快速构建深度学习图像数据集,微软Bing和Google哪个更好用?

在本文中,作者将利用微软的 Bing Image Search API 来建立深度学习图像数据集。Bing Image Search API 是微软 Cognitive Services 的一个组成部分,主要是帮助用户在视觉、语言、文本等手机应用和软件中应用AI。

在本文中,作者将利用微软的 Bing Image Search API 来建立深度学习图像数据集。Bing Image Search API 是微软 Cognitive Services 的一个组成部分,主要是帮助用户在视觉、语言、文本等手机应用和软件中应用AI。相比较,利用 Google Images 来构建自己的数据集是一个乏味且需要手动的过程,主要原因是因为多年前,谷歌关停了自己的图像搜索 API ,然而,我们需要的是一个通过查询能够自动下载图像的方案。
▌创建 Cognitive Services 帐户
在本节中,我将会向你演示如何申请一个免费的Bing Image Search API账户。点开链接 Bing Image Search API 开始我们的注册流程:
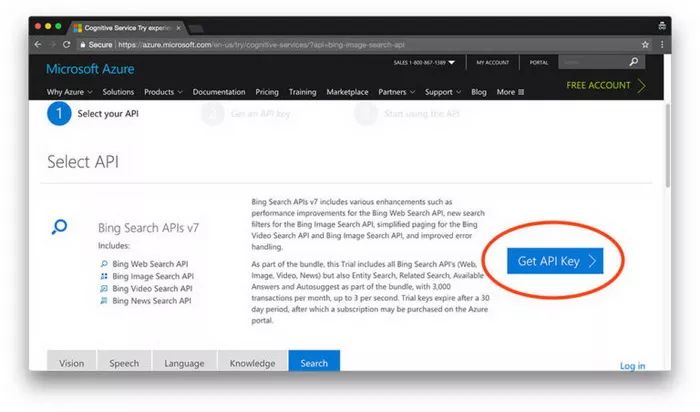
图1:微软 Bing Image Search API 注册入口
从上图的截屏中我们可以看到,这个试用版囊括了 Bing 中所有搜索 API ,每月都有 3000 笔交易实现,已经能够满足用户需求,这对于建立第一个深度学习图像数据集来说已将完全够用了。
若要注册 Bing Image Search API,请点击 “Get API Key” 按键。可以通过微软账号、Facebook 账号、领英账号甚至是 GitHub 账号来注册(方便起见我是用了GitHib账号进行注册的)。当完成注册以后,就会看到如下图中我的浏览器展示的页面内容。
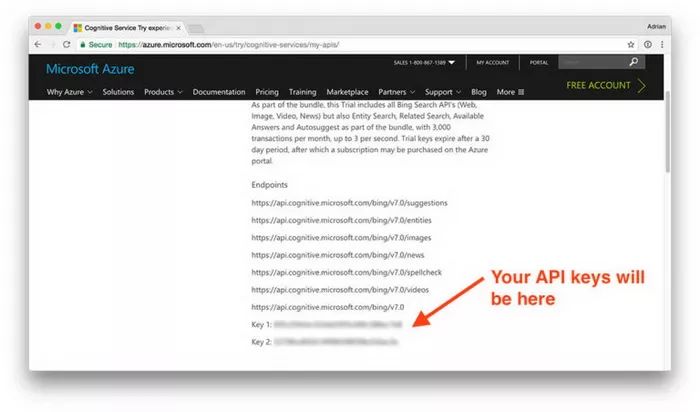
图2:Microsoft Bing API 端点以及我需要使用该API时的密钥
此时可以看到我的页面中 Bing 搜索终结点列表,包括两个 API 密钥。(请牢记的 API 密钥,在下一节中就会用到它)
▌使用 Python 来构建你的深度学习数据集
在注册完 Bing Image Search API 账户之后,现在我们已经做完了建立深度学习数据集的前期准备。
阅读文档
