加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源:AI科技评论@微信公众号
作者:Chip Huyen
编译:MrBear
作为 2019 年最后一场重量级的人工智能国际学术顶会,NeurIPS 2019 所反映出的一些人工智能研究趋势,例如神经网络可解释性、深度学习新方法、神经科学等等,想必对于大家在新的一年开展研究工作,具有一定的借鉴和参考价值。
NeurIPS 2019 共举办 51 场研讨会,接收了 1,428 篇论文,以及有超过 13,000 名参会者,可谓万众瞩目。
来自英伟达的工程师小姐姐 Chip Huyen 基于自己的参会体验,较为全面地总结了 NeurIPS 2019 反映的关键研究趋势。
一、 解构深度学习的黑盒
最近,研究人员对深度学习的局限性进行了大量的反思,以下为几个例子:
Facebook 的人工智能总监表达了对算力达到瓶颈的担忧。人工智能企业不应该仅仅寄希望于通过更大的深度学习系统来不断取得进步,因为「现在,一个实验可能要花费七位数的金钱,但现实情况不会让这一数字增长到九位数或十位数,因为没人负担得起这样的开销」。
Yoshua Bengio 指出以 Gary Marcus 为代表的一些人经常强调深度学习的局限性,他将 Gary Marcus 的观点总结为「你们看,我就说深度学习不行吧」,而 Gary Marcus 后来则反驳了这种说法。
针对这一趋势,Yann Lecun 谈到:「我不明白,为什么突然之间,我们看到了许多新闻和推特声称人工智能的进步正在放缓,或称深度学习正在碰壁。在过去的五年中,我几乎在每一次演讲上都会指出这两个局限和挑战。所以,认识到这些局限性并不是什么新鲜事。而且,实际上人工智能的发展并没有慢下来」。
在这种大环境下,我们很高兴看到探究深度学习背后的理论(深度学习为何有效?它是如何工作的?)的论文的数量迎来了爆炸式增长。
在今年的 NeurIPS 上,有 31 篇融合了各种技术的论文。本届大会的杰出新方向论文奖授予了 Baishnavh 和 J.Zico Kolter 的论文「Uniform convergence may be unable to explain generalization in deep learning」。
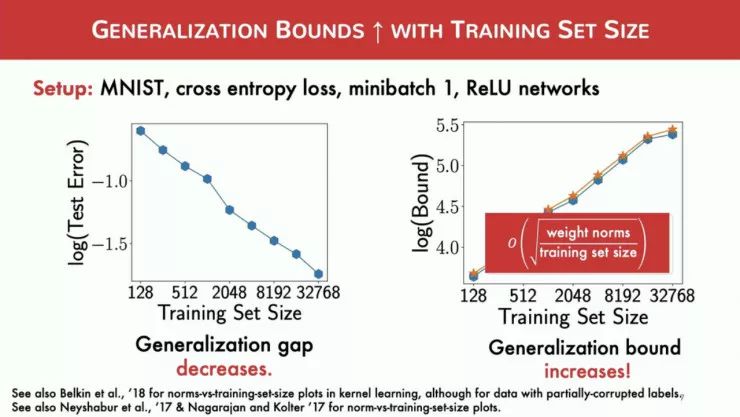
他们认为一致收敛理论本身并不能解释深度学习的泛化能力。随着数据集的规模增大,泛化差异(Generalization Gap,模型在见过和未见过的数据上的性能差异)的理论界限也会增大,而经验泛化差异则会减小。
-
论文链接
:
https://arxiv.org/abs/1902.04742
神经切线核(NTK)是近年来提出的一个研究方向,旨在理解神经网络的优化和泛化。
有关 NTK 的讨论多次出现在本届 NeurIPS 的亮点演讲中,我在 NeurIPS 期间也与其他人多次谈到 NTK。
Arthur Jacot 等人提出了「全连接的神经网络等价于宽度无限时的高斯过程」这一众所周知的概念,能够在函数空间而不是参数空间中研究它们的训练动力学(Training Dynamics)。
他们证明了「在人工神经网络参数梯度下降的过程中,网络函数(将输入向量映射到输出向量)遵循关于一种新的核——NTK的函数代价的核梯度」。他们还表明,当我们使用梯度下降法训练一个有限层版本的 NTK 时,其性能将收敛到宽度无限的 NTK 上,然后在训练中性能保持不变。
下面,我们列出本届 NeurIPS 上一些基于 NTK 构建的论文:
-
