嵌入向量能否理解数字?BERT竟不如ELMo?
选自arXiv
机器之心编译
参与:魔王
对自然语言文本执行数字推理是端到端模型的长期难题,来自艾伦人工智能研究所、北京大学和加州大学欧文分校的研究者尝试探索「开箱即用」的神经 NLP 模型是否能够解决该问题,以及如何解决。
论文:Do NLP Models Know Numbers? Probing Numeracy in Embeddings
论文地址:https://arxiv.org/pdf/1909.07940.pdf
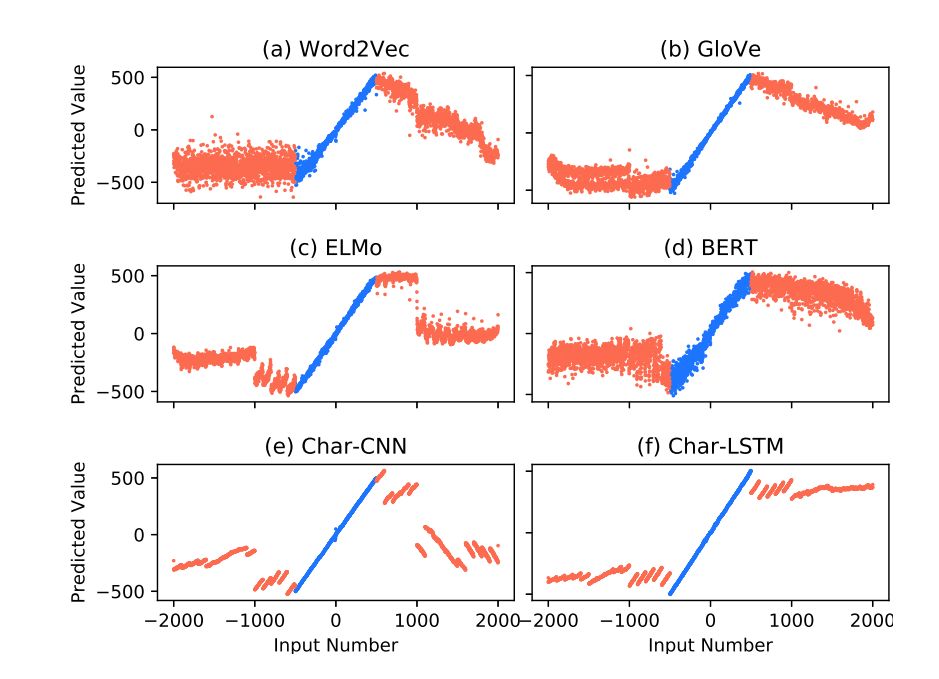

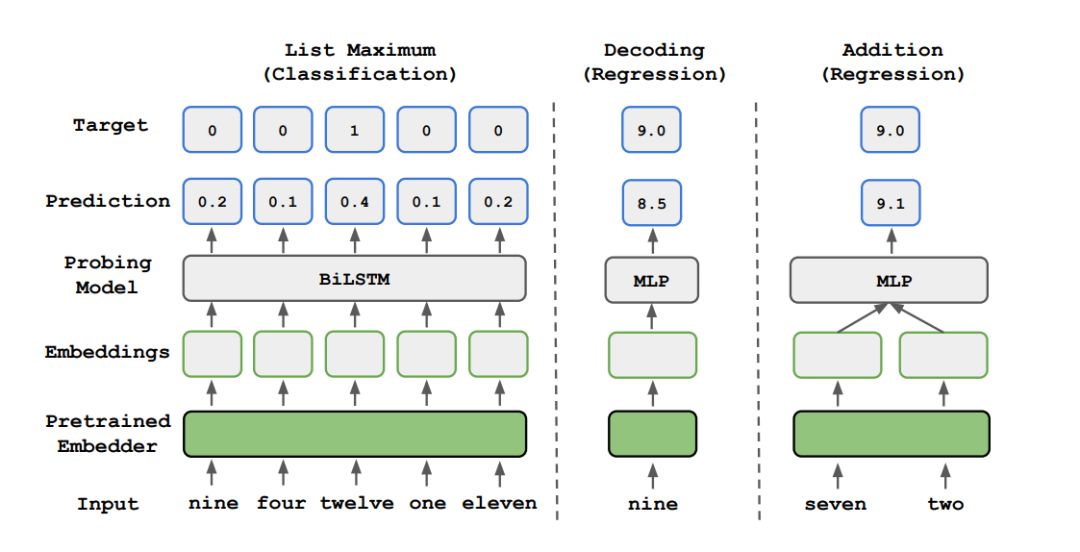