在继续下面的操作之前,我建议在浏览器中打开下面两个Bing图像搜索API文档页面:
Bing 图像搜索 API – Python QuickStart
Bing 图像搜索 API – Paging Webpages
如果对 API 的工作原理或是当提出请求之后如何使用 API 依然存有疑问,可以参考上述两个文档。
安装 request 包
如果你的电脑系统中没有安装 request ,你可以通过如下方式来安装:
$pip install requests1
安装Request包之后你会发现,向 HTTP 发送请求会变得非常容易,而且能保证我们在向 Python 发出请求时不会遇到各种棘手的困难。除此之外请注意,如果你在虚拟环境中使用 Python ,那么你需要在终端里使用 workon 来访问虚拟环境,再去安装 request。
$ workon your_env_name
$ pip install requests12
编写你自己的Python图像下载代码
让我们继续向下走,开启编程之旅。打开一个新的脚本文件,将其命名 search_bing_api.py,为并在脚本中输入下述代码:

导入此脚本中所需的软件包。你需要在虚拟环境中提前安装好 OpenCV 和 requests 。下面这个链接(https://www.pyimagesearch.com/opencv-tutorials-resources-guides/)给出了在系统中安装 OpenCV 的相关教程。
接下来,我们来讲解一下两个命令行参数:
“query”:指的是你想要搜索的图像关键字或特征,比如说“神奇宝贝”、”圣诞老人”或者是“侏罗纪公园”之类的。
“output”:图像的输出目录路径。我个人偏向于把图像分成独立的类子目录,因此在调用函数时,一定要指定你想下载的图像存储进入的正确文件夹(如下面 “下载图像进行培训深度神经网络” 部分所示)。
在这个脚本中你不需要去修改命令行的任何参数,这些参数是程序运行时的输入量。如果你不明白怎么正确使用命令行参数,请参考我以前的博客文章 my recent blog post。
接下来配置一些全局变量:
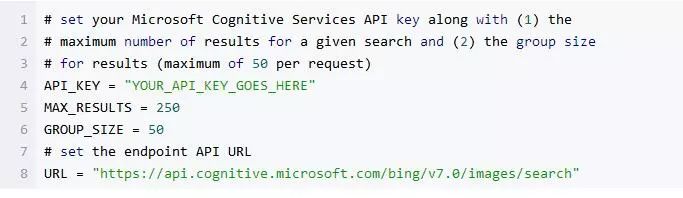
在使用上述代码的时候,读者必须更改 API_KEY 的值。请登录到 Microsoft Cognitive Services 并选择要使用的服务来获取 API 密钥(如上所示,需要单击“获取 API 密钥”按钮),然后只需将 API 密钥粘贴到该变量的引号内即可。