Learning and Generalization in Overparameterized Neural Networks, Going Beyond Two Layers
论文链接:
https://arxiv.org/abs/1811.04918
-
On the Inductive Bias of Neural Tangent Kernels
论文链接
:
http://papers.nips.cc/paper/9449-on-the-inductive-bias-of-neural-tangent-kernels
然而,许多人认为 NTK 不能完全解释深度学习。一个神经网络要接近 NTK 状态需要具备学习率小、初始化宽度大、无权值衰减等超参数设置,而在实际训练中并不经常使用这样的设置。
NTK 的观点还认为,神经网络只会像核方法一样泛化。但根据我们的经验来看,它们可以更好地泛化。
Colin Wei 等人的论文「Regularization Matters: Generalization and Optimization of Neural Nets v.s. their Induced Kernel」从理论上证明了带有权值衰减的神经网络具有比 NTK 更好的泛化能力,这说明研究 L2 正则化神经网络可以为泛化问题提供更好的研究思路。此论文链接:
-
https://nips.cc/Conferences/2019/Schedule?showEvent=14579
本届 NeurIPS 上也有几篇论文说明了,传统的神经网络可以具有比 NTK 更好的性能:
-
What Can ResNet Learn Efficiently, Going Beyond Kernels?
论文链接
:
http://papers.nips.cc/paper/9103-what-can-resnet-learn-efficiently-going-beyond-kernels
-
Limitations of Lazy Training of Two-layers Neural Network
论文链接
:
http://papers.nips.cc/paper/9111-limitations-of-lazy-training-of-two-layers-neural-network
许多论文分析了神经网络的不同组成部分的表现。比如,Chulhee Yun 等人提出了「Small ReLU networks are powerful memorizers: a tight analysis of memorization capacity」,说明了「带有 O(sqrt(N)) 个隐藏节点的 3 层的 ReLU 网络可以完美地记忆大多数带有 N 个数据点的数据集」。
-
论文链接
:
https://arxiv.org/abs/1810.07770
Shirin Jalali 等人在论文「Efficient Deep Learning of Gaussian Mixture Models」中,开篇就提出了这样一个问题:通用近似定理(Universal approximation theorem,一译万能逼近定理)表明,任何正则函数都可以通过一个单隐层神经网络近似。
-
论文链接
:
https://papers.nips.cc/paper/8704-efficient-deep-approximation-of-gmms
那么,增加深度能让它更有效率吗?他们说明了,在高斯混合模型的最优贝叶斯分类的情况下,这些函数可以用带有单个隐层的神经网络中的 o (exp (n)) 个节点以任意精度近似,而在两层网络中只需要用 o (n) 个节点近似。
