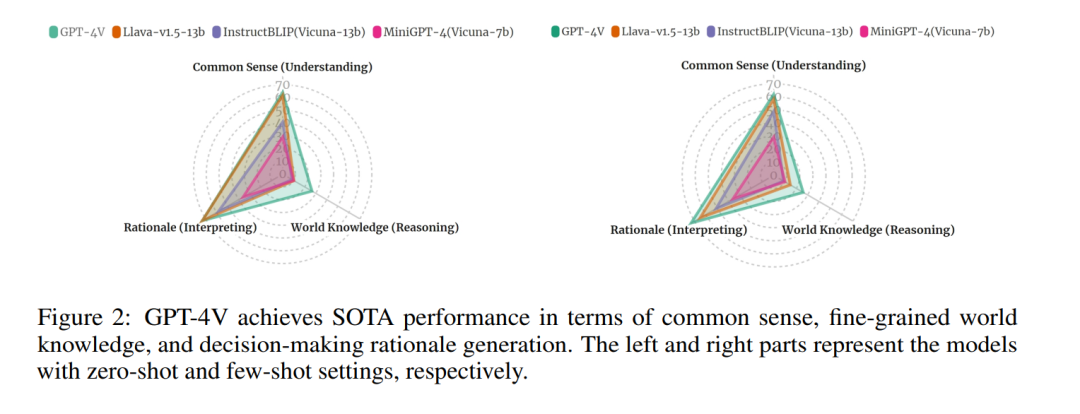
多模态大型模型(MLMs)的出现显著推动了视觉理解领域的发展,为视觉问题回答(VQA)领域提供了卓越的能力。然而,真正的挑战存在于知识密集型VQA任务中,这些任务不仅需要识别视觉元素,而且还需要深刻理解视觉信息,并结合大量已学习的知识。为了揭示MLMs的这些能力,特别是新近引入的GPT-4V,我们从三个角度进行了深入评估:1)常识知识,评估模型理解视觉线索并与一般知识相联系的能力;2)细粒度世界知识,测试模型从图像中推理出具体知识的技巧,并展示其在各个专业领域的熟练程度;3)综合知识与决策理由,检验模型提供推理逻辑解释的能力,从可解释性角度促进更深入的分析。广泛的实验表明,GPT-4V在上述三个任务上实现了SOTA(最先进)的表现。有趣的是,我们发现:a) GPT-4V在使用复合图像作为少量样本时展现了更强的推理和解释能力;b) GPT-4V在处理世界知识时产生了严重的幻觉,凸显了未来在这一研究方向上需要进行的进步。
视觉问题回答(VQA)任务是评估人工智能系统理解和推理视觉内容与文本信息的能力的一个基准,这在学术研究和实际应用中都具有重要意义。通过解决VQA所带来的复杂性和跨学科挑战,研究人员和实践者可以推动AI可能性的边界,朝着能够以类似人类的方式看、理解和与世界互动的机器迈进。最近提出的多模态大模型(MLMs)[4、8、9、21]在视觉-语言理解和推理方面取得显著成功,特别是围绕图像理解的视觉问题回答(VQA)场景。据我们所知,当人类与多模态人工智能系统交互时,他们通常期望获得他们不知道的有价值信息,并提出寻求信息的问题,这涉及到知识密集型挑战。这引发了一个相关的问题:基于MLMs的VQA系统在处理知识密集型信息寻求问题时表现如何?因此,研究MLMs在知识密集型VQA场景中的表现变得至关重要,因为这不仅能衡量它们基于存储知识的视觉推理能力,还能为提高它们在视觉问题回答方面的能力和提升其可信度铺平道路。在这项研究中,我们专注于评估先进的多模态大模型的能力,特别是在知识密集型VQA任务中的GPT-4V(ision)。
我们设计了一个全面的基准测试,通过重新配置现有的基于知识的视觉问答(VQA)数据集,这将使我们能够探测这些模型在常识和细致世界知识方面的推理能力,以及它们生成逻辑决策理由的能力。整体评估主要包括:1) 在广泛知识范围上的性能,我们设计了一个知识密集型的VQA基准测试,包括超过十种知识类别的常识和世界知识,以全面评估高级的掩码语言模型(包括GPT-4V);2) 提示方法的比较,我们审查了GPT-4V与预训练和指令调优的掩码语言模型在少量样本和零样本设置中的能力;3) 推理能力分析,我们利用决策理由探测了GPT-4V的可解释推理技巧。