当然在实际编程的时候也可以更改 MAX_RESULTS和GROUP_SIZE 这两个参数的值。我在示例中只要求数据库中有 250 张图片,一共 5 次搜索,每次搜索返回最多 50 张图片(可以通过改变 MMAX_RESULTS 参数来更改这个数量),同时我要求 Bing API 在每次执行搜索和下载图片命令时,都要返回单次下载下来的图片数量值。
你也可以把 GROUP_SIZE 的参数看作是 per page 的返回值的数量。因此如果我们一共需要 250 张图片,就需要把 “pages” 参数调成 5,“per page” 的值赋成 50。
注意:
1、所下载的图片一定要与搜索的关键词有关系;
2、操作过程需要在 Bing AI 的免费服务范围之内(否则就需要为所要求的服务付费)。
现在一起来看一看,在准备阶段我们会碰到的所有可能的异常。这些异常可能会在获取映像时出现。我先列出可能遇到的异常:
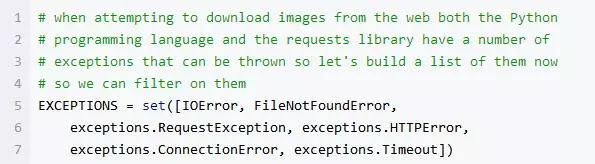
在处理网络请求时,我们可能会抛出一些异常,我们将尝试找到他们并加以妥善解决。
接下来让我们初始化搜索参数并进行搜索:
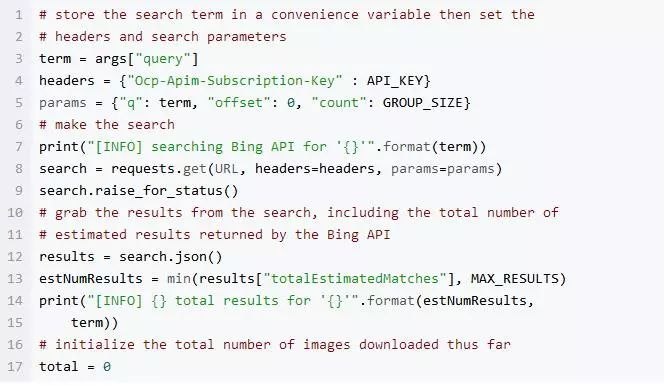
对搜素变量参数进行了初始化。在执行该操作时若有任何问题请参阅相关API documentation。
接下来我们执行搜索命令,并以 JSON 格式获取结果。我们执行了计算命令并输出下一个终端的预计下载图片数量。将总数进行初始化,因为之后要记录下载图片的总数量。
接下来运行程序,得到 GROUP_SIZE 的循环结果:
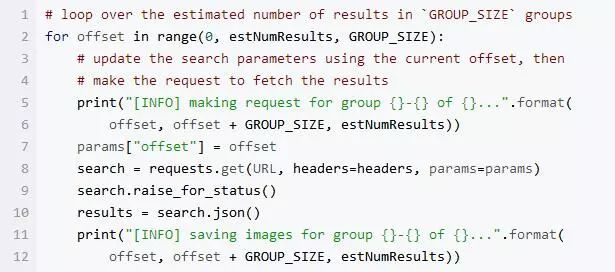
执行循环,通过循环得到 GROUP_SIZE 批处理结果的估计量(这是 API 允许的)。
当调用 requests.get 来获取 JSON blob时,当前偏移量会作为参数被传递。
现在尝试保存当前批次中的图像:
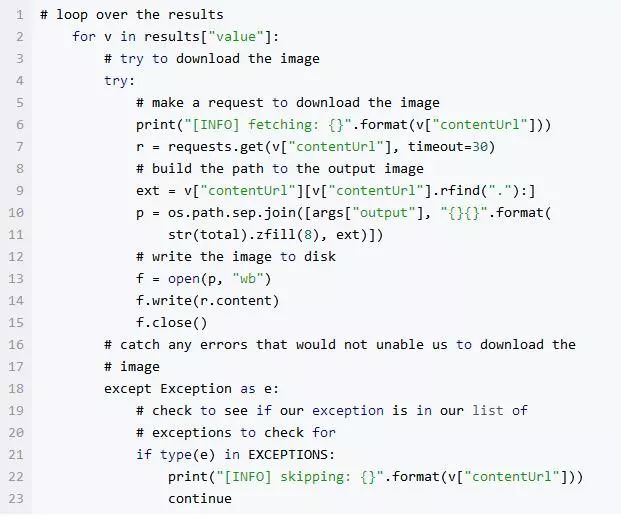
接下来我们将循环播放当前这一批图像,并尝试将每个图像下载到我们的输出路径文件夹中。
建立一个 try-catch 块,以便我们捕捉到我们之前在脚本中定义的可能的异常情况。如果遇到异常,我们将跳过该特定图像并继续下载后面的图片。
在 try 代码块内部我们通过 URL获取图像,并为它建立一个路径+文件名。