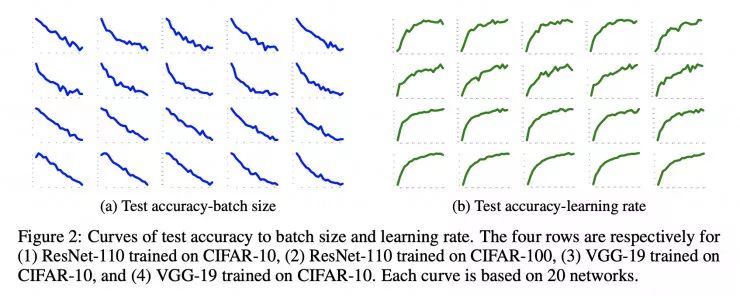
在一篇更为实用的论文「Control Batch Size and Learning Rate to Generalize Well: Theoretical and Empirical Evidence」中,Fengxiang He 和他的团队在 CIFAR 数据集上使用随机梯度下降算法(SGD)训练了 1,600 个 ResNet-110 模型和 VGG-19 模型,发现这些模型的泛化能力与批处理大小呈负相关,与学习率呈正相关,与「批处理大小/学习率」的比值呈负相关。
-
论文链接
:
https://papers.nips.cc/paper/8398-control-batch-size-and-learning-rate-to-generalize-well-theoretical-and-empirical-evidence
图 2:测试准确率与批处理大小、学习率的诶关系。第四行分别是(1)使用 CIFAR-10 数据集训练的 ResNet-110 模型(2)使用 CIFAR-100 数据集训练的 ResNet-110 模型(3)使用 CIFAR-10 数据集训练的 VGG-19 模型(4)使用 CIFAR-100 数据集训练的 VGG-19 模型。每条曲线都是根据 20 个网络的情况综合绘制而出。
与此同时,Yuanzhi Li 等人的论文「Towards Explaining the Regularization Effect of Initial Large Learning Rate in Training Neural Networks」指出:「一个具有较大的初始学习率并使用退火算法训练的双层网络,比使用较小的初始学习率训练的相同的网络具有更好的泛化性能。这是因为学习率较小的模型首先会记忆低噪声、难以拟合的模式,它在较高噪声、易于拟合的情况下的泛化性能比学习率较大的情况下差一些。」
-
论文链接:
https://arxiv.org/abs/1907.04595
尽管这些理论分析非常吸引人,也很重要,但是很难讲它们聚合成一个大的研究体系,因为这其中的一个研究都集中在整个系统的一个较为狭窄的方面。
二、深度学习新方法
在今年的 NeurIPS 上,研究者们提出了一系列新颖的方法,而不仅仅是在别人的工作上叠加新的网络层。新提出的研究深度学习的方法中,我感兴趣的三个方向是:贝叶斯学习、图神经网络以及凸优化。
正如 Emtiyaz Khan 在他的演讲「Deep Learning with Bayesian Principles」中所强调的,贝叶斯学习和深度学习是有很大的而区别。
根据 Khan 的说法,
深度学习使用的是一种「试错」的方法,我们通过实验看看会得到什么结果,然而贝叶斯原理迫使你事先考虑一个假设(先验)
。
与常规的深度学习相比,贝叶斯深度学习有两个主要的优势:非确定性估计以及在小数据集上更好的泛化性能。
在现实世界的应用中,让系统能够进行预测是远远不够的。弄明白每个预测的可靠性是很重要的。例如,对癌症进行预测时,可靠性为 50.1% 和可靠性为 99.9% 时的治疗方案是不同的。在贝叶斯学习中,非确定性估计是一个内在的特质。
传统的神经网络给出的是单点估计——它们使用一组权值针对一个数据点输出一个预测。另一方面,贝叶斯神经网络使用一个关于网络权重的概率分布,并输出该分布中所有权重组合的平均预测值,这与对许多神经网络求平均的效果相同。
因此,贝叶斯神经网络是一种自然的集成,它的作用类似于正则化,并且能够防止过拟合。
