

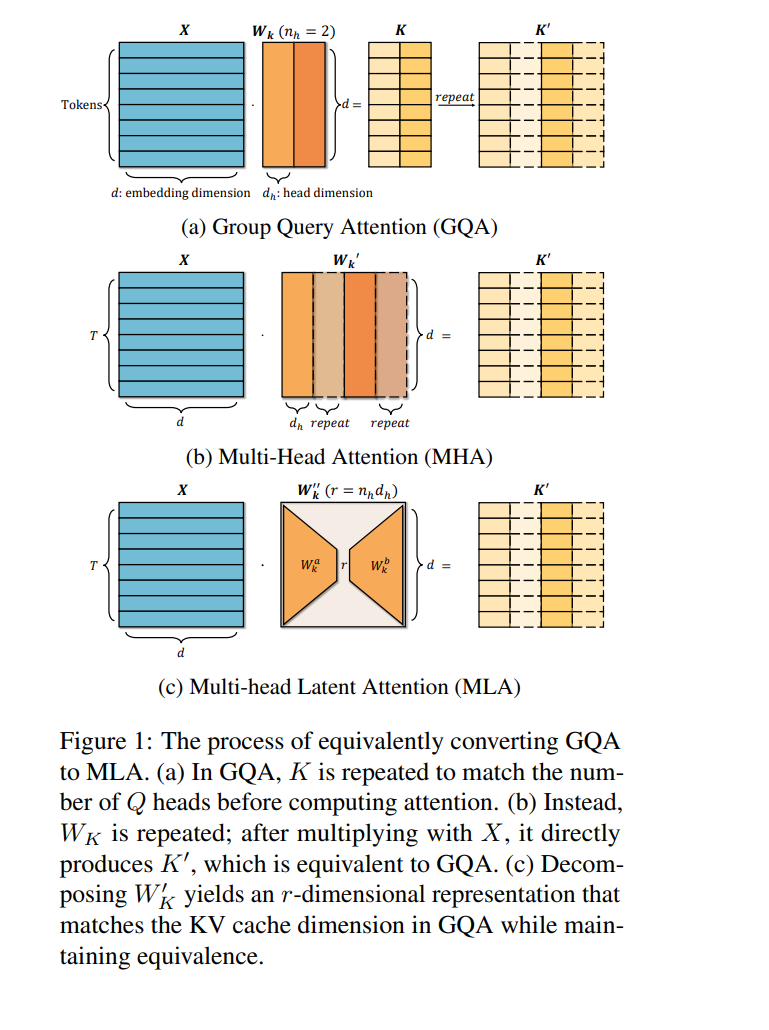
现代大型语言模型(LLMs)通常面临当前硬件上的通信瓶颈,而不仅仅是计算限制。多头潜在注意力(MLA)通过在键值层中利用低秩矩阵来解决这一问题,从而实现压缩的潜在键值(KV)状态的缓存。与传统的多头注意力相比,这一设计显著减少了KV缓存的大小,从而加速了推理过程。此外,MLA还引入了一个上投影矩阵,以增强表达能力,实际上是通过增加额外计算来换取减少通信开销。尽管在Deepseek V2/V3/R1中已经证明了其效率和效果,许多主要模型提供商仍然继续依赖群体查询注意力(GQA),并且没有公开计划采纳MLA。本文表明,GQA总是可以由MLA表示,并且KV缓存开销相同——但反之则不成立。为了促进更广泛的采用,我们引入了TransMLA,一种后训练方法,能够将广泛使用的基于GQA的预训练模型(如LLaMA、Qwen、Mixtral)转换为基于MLA的模型。在完成这一转换后,进一步的训练将提升模型的表达能力,而不会增加KV缓存的大小。此外,我们还计划开发专门针对MLA的推理加速策略,以保持转换后的模型的低延迟,从而促进Deepseek R1的更有效蒸馏。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
219+阅读 · 2023年4月7日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
219+阅读 · 2023年4月7日