然后我们尝试打开图像,并将文件写入磁盘。需要注意的是,我们在 “wb” 中创建了一个由 b 表示的二进制文件对象,然后访问二进制数据 viar.content。
接下来,我们看看 OpenCV 能否实际加载图像。如果能实现该操作,则说明:1、图像文件已成功下载,2、图像路径有效:
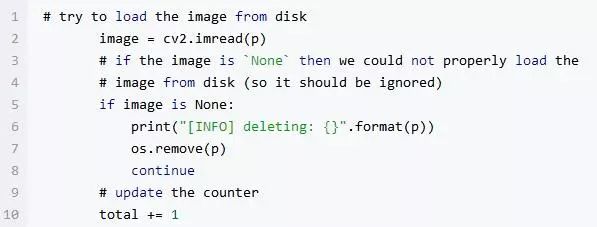
只要图像数据不是无,我们就需要更新计数器(每次加1)并循环回到顶部。
否则,我们需要调用 os.remove 删除无效映像,然后继续回到初始循环,同时不更新计数器。 if 语句可能由于下载文件时出现网络错误,未安装正确的图像 I / O 库等原因被触发。如果想要了解更多关于 OpenCV 和 Python 中的 NoneType 错误的信息,请参阅此处网页refer to this blog post。
▌下载图像训练深度学习神经网络系统
既然已经写好了代码,现在就让我们使用 Bing’s Image Search API 来下载深度学习数据集的图像。(需要使用本文的 “Download” 部分下载代码和示例目录结构。)
现在创建一个数据集目录:
$mkdirdataset1
把下载的所以图像都存储在数据集里,执行以下命令来创建子目录并搜索 “charmander” (小火龙):
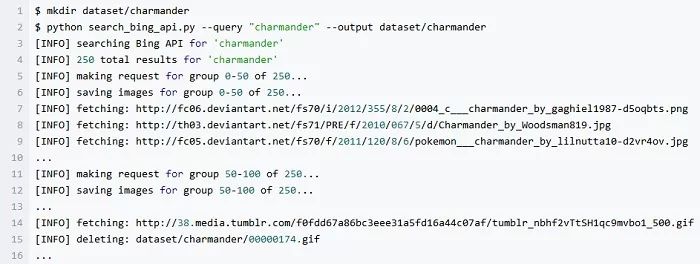
正如我在这篇文章开头提到的,我们需要为搭建自己的 Pokedex 下载一些 Pokemon 的图像。
在上面的代码中,我正在下载一个受非常欢迎的宠物精灵—— 小火龙 Charmander 的图像。250 张图片中,大部分都会成功下载;但是如上图的输出所示,有一些 OpenCV 无法打开的文件将被删除。
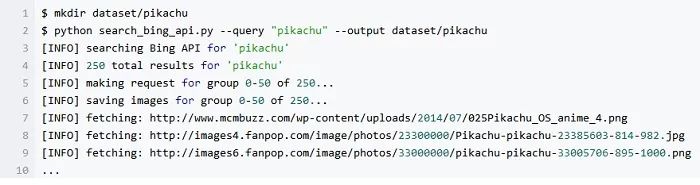
同样的,我们用上面的代码来下载皮卡丘的图像:
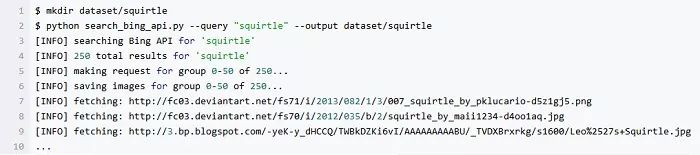
同样的,我们来处理妙蛙种子 (Bulbasaur) 的图像:
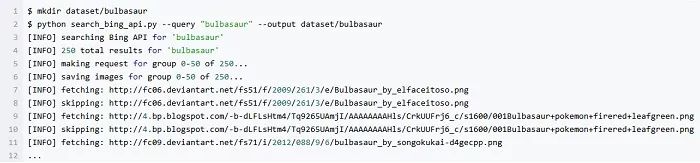 最后下载超梦 (Mewtwo) 的图像:
最后下载超梦 (Mewtwo) 的图像:
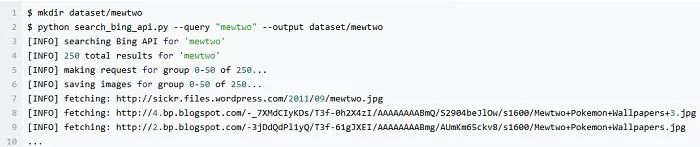