训练具有数百万参数的贝叶斯神经网络仍然需要非常大的计算开销。要想使网络收敛到一个后验上可能需要花费数周的时间,因此诸如变分推断这样的近似方法越来越流行。本届 NeurIPS 的「概率方法-变分推断」环节共有 10 篇论文与这类变分贝叶斯方法有关。
下面是向大家推荐的本届 NeurIPS 上有关贝叶斯深度学习的 3 篇论文:
-
Importance Weighted Hierarchical Variational Inference
论文链接:
https://arxiv.org/abs/1905.03290
-
A Simple Baseline for Bayesian Uncertainty in Deep Learning
论文链接:
https://arxiv.org/abs/1902.02476
-
Practical Deep Learning with Bayesian Principles,
论文链接:
https://arxiv.org/abs/1906.02506
多年来,我经常谈到:图论是在机器学习领域最被低估的课题之一。我很高兴有关图的工作在本届 NeurIPS 上大放异彩。
「图表征学习」是本届 NeurIPS 上最受欢迎的研讨会。令人惊讶的是,该领域已经取得了如此大的进步。
时间回到 2015 年,当我在实习期间开始研究图神经网络时,我没有想到会有如此多的研究人员参与到这个领域中来。
图是适用于许多种数据(例如,社交网络、知识库、游戏的状态)的优雅而自然的表征形式。
用于推荐系统的「用户-物品」数据可以被表示为一个二分图,其中一个不相交的集合由用户组成,另一个由物品组成。
图也可以表征神经网络的输出。正如 Yoshua Bengio 在他的演讲中提醒人们的那样:任何联合分布都可以通过因子图来表示。
这使得图神经网络能够完美地适应组合优化(例如,旅行商问题、任务调度问题)、身份匹配(在这种问题中 Twitter 用户和 Facebook 的用户是一样的吗?)、推荐系统等任务。
目前最流行的图神经网络是图卷积神经网络(GCNN),
这是意料之中的,因为图和卷积都可以编码局部的信息。卷积以寻找输入中邻近部分之间的关系为目标编码一种偏置。而图通过边对输入中关系最密切的部分进行编码。
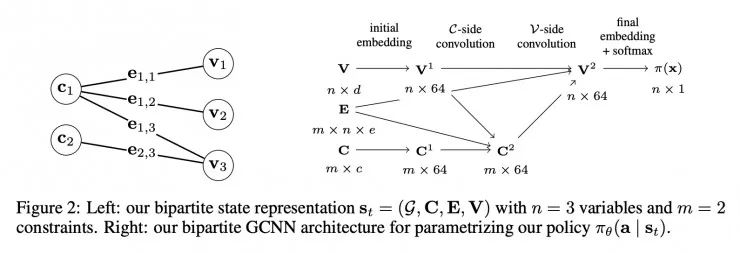
图 4:(左图)二分图 St=(G,C,E,V)有 n=3 个变量和 m=2 个常量。(右图)用于将策略πθ(a|st)参数化的二分图 GCNN 架构。
-
Exact Combinatorial Optimization with Graph Convolutional Neural Networks
论文链接:
https://arxiv.org/abs/1906.01629
-
今年有一篇论文融合了 NTK 和图神经网络两个最热门的研究趋势:Graph Neural Tangent Kernel: Fusing Graph Neural Networks with Graph Kernels,
论文链接:
https://arxiv.org/abs/1905.13192
-
本届NeurIPS 上我最喜欢的海报展示:(Nearly) Efficient Algorithms for the Graph Matching Problem on Correlated Random Graphs,
论文链接:
https://arxiv.org/abs/1805.02349
图 5:(Nearly) Efficient Algorithms for the Graph Matching Problem on Correlated Random Graphs
-
