AAAI 2020 | 南京大学×滴滴:基于弱监督学习的网约车用户体验提升
本文转载于 滴滴科技合作
致力于提升用户体验、创造社会价值,滴滴作为领先的一站式移动出行平台,一直寻求能与用户体验达成最优的契合点。网约车司乘评价体系需要兼顾乘客体验、司机接单公平性与平台效能,是司乘生态建设的一大关键。
本文解读南京大学机器学习与数据挖掘LAMDA团队李宇峰研究组与滴滴网约车技术团队合作完成的工作《Weakly Supervised Learning Meets Ride-Sharing User Experience Enhancement》。
Available at https://arxiv.org/abs/2001.09027
http://www.lamda.nju.edu.cn/liyf/paper/aaai20-cwsl.pdf
简介

现有机器学习技术得以成功的背后往往依赖充足的标记数据。然而,充足标记数据的获取非常困难,因为现实任务中数据标记的速度往往赶不上数据产生的速度。弱监督学习(不依赖充足标记数据的机器学习框架)[1]更为贴近现实任务,但也更为困难。
弱监督学习研究主要围绕各种特定弱监督数据信号开展[1]。例如,半监督学习旨在研究监督信息不完整(Incomplete)的数据;噪声标记学习旨在研究监督信息不准确(Inaccurate)的数据;多示例学习旨在研究监督信息不具体(Inexact)的数据等。南京大学LAMDA团队常年来对弱监督学习相关技术瓶颈开展基础研究,提出了具有性能保障的安全半/弱监督学习、自动半监督学习等工作[2][3]。
随着弱监督学习不断走向实际应用,单纯的弱监督学习技术已越来越难于满足现实任务的需求。其原因之一在于,往常的弱监督学习技术仅适合一种弱监督数据信号,类似于某药方(弱监督学习技术)仅适用于某特定病症(弱监督数据信号)。然而,现实任务的数据同时伴随着多种弱监督数据信号时有发生,类似于多种病症常伴随出现。能够协同处理多种病症的复合弱监督学习(Compound Weakly Supervised Learning)技术非常必要。然而,该方面鲜有相关基础研究工作,也包括结合实际业务数据的应用案例剖析,亟待开展研究。
本文基于滴滴智能司乘评价的实际业务场景,展示复合弱监督学习的必要性和实际效用。具体而言,业务背景情况如下:随着移动互联网颠覆性变革,网约车不断发展普及,已进入人们日常生活。滴滴作为领先的一站式移动出行平台,深刻影响着人们的出行和生活方式。为尽可能地提升用户体验、建设良好的司乘生态,网约车智能司乘评价体系起着至关重要的作用,需兼顾乘客体验、司机接单公平性与平台效能。在智能评价体系中,每个乘客乘车结束后手机端都会收到一个推荐的评价问题,如“司机是否绕路?”。如果该回答能够很好的反映出此次行程的不足,那将有助于平台对司机进行教育,以提高用户的体验。借助机器学习来进行评价问题推荐就是智能评价体系的主要目标。然而,这其中存在两个严重影响机器学习性能的数据问题,一是数据存在严重的标记噪声,因为评价结果往往受到乘客主观因素的影响,导致收集到的标记不准确,同时也存在着大量误操作和乘客随意评价的情况;二是数据标记分布存在偏差,即训练数据中差评与好评数据的标记分布和真实线上环境的标记分布存在明显的差距。围绕这类实际数据问题,需要发展复合弱监督学习技术。本文提出的复合弱监督学习技术明显优于单纯弱监督学习技术,可将AUC性能提升5%以上。
技术方案
本文技术方案采取一种基于双层优化的新框架。具体而言,针对标记噪声问题,我们对样本进行赋权,其目的是希望能够对噪声样本赋予较低的权重,从而减少其对模型性能的影响,目标函数如下所示:
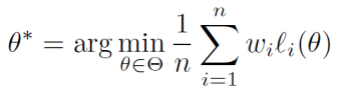
其中w表示样本权值,θ为模型参数。
针对标记分布不匹配的问题,我们优化对标记分布更为鲁棒的性能指标AUC:
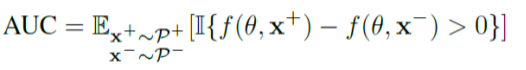
此外,“好”的样本赋权机制应该可以保证其得到的模型在验证数据上表现良好。综合以上思路,技术方案采用如下双层优化目标式实现:
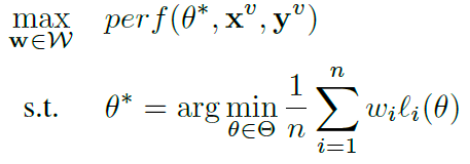
其中内层优化步骤最小化训练数据上的经验风险,外层优化步骤评估验证数据上的性能表现。两者的结合,不断优化训练模型。
技术方案的整体流程如下图所示:
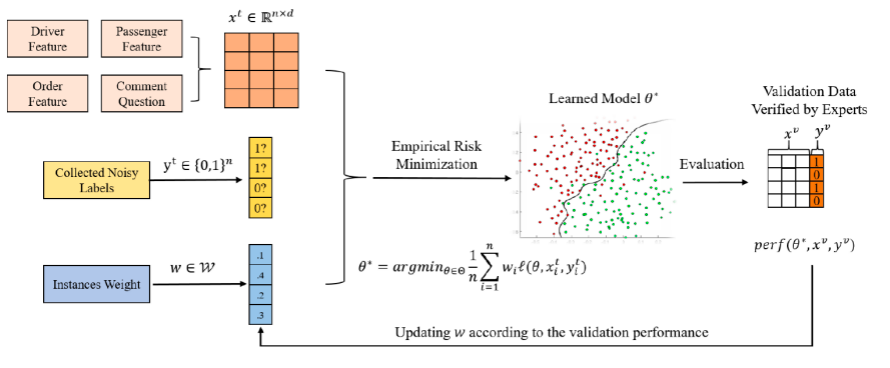
同时,文章为技术方案提出了高效的优化算法。详细优化技术细节请参见论文阐述。
应用效果
在滴滴司乘评价数据中,复合弱监督学习技术方案和仅考虑一种弱监督数据信号的单纯弱监督学习算法进行比较。比较方法包括标记分布修正[4]后的监督学习算法: Logistic Regression (LR)、Deep Neural Network (DNN)、XGBoost;处理标记噪声的SOTA算法 Rank Pruning[5],GLC[6]和LTR[7],具体的实验结果如下:
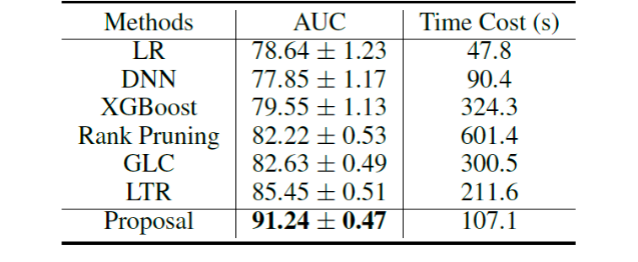
本文提出的复合弱监督学习技术方案明显优于单纯弱监督学习技术,可将AUC性能提升5%以上,并维持不错的效率。
该研究成果不仅在评价数据的利用上对推荐结果有很好的提升,并且对司乘纠纷公平判责、地图POI挖掘等场景有比较好的借鉴意义。
参考文献
[1] Zhi-Hua Zhou. "A brief introduction to weakly supervised learning." National Science Review 5.1 (2018): 44-53.
[2] Yu-Feng Li, Lan-Zhe Guo, and Zhi-Hua Zhou. "Towards Safe Weakly Supervised Learning." IEEE Transactions on Pattern Analysis and Machine Intelligence (2019).
[3] Yu-Feng Li, Hai Wang, Tong Wei, Wei-Wei Tu. Towards Automated Semi-Supervised Learning. AAAI'19, Honolulu, HI, 2019, pp.4237-4244.
[4] Dal Pozzolo, A., Caelen, O., Johnson, R. A., & Bontempi, G. "Calibrating probability with undersampling for unbalanced classification." IEEE Symposium Series on Computational Intelligence, 2015, 159-166.
[5] Northcutt, C. G.; Wu, T.; and Chuang, I. L. Learning with confident examples: Rank pruning for robust classification with noisy labels. UAI 2017.
[6] Hendrycks, D.; Mazeika, M.; Wilson, D.; and Gimpel, K. Using trusted data to train deep networks on labels corrupted by severe noise. NIPS 2018, 10456–10465.
[7] Ren, M.; Zeng, W.; Yang, B.; and Urtasun, R. Learning to reweight examples for robust deep learning. ICML 2018, 4331–4340.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“WRL” 就可以获取《基于弱监督学习的网约车用户体验提升》论文专知下载链接