我们的研究结果可以概括如下:
- 掩码语言模型(MLMs)在不同知识领域表现出不同的推理能力。我们的分析突出了MLMs在不同知识类别中的理解和推理能力的显著差异,包括常识和细致世界知识。
- 对于GPT-4V来说,涉及细致世界知识的视觉问答(VQA)是具有挑战性的。我们在第5.2节的评估识别了GPT-4V在细致世界知识问答中遇到的四个主要问题:a) 由于上下文不足而不愿回答;b) 识别相似物体(视觉错觉)的挑战;c) 视觉与知识维度整合不足;d) 过分依赖视觉线索,忽视文本查询。
- GPT-4V可以处理合成图像。我们的提示方法涉及向GPT-4V提供包含上下文参考的合成图像以进行情境学习。正如我们的实验结果(参见表4)所证明的,这种技术使GPT-4V能够达到更高的回答准确率。特别是,将上下文参考示例纳入合成图像增强了生成理由的质量,改善了GPT-4V的决策解释。

常识知识问答评估
常识知识,被理解为基本的和显而易见的真理,对人工智能(AI)构成了重大挑战,因为计算机本质上缺乏人类所拥有的天生理解能力。当面对需要常识推理的任务时,如理解在寒冷天气穿外套的必要性,AI系统经常会出现故障。在AI研究中的一个关键目标是设计方法,以使计算机具备常识知识,这对于使AI系统与人类之间的交互顺畅自然至关重要。在接下来的部分中,我们检验了GPT-4V在开放式视觉问答中使用不同提示策略处理常识知识的能力。
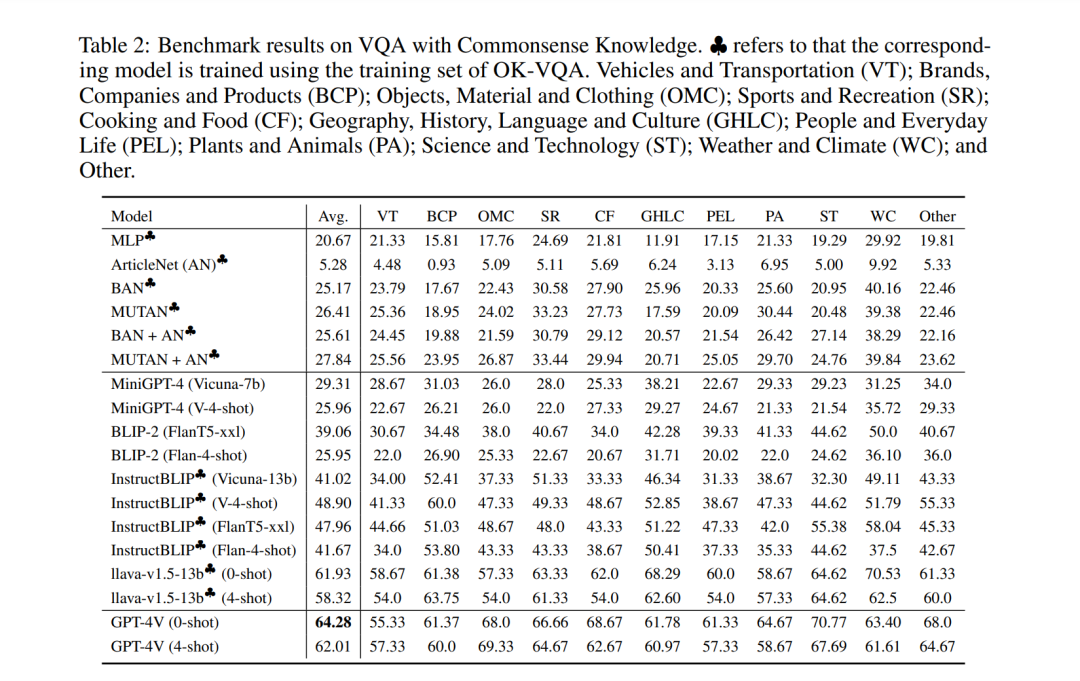
在本节中,我们评估了GPT-4V和各种先进的开源多模态大型模型在常识视觉问答(VQA)任务上的表现。实验结果和展示的示例表明,GPT-4V的表现超越了其同行,提供了更详细和全面的答案。我们注意到,当使用常识问题和答案进行微调时,多模态大型模型在此领域的表现有显著提升。然而,在少量样本输入设置下,大多数多模态大型模型(包括GPT-4V)的性能并无实质性增强。尽管示例选择的挑战可能有所贡献,但GPT-4V在某些知识类别中的表现提升表明,通过在合成图像中使用情境参考示例来优化模型是可行的。
评估MLMs在细粒度世界知识上的表现