Thomas N. Kipf 关于图卷积网络的博文(https://tkipf.github.io/graph-convolutional-networks/)
-
Kung-Hsiang,Huang 对图神经网络(Basics,DeepWalk,GraphSage)简介(https://towardsdatascience.com/a-gentle-introduction-to-graph-neural-network-basics-deepwalk-and-graphsage-db5d540d50b3)
我一直默默推崇 Stephen Boyd 关于凸优化的工作,所以很高兴看到它在 NeurIPS 上越来越受欢迎。在今年的 NeurIPS 上,有 32 篇论文是关于这个主题的。
Stephen Boyd 和 j. Zico Kolter 的实验室也展示了他们的论文「Differentiable Convex Optimization Layers」,该论文说明了如何通过凸优化问题的解来进行微分,这使得将它们可以被嵌入可微分的程序(如神经网络)并根据数据进行学习。
-
论文链接:
http://papers.nips.cc/paper/9152-differentiable-convex-optimization-layers
凸优化问题之所以吸引人,是因为它们可以被精确地求解(可以实现 1e-10 的容错率),而且速度很快。它们也不会产生奇怪的或意料之外的输出,而这对于现实世界中的应用是至关重要的。尽管在真实场景中遇到的许多问题是非凸的,但是将它们分解为一系列凸问题可以达到很好的效果。
神经网络也使用凸优化的算法进行训练。然而,神经网络重点强调以一种端到端的方式从头进行学习,而凸优化问题的应用则显式地使用领域特定的知识对系统建模。如果能够以凸方法对系统进行显式建模,那么通常所需的数据就会少得多。
关于可微凸优化层的工作是将端到端学习和显式建模的优势结合起来的一种方法。
当你想要控制一个系统的输出时,凸优化特别有用。例如,SpaceX 公司使用凸优化来发射火箭,BlackRock 公司将它用于交易算法。看到凸优化在深度学习中的应用真的很酷,就像现在的贝叶斯学习一样。
下面是 Akshay Agrawal 推荐的一些有关凸优化的 NeurIPS 论文:
-
Acceleration via Symplectic Discretization of High-Resolution Differential Equations
论文链接
:
https://papers.nips.cc/paper/8811-acceleration-via-symplectic-discretization-of-high-resolution-differential-equations
-
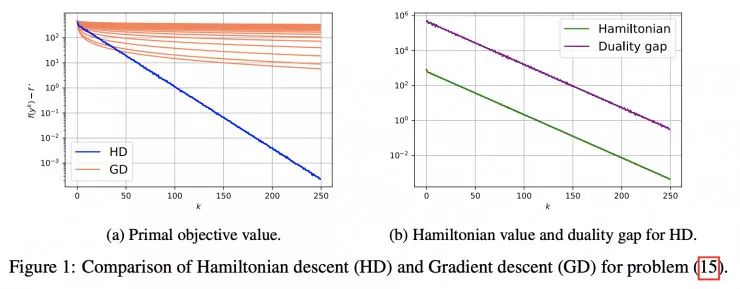
Hamiltonian descent for composite objectives
论文链接
:
http://papers.nips.cc/paper/9590-hamiltonian-descent-for-composite-objectives
图 6:用于问题
![]() 的Hamiltonian 下降(HD)和梯度下降算法的对比情况
的Hamiltonian 下降(HD)和梯度下降算法的对比情况
三、神经科学 x 机器学习
根据 NeurIPS 2019 程序委员会主席 Hugo Larochelle 的分析,接收率最高的论文类别是神经科学。在Yoshua Bengio的演讲「From System 1 Deep Learning to System 2 Deep Learning」和 Blaise Aguera y Arcas的演讲「Social Intelligence」中,他们都敦促机器学习研究社区更多地思考自然智能的生物学根源。
