_model = model(x_test_minmax)
y_sample = y_model.sample()
plt.scatter(x_test_minmax, y_test_minmax, alpha=0.5, label='test data')
plt.scatter(x_test_minmax, y_sample, alpha=0.5, color='green', label='model sample')
plt.xlabel('Weight')
plt.ylabel('MPG')
plt.legend()
plt.show()
正如你从上面的可视化中看到的,现在对于任何给定的输入值,模型都不会返回确定性值。相反,它将返回一个分布,并基于该分布绘制一个样本。
如果你比较测试集的数据点(蓝点)和训练模型预测的数据点(绿点),你可能会认为绿点和蓝点来自相同的分布。
接下来,我们还可以可视化训练模型生成的分布的均值和标准差,给定训练集中的数据。我们可以通过应用以下代码来实现这一点。
y_mean = y_model.mean()
y_sd = y_model.stddev()
y_mean_m2sd = y_mean - 2 * y_sd
y_mean_p2sd = y_mean + 2 * y_sd
plt.scatter(x_test_minmax, y_test_minmax, alpha=0.4, label='data')
plt.plot(x_test_minmax, y_mean, color='red', alpha=0.8, label='model $\mu$')
plt.plot(x_test_minmax, y_mean_m2sd, color='green', alpha=0.8, label='model $\mu \pm 2 \sigma$')
plt.plot(x_test_minmax, y_mean_p2sd, color='green', alpha=0.8)
plt.xlabel('Weight')
plt.ylabel('MPG')
plt.legend()
plt.show()
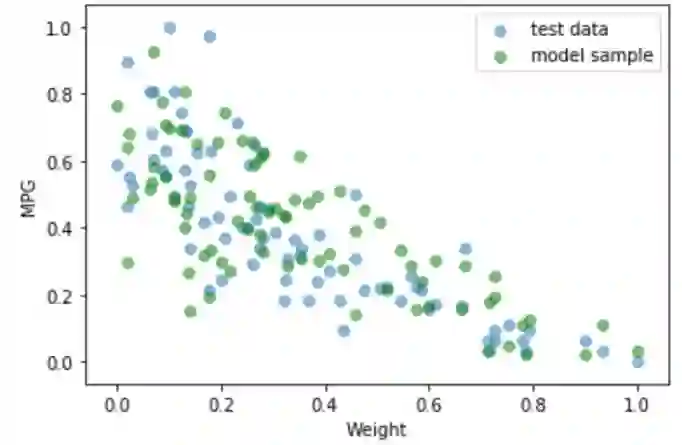
我们可以看到,概率线性回归模型给我们比回归线更多。它也给出了数据的标准差的近似值。可以看出,大约95%的测试集数据点位于两个标准差范围内。
建立随机和认知不确定性的概率线性回归模型
到目前为止,我们已经建立了一个概率回归模型,它考虑了来自数据的不确定性,或者我们称之为任意不确定性。
然而,在现实中,我们还需要处理来自回归模型本身的不确定性。由于数据的不完善,回归参数的权重或斜率也存在不确定性。这种不确定性称为认知不确定性。
到目前为止,我们建立的概率模型只考虑了一个确定的权重。正如你从可视化中看到的,模型只生成一条回归线,而且这通常不是完全准确的。
在本节中,我们将改进同时考虑任意和认知不确定性的概率回归模型。我们可以使用贝叶斯的观点来引入回归权值的不确定性。
首先,在我们看到数据之前,我们需要定义我们之前对权重分布的看法。通常,我们不知道会发生什么,对吧?为了简单起见,我们假设权值的分布是正态分布均值为0,标准差为1。
def prior(kernel_size, bias_size, dtype=None):
n = kernel_size + bias_size
return Sequential([
tfpl.DistributionLambda(lambda t: tfd.Independent(
tfd.Normal(loc=tf.zeros(n), scale=tf.ones(n))))
])
由于我们硬编码了平均值和标准差,这种先验是不可训练的。
接下来,我们需要定义回归权重的后验分布。后验分布显示了我们的信念在看到数据中的模式后发生了怎样的变化。因此,该后验分布中的参数是可训练的。下面是定义后验分布的代码实现。
def posterior(kernel_size, bias_size, dtype=None):
n = kernel_size + bias_size
return Sequential([
tfpl.VariableLayer(2 * n, dtype=dtype),
tfpl.DistributionLambda(lambda t: tfd.Independent(
tfd.Normal(loc=t[..., :n],
scale=tf.nn.softplus(t[..., n:]))))
])
现在的问题是,这个后验函数中的变量定义是什么?这个可变层背后的想法是我们试图接近真实的后验分布。一般情况下,不可能推导出真正的后验分布,因此我们需要对其进行近似。