与常识知识相比,世界知识指的是关于世界的具体信息,可能包括地理、历史、科学、当前事件等方面的事实、信息和数据。这种知识更为详细和具体。例如,知道法国的首都是巴黎,理解新科学发现的含义,或者了解当前的政治氛围。世界知识使AI能够回答事实性和具体的查询,对于MLMs回答信息寻求问题至关重要。在接下来的部分中,我们主要调查当前MLMs回答与细致世界知识相关的视觉问题的能力。这种类型的VQA需要MLMs识别视觉内容,并将视觉线索与储存的知识相联系。
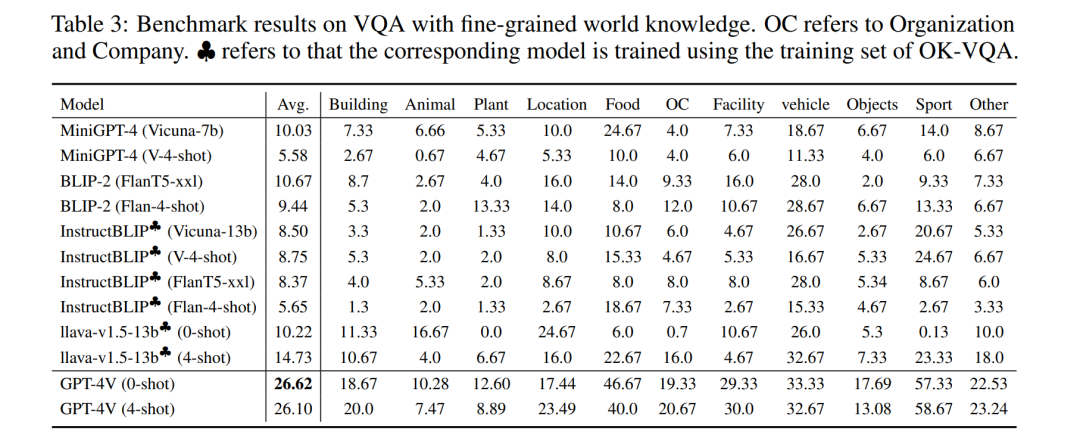
在本节中,我们主要探索GPT-4V和开源MLMs在细致世界知识密集型VQA上的表现。我们的实验发现和案例研究表明,虽然所有MLMs在回答需要实体特定知识的问题时都存在困难,但GPT-4V在这些场景中表现出显著的优越性。然而,我们也观察到GPT-4V往往过于谨慎,常常选择不回应与缺乏强相关视觉线索的图像相关的查询。在这些模型中,尤其是在它们的表现不佳时,明显的一个关键局限性是它们过分依赖视觉内容进行理解。当图像不包含与问题相关的信息时,这种依赖成为一个显著的缺点,导致错误显著增加。为了提升MLMs在细致视觉对象知识任务中的能力,需要进一步研究,尤其是在改善详细视觉数据与上下文知识的整合和相关性方面。
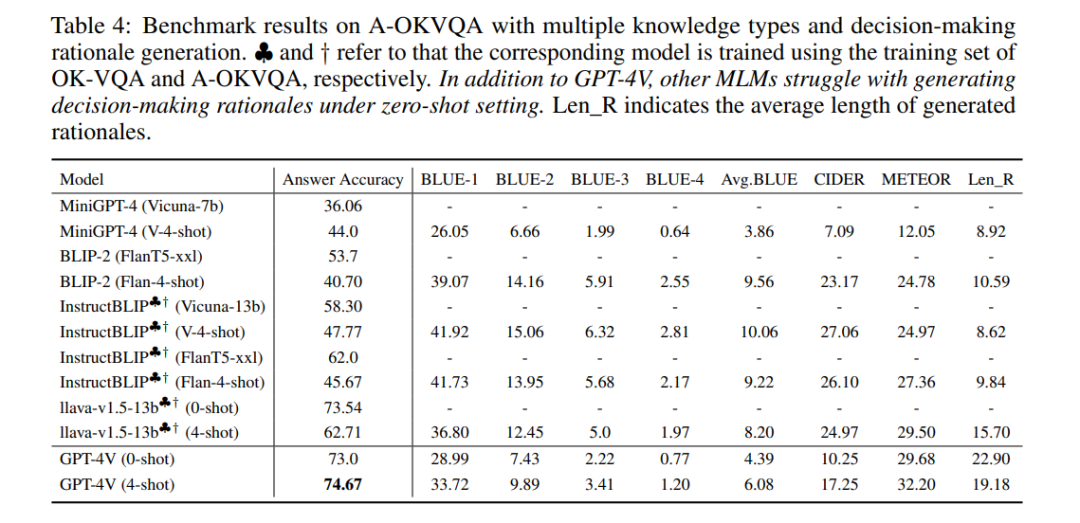
决策理由知识
多模态语言模型(MLMs)通常将预训练的大型语言模型与视觉编码器的能力结合起来,利用内部存储的广泛知识库。本节深入探讨当代MLMs固有的推理和解释能力。在此,我们呈现决策理由,以评估MLMs生成相关事实和逻辑推理序列以支持其推断的能力。在这一节中,我们主要评估GPT-4V和开源MLMs的答案准确性和决策理由生成质量。评估结果显示,在答案准确性方面,开源MLMs能够实现与GPT-4V相当的竞争性表现,这主要归功于它们在多模态指令调优阶段使用相关数据集。然而,这些模型在没有先前上下文参考的情况下生成基于指令的理由时,表现出困难,表明它们理解各种指令的能力存在局限。此外,在少量样本设置下,开源MLMs生成的理由质量低于GPT-4V。虽然这些MLMs能够生成决策理由,但它们的答案准确率大幅下降。简而言之,我们的发现揭示了当前开源MLMs的视觉理解能力明显落后于GPT-4V,它们的情境学习能力需要进一步增强。值得注意的是,少量样本设置方式使GPT-4V在答案准确性和生成理由的质量上的整体表现得到了提高。