Bengio 的演讲将「意识」引入了主流的机器学习词汇体系中。Bengio 提出的「意识」概念的核心是注意力。他将机器注意力机制与我们的大脑选择分配注意力的方式进行了比较:
「机器学习可以用来帮助脑科学家更好地理解意识,但我们对意识的理解也可以帮助机器学习发展出更好的能力」
。
根据 Bengio 的说法,如果我们希望机器学习算法能够泛化到分布之外的样本上,那么受意识启发的方法可能是一种解决方案。
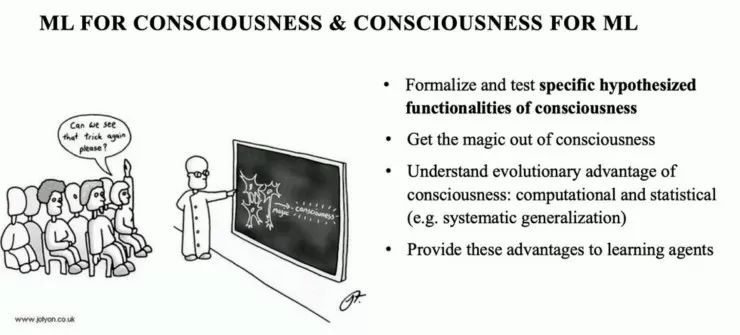
图 8:将机器学习用于意识&将意识用于机器学习——(1)形式化定义并测试特定的意识的假设函数(2)揭开意识的神秘面纱(3)从计算和统计的角度(例如,系统的泛化)理解意识演化的优势(4)将这些优势应用于学习智能体。
在本届大会上,我最喜欢 Aguera y Arcas 的演讲。他的演讲在理论上非常严谨,但同时也是可行的。他认为
通过优化方法不足以获得类似于人类的智力
:「优化不是生命体工作的方式,大脑不仅仅是在评估一个函数。它们会发展。它们会自我修正。他们从经验中学习。仅仅通过一个函数并不能包含这些东西」。
他呼吁人们研究「一种更通用的、受生物学启发的突触更新规则,它允许使用损失函数和梯度下降法,但并不要求一定要这么做」。
NeurIPS 上的这一趋势与我观察到的现象不谋而合:
很多人工智能界的研究人员正转而研究神经科学。他们把神经科学重新带回了机器学习领域。
有些我所熟知的智者纷纷离开了人工智能研究领域,投身工业界或神经科学领域。这是为什么呢?
1. 我们需要理解人类学习的机制,从而教导机器进行学习。
2. 科学研究应该是一个从假设到实验的过程,而如今的人工智能研究则往往是先做实验然后证明结果成立。
四、关键词分析
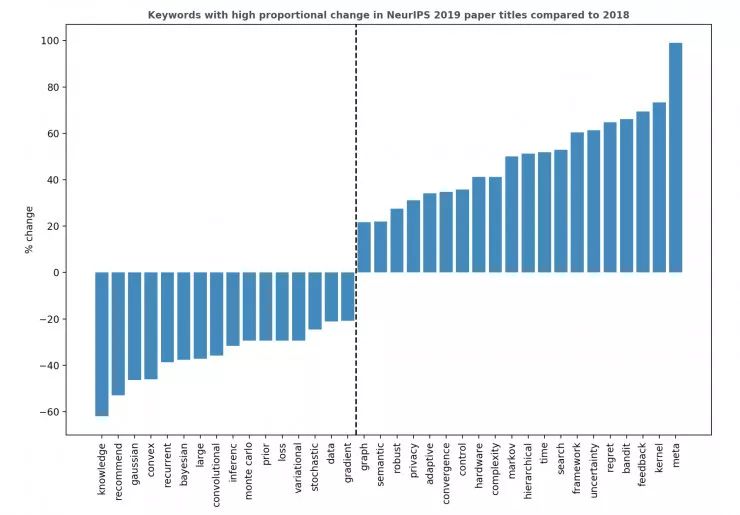
让我们从更宏观的角度看看本届 NeurIPS 大会上的论文都与什么主题相关。首先,我使用 Vennclods 将 1,011 份 NeurIPS 2018 的论文和 1,428 份 NeurIPS 2019 的论文的标题进行了可视化。中间黑色的部分是在这两年都十分常见的论文关键词的列表。
接着,如下图所示,我计算出了这些关键词从 2018 年到 2019 年的百分比变化。例如,如果在2018年,所有被接收的论文中有 1% 包含关键词「X」,而在2019年,这个数字是 2% ,那么这一比例的变化是(2-1) / 1=100% 。在下图中,我将绝对比例变化在 20% 以上的关键词绘制了出来。
-
即使是在机器人领域之外,强化学习也得到了进一步发展。具有显著正向变化的关键词有:多臂老虎机、反馈、遗憾值、控制。
-
生成模型依然很流行。GAN 仍然吸引着我们的想象力,但是炒作变少了。
-
循环神经网络和卷积神经网络依然延续了去年的下降趋势。
-
与硬件相关的关键词也在增加,这表明有更多考虑到硬件的算法诞生。这是解决「硬件成为机器学习瓶颈」这一问题的方法。
-
令人遗憾的是,「数据」这一关键词的百分比处于下降趋势。我激动万分地前去参观「Algorithms–Missing Data」海报展,但却发现竟然只有一张海报「Missing Not at Random in Matrix Completion: The Effectiveness of Estimating Missingness Probabilities Under a Low Nuclear Norm Assumption」张贴了出来!