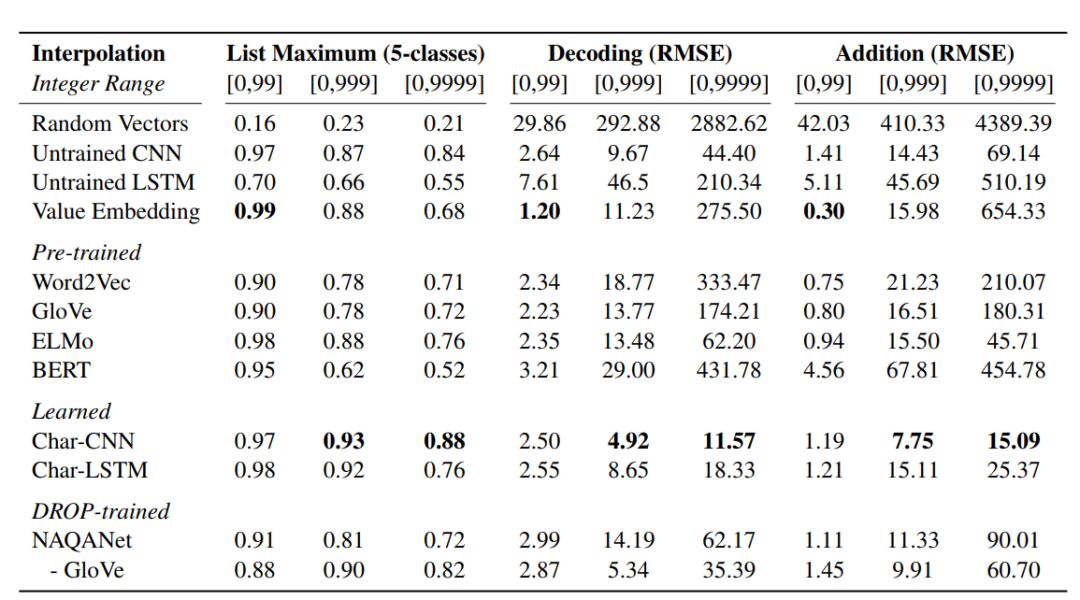
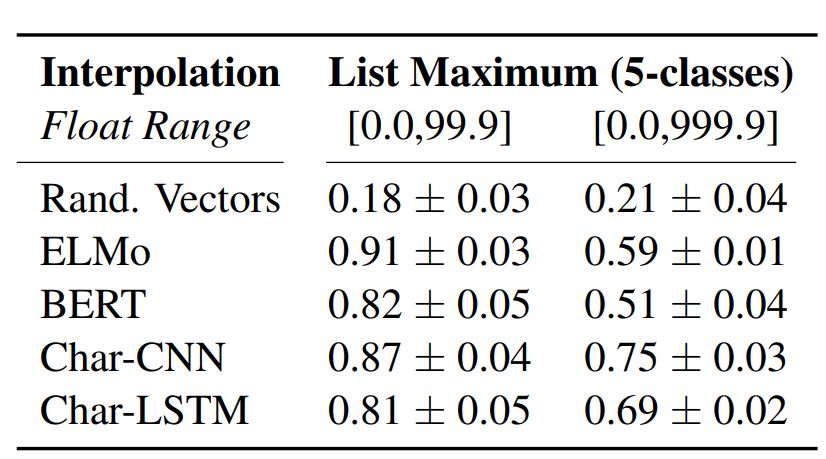
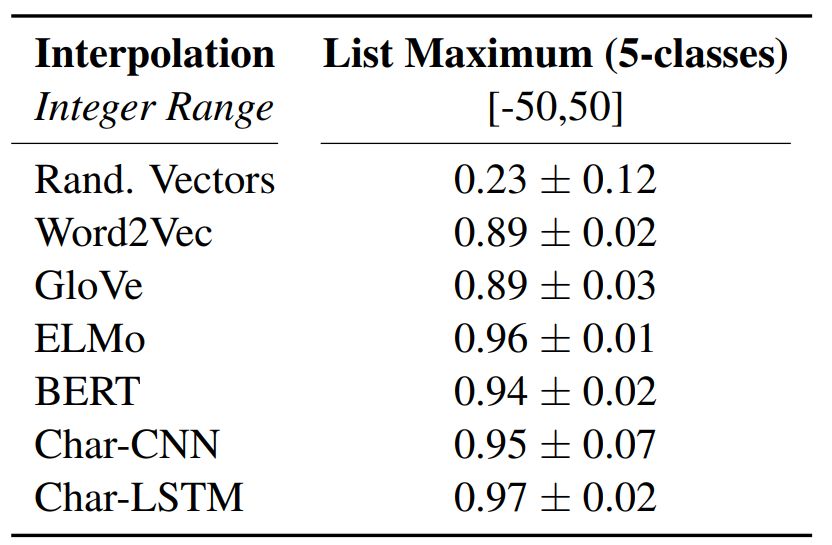
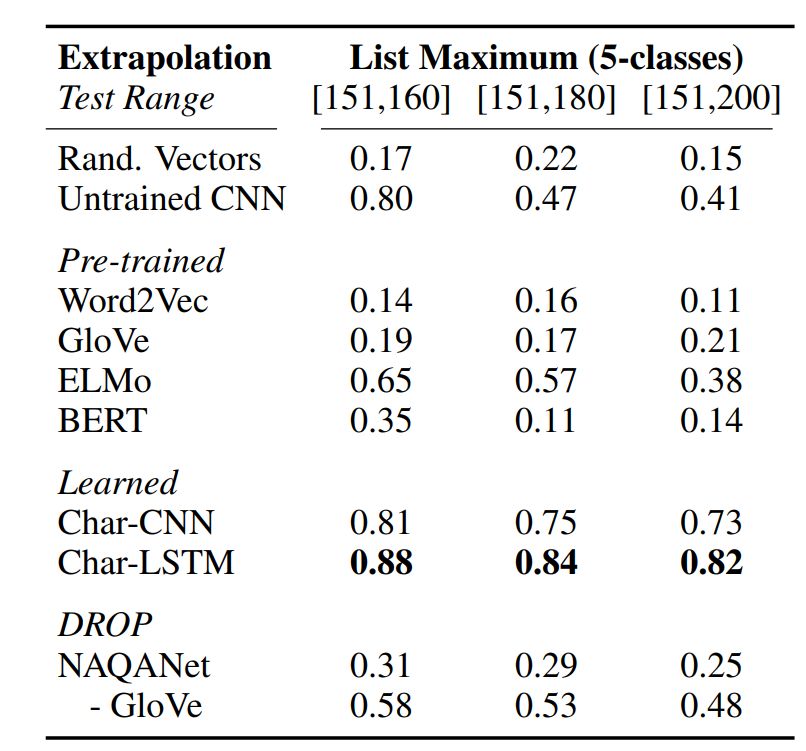
列表最大值:给出包含 5 个数字的嵌入列表,该任务就是预测其中最大值的索引。
解码:探索是否识别数字大小。
加法:该任务需要数值运算:给出两个数字的嵌入,该任务即预测二者之和。
词向量:使用 300 维 GloVe 和 word2ve 向量。
语境嵌入:使用 ELMo 和 BERT 嵌入。
NAQANet 嵌入:在 DROP 数据集上训练 NAQANet 模型,从中提取 GloVe 嵌入和 Char-CNN。
预训练嵌入:使用字符级 CNN (Char-CNN) 和字符级 LSTM (Char-LSTM)。
把数值作为嵌入:将数字的嵌入直接映射至数值。
登录查看更多
相关内容

Arxiv
6+阅读 · 2019年8月21日
Arxiv
3+阅读 · 2019年2月11日
Arxiv
5+阅读 · 2018年7月21日




相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2019年8月21日
Arxiv
3+阅读 · 2019年2月11日
Arxiv
5+阅读 · 2018年7月21日