

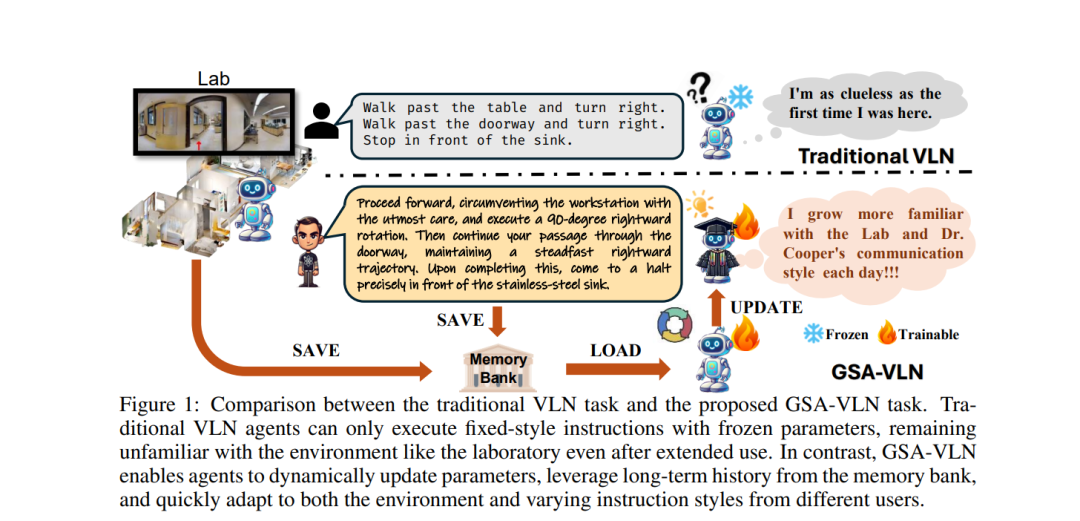
视觉与语言导航(VLN)任务主要通过在多个环境中执行单次指令来评估智能体,旨在开发能够在任何环境中以零-shot方式运行的智能体。然而,现实世界中的导航机器人通常在具有相对一致的物理布局、视觉观察和来自指导者的语言风格的持久性环境中运行。任务设置中的这种差距为通过将持续适应特定环境纳入其中来改进VLN智能体提供了机会。为了更好地反映这些现实世界条件,我们提出了GSA-VLN(视觉与语言导航的通用场景适应),这是一项新的任务,要求智能体在特定场景中执行导航指令,并同时适应该场景,以提高随时间推移的性能。为了评估提出的任务,必须解决现有VLN数据集中的两个挑战:缺乏分布外(OOD)数据,以及每个场景中指令数量和风格的多样性有限。因此,我们提出了一个新数据集——GSA-R2R,显著扩展了Room-to-Room(R2R)数据集的环境和指令的多样性和数量,以评估智能体在ID和OOD环境中的适应性。此外,我们设计了一个三阶段指令编排流程,该流程利用大型语言模型(LLMs)来优化生成的指令,并应用角色扮演技术将指令转化为不同的说话风格。这一做法的动机来自于观察到每个用户在指令中通常都有一致的特征或偏好,以家用机器人助手为例。我们在GSA-R2R数据集上进行了大量实验,全面评估了我们的数据集并基准了各种方法,揭示了促使智能体适应特定环境的关键因素。基于我们的研究结果,我们提出了一种新的方法——Graph-Retained DUET(GR-DUET),该方法结合了基于记忆的导航图和特定环境的训练策略,在所有GSA-R2R数据集分割上实现了最先进的结果。数据集和代码可以在https://github.com/honghd16/GSA-VLN找到。
成为VIP会员查看完整内容
相关内容
Arxiv
190+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
190+阅读 · 2023年4月7日