-
「元」这一关键词在今年增长的最多。详情请参阅 Jesse Mu 的「Meta-meme」:https://twitter.com/jayelmnop/status/1206637800537362432
-
尽管「贝叶斯」一词的比例下降了,但「非确定性」却上升了。去年,有许多论文使用了贝叶斯原理,但并不是将其运用在深度学习中。
五、NeurIPS 关键数据一览
-
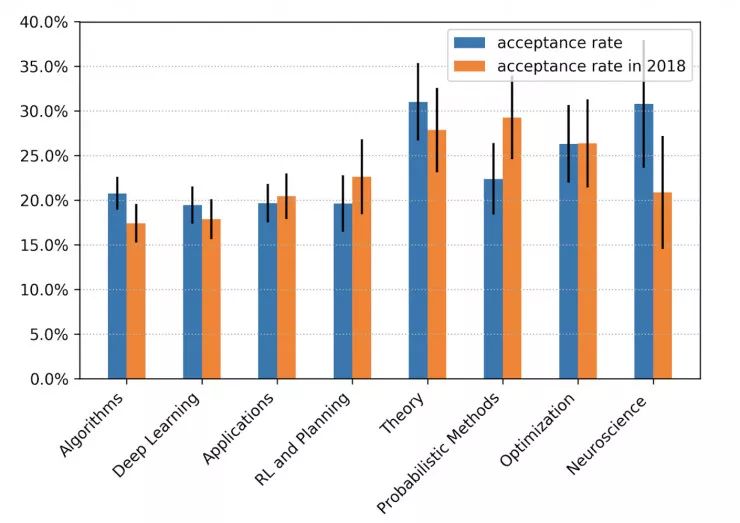
提交给正会的 7 千多篇论文中,有 1428 篇被接收,接收率为 21%。
-
据我估计,1万3千多名参会者中,至少有一半人并没有在会议期间展示论文。
-
57 个研讨会,其中 4 个专注于包容性:Black in AI,Women in Machine Learning,LatinX in AI,,Queer in AI,New In Machine Learning,Machine Learning Competitions for All。
-
-
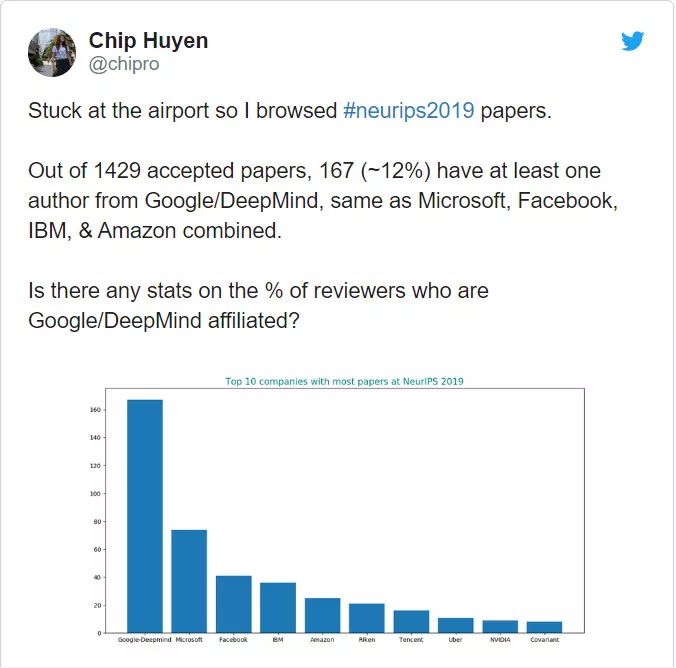
在所有被接收的论文中,有 12% 至少包含一名来自谷歌或 DeepMind 的作者。
-
有 87 篇论文来自斯坦福,它是本届 NeurIPS 被接收论文最多的学术机构。
-
有 250 篇关于应用的论文,占总论文数的 16.7%。
-
648 是本届大会时间检验论文奖获得者 Lin Xiao 的「Dual Averaging Method for Regularized Stochastic Learning and Online Optimization」的引用次数。这证明了引用量与贡献不一定相关。
-
75% 的论文在「camera-ready」版中给出了代码链接,去年这一数字只有 50%。
-
-
173 篇论文声称进行了 OpenReview 上的可复现性挑战。
-
31 张海报出现在了本届 NeurIPS 的「创意和设计中的机器学习」研讨会上。一些人告诉我这是他们在本届大会上最喜欢的环节。
-
为「Good Kid」乐队在闭幕宴会上的演出打 call!如果你还没有欣赏过他们的音乐作品,可以去 Spotify 上听一听。
有时,他们是机器学习研究者;有时,他们又是摇滚明星。今夜,他们二者都是!
-
「Retrospectives: A Venue for Self-Reflection in ML Research」研讨会进行了 11 场演讲,这也是大家最喜欢的环节之一。