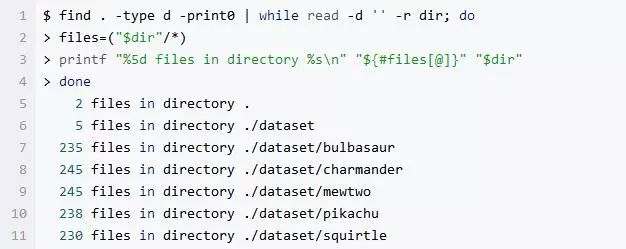
在这里我们可以看到,对于每一种神奇宝贝,相应的下载目录下大约有 230-245 张图片。理想情况下,我希望在图片库中,每种神奇宝贝都有 1,000 幅图片左右,但为了做示例能简单一些,又考虑到网络开销(对于没有快速/稳定的 Internet 连接的用户),我只为每一只神奇宝贝下载了 250 张图片来当作图片库。
▌完善深度学习图像数据集
但是,我们每次下载下来的图片并不一定全都和我们的搜索关键词有关系。虽说大部分应该都是这些神奇宝贝的图片,但是总有几张漏网之鱼。不幸的是,这项工作是手动的,你需要到你的图片目录下一张一张去确认,然后删掉与关键字不相符的图片。
不过在苹果电脑的 macOS 系统中这个过程还是非常快的。
我只需要打开我的 “Finder” ,在 “CoverFloow” 视图下,浏览所有图片文件即可。
图3:.我正在使用 macOS 的 “Cover Flow” 视图,以便快速浏览图像并过滤出我不想在深度学习数据集中使用的图像。
如果我发现了任何与关键字不相关的图片,只需要在键盘上按 cmd+delete 删除文件即可。其他的操作系统上也有类似的快捷方式和工具。
删除掉与目标不相关的图片后,让我们再重新做一次图片计数:
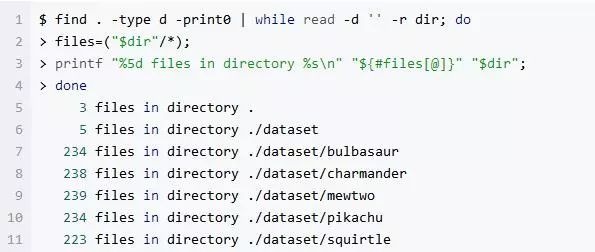
看这个新的图片计数结果——每个目录下我都仅仅删除了很少的不相关图片,这说明 Bing Image Search API 还是非常好用的。
另外,在实际操作中还应该剔除下载重复的图片,在这里,我没有做这个步骤是因为在剔除不相关图片时,我没有发现太多的重复(除了小火龙的图片,不知道为什么会有那么多重复)。如果想了解如何查找到重复,可以参考下面这篇文章:this blog post on image hashing.
▌结语
本文讲解了如何利用 Microsoft’s Bing Image Search API 来快速建立我们自己的深度学习图像数据集。我们学习了通过使用 API 来自动下载图片,这比使用 Google Image 时需要手动下载每一张图片更为方便。如果你想按照本文所讲述的知识实际操作一下的话,你可以选择 Bing Image Search API ,另外它将提供 30 天的免费试用期。
作者:Adrian Rosebrock

媒体合作请联系:
邮箱:contact@dataunion.org