在定义了先验函数和后验函数后,我们可以建立权重不确定性的概率线性回归模型。下面是它的代码实现。
model = Sequential([
tfpl.DenseVariational(units = 1 + 1,
make_prior_fn = prior,
make_posterior_fn = posterior,
kl_weight=1/x.shape[0]),
tfpl.DistributionLambda(
lambda t: tfd.Normal(loc=t[..., :1],
scale=tf.math.softplus(t[...,1:])))
])
正如你可能注意到的,此模型与前面的概率回归模型之间的唯一区别只是第一层。我们用DenseVariational层代替了普通的全连接层。在这一层中,我们通过前面和后面的函数作为参数。第二层与前面的模型完全相同。
随机不确定性和认知不确定性概率线性回归模型的训练和预测结果
现在是时候编译和训练模型了。
优化器和成本函数仍然与以前的模型相同。我们使用RMSprop作为优化器和负对数似然作为我们的成本函数。让我们编译和训练。
model.compile(optimizer= RMSprop(learning_rate=0.01), loss=negative_log_likelihood)
history = model.fit(x_train_minmax, y_train_minmax, epochs=500, verbose=False);
现在是时候可视化回归模型的权值或斜率的不确定性了。下面是可视化结果的代码实现。
plt.scatter(x_test_minmax, y_test_minmax, marker='.', alpha=0.8, label='data')
for i in range(10):
y_model = model(x_test_minmax)
y_mean = y_model.mean()
y_mean_m2sd = y_mean - 2 * y_model.stddev()
y_mean_p2sd = y_mean + 2 * y_model.stddev()
if i == 0:
plt.plot(x_test_minmax, y_mean, color='red', alpha=0.8, label='model $\mu$')
plt.plot(x_test_minmax, y_mean_m2sd, color='green', alpha=0.8, label='model $\mu \pm 2 \sigma$')
plt.plot(x_test_minmax, y_mean_p2sd, color='green', alpha=0.8)
else:
plt.plot(x_test_minmax, y_mean, color='red', alpha=0.8)
plt.plot(x_test_minmax, y_mean_m2sd, color='green', alpha=0.8)
plt.plot(x_test_minmax, y_mean_p2sd, color='green', alpha=0.8)
plt.xlabel('Weight')
plt.ylabel('MPG')
plt.legend()
plt.show()
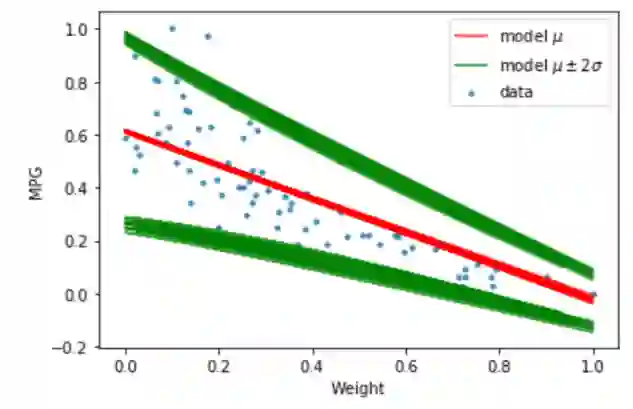
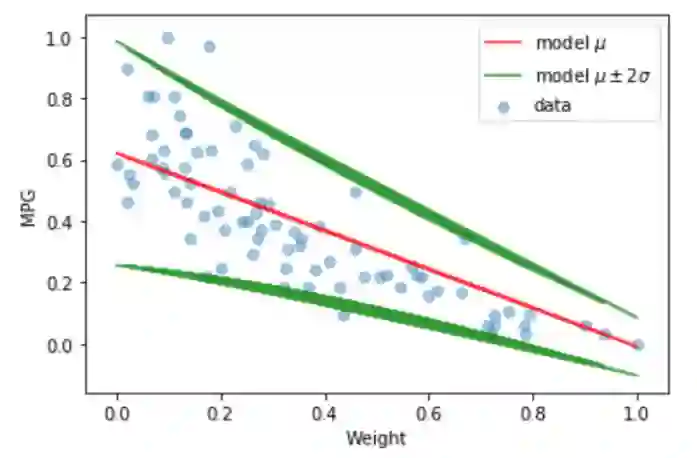
在上面的可视化图中,你可以看到,经过训练的模型的后验分布产生的线性线(均值)和标准差在每次迭代中都是不同的。所有这些线都是拟合测试集中数据点的合理解决方案。但是,由于认知的不确定性,我们不知道哪条线是最好的。
通常,我们拥有的数据点越多,我们看到的回归线的不确定性就越小。
今晚
现在你已经看到了概率线性回归与确定性线性回归的不同之处。在概率线性回归中,两种不确定性产生于数据(任意)和回归模型(认知)可以被考虑在内。
如果我们想建立一个深度学习模型,让不准确的预测导致非常严重的负面后果,例如在自动驾驶和医疗诊断领域,考虑这些不确定性是非常重要的。
通常,当我们有更多的数据点时,模型的认知不确定性将会减少。
原文链接:https://towardsdatascience.com/probabilistic-linear-regression-with-weight-uncertainty-a649de11f52b
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT
![]()
后台回复【南大模式识别】




由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!