除此之外,本届 NeurIPS 的火爆氛围也相当引人关注。
六、结语
无论从知识的角度还是从社交的角度来说,NeurIPS 都势不可挡。我不认为任何人能够阅读16,000页的会议记录。海报展人满为患,这使得我们很难与作者交谈。毫无疑问,我错过了很多。
然而,会议的大规模召开也意味着汇聚了许多的研究方向和相关的研究人员。让我能够了解自己研究的分支领域之外的工作,能够向那些研究背景和兴趣与我不同的研究人员学习,这种感觉很好。
看到研究社区从「更大就更好」的误区中走出来是一件很棒的事。我逛海报展收获的印象是:许多论文只是在小数据集上做实验,比如 MNIST 和 CIFAR。最佳论文奖获得者 Ilias Diakonikolas 等人的「Distribution-Independent PAC Learning of Halfspaces with Massart Noise」就没有任何实验。
我经常听到年轻的研究人员担心:只有加入大型研究实验室,才能获得计算资源。但 NeurIPS 证明了:
你可以在无需担心数据和计算问题的情况下做出重要的贡献
。
在我参加的 NewInML 圆桌讨论上,有人说他不知道 NeurIPS 上的大多数论文如何被应用到生产环节中去。Neil Lawence 指出,也许他应该考虑参加其它会议。
NeurIPS 比许多其它的机器学习会议更加理论化——从事基础研究是很重要的。
总的来说,我在 NeurIPS 上度过了一段美好的时光,并计划明年继续参会。然而,对于那些新加入机器学习研究社区的人来说,我建议他们将 ICLR 作为参加的第一个学术会议。
ICLR 的规模更小、时间更短、也更加面向实际应用。明年,ICLR 将在埃塞俄比亚召开,那是一个神奇的国度!
Via https://huyenchip.com/2019/12/18/key-trends-neurips-2019.html
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割、姿态估计、超分辨率、嵌入式视觉、OCR 等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台
觉得有用麻烦给个在看啦~ ![]()


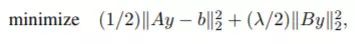 的Hamiltonian 下降(HD)和梯度下降算法的对比情况
的Hamiltonian 下降(HD)和梯度下降算法的对比情况