

空域、航空与地面组件的技术进步催生了一种新型网络范式——“空天地一体化网络”(SAGIN)。无人机(UAV)在SAGIN中扮演关键角色。然而,由于无人机的高动态性与系统复杂性,SAGIN的实际部署成为实现此类网络的重大障碍。无人机需在有限机动能力与资源条件下,满足与天基及地面组件协同的关键性能需求。因此,在多样化应用场景中部署无人机需通过算法路径进行周密规划。本文对无人机辅助SAGIN中的近期学习算法进行系统性综述与分析。探讨了可能的奖励函数,并论述了优化奖励函数的前沿算法,包括Q学习、深度Q学习、多臂赌博机算法、粒子群优化算法及基于满意度的学习算法。与其他综述不同,本文聚焦于优化问题的方法论视角,其适用于SAGIN上的各类任务。我们考虑了真实场景配置及二维(2D)与三维(3D)无人机轨迹以反映实际部署案例。仿真结果表明,基于满意度的3D学习算法在多数情况下性能优于其他方法。通过文末讨论的开放挑战,我们旨在为无人机辅助SAGIN的设计与部署提供指导原则。
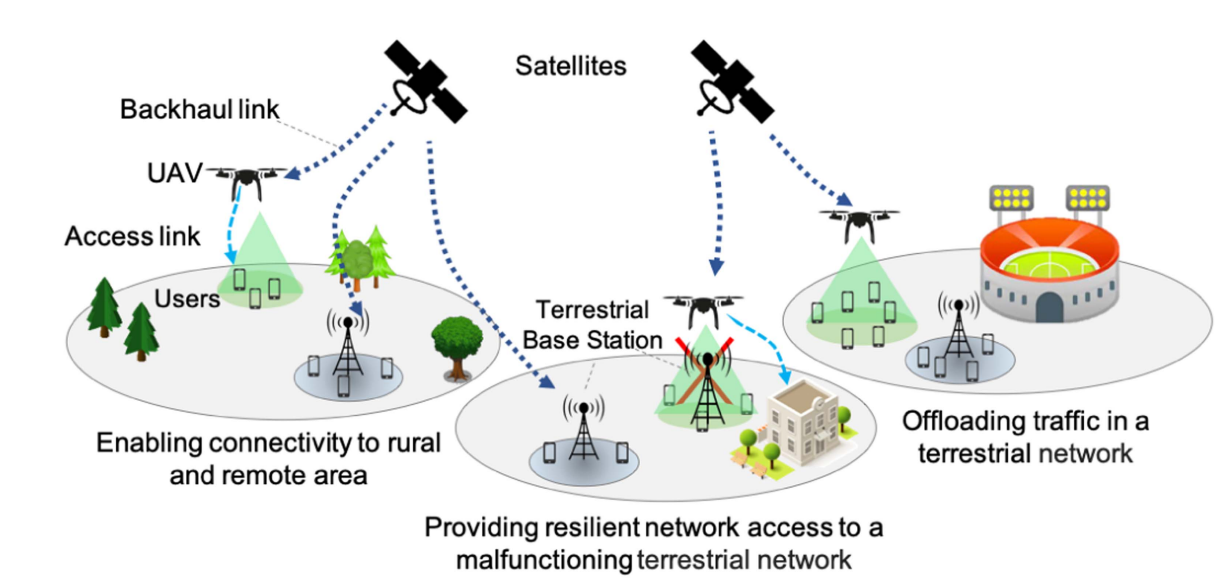
图 1. 使用无人机辅助 SAGIN 为位于农村/偏远地区和地面网络故障/过载的地面网络用户提供网络接入的用例。在这些案例中,无人机被视为空中基站。
非地球静止轨道(NGSO)卫星网络、航空网络与地面网络的最新进展催生了"空天地一体化网络"(SAGINs)这一新范式。无人机(UAV)凭借卓越机动性,通过精心规划的部署可显著提升SAGIN的性能与韧性。在无人机辅助的SAGIN中,无人机通过为用户提供连接服务,在性能保障与网络韧性方面发挥关键作用。如图1所示典型场景中,无人机可在基于SAGIN的网络架构中,为未覆盖区域、低覆盖区域或处于恶劣与过载条件下的地面用户提供按需网络接入。这些场景可扩展至多种配置与应用,其中无人机作为空中基站(BS)发挥作用,也可视为高空/低空平台站(HAPSs/LAPSs)系统[1],用于增强易受降雨、云层或其他大气条件遮挡的卫星点波束覆盖范围。无人机可缓解由故障地面基站引发的连接中断问题[2][3][4]。在需要分流地面网络(TN)高数据流量的通用场景中[5][6][7][8],无人机可被调度执行多种任务,为地面用户提供一致的体验质量(QoE)。
然而,无人机辅助SAGIN的巨大潜力伴随着现实挑战。首先,卫星网络、无人机与地面网络的建模需围绕关键QoE指标(如吞吐量、网络中断率与公平性)展开。其次,需联合优化所有网络分段的资源使用。第三,无人机编队部署需考虑实际因素(如能耗、高度保持与轨迹规划),这些因素会影响问题建模与性能[9][10]。现有文献尚未系统解决这些挑战。如表1所示,近期综述论文未覆盖SAGIN系统模型的所有要素(如无人机、卫星组件、地面组件及问题建模与技术对比)。例如文献[11]讨论了强化学习(RL)在通信网络中的整体应用,但未涉及无人机辅助SAGIN所需的卫星通信、地面组件、问题建模及技术评估与对比等核心要素。文献[12]探讨了5G网络中SAGIN的通用架构,但未对无人机与地面组件的使用进行统一建模与评估。文献[13]概述了SAGIN的通用部署,但未进行技术对比。此外,尽管QoE指标具有应用特异性,仅部分论文涉及相关讨论。更重要的是,这些研究尚未系统论述无人机辅助SAGIN中基于学习的最新算法路径。
近年来,文献中提出了基于学习与非学习的多种方法,用于优化SAGIN中各类任务的无人机规划。最前沿的研究聚焦于强化学习方法,而启发式方法未被纳入讨论。部分研究从非学习视角应对无人机网络挑战(如文献[14][15][16][17][18][19][20]),这些方法基于连续凸近似、基于惩罚的算法及通用与单无人机场景的空间平均吞吐量开发。类似地,文献[21]将无人机的二维(2D)部署与信道分配问题建模为可分解为两个子问题的非凸问题,并采用凸函数优化差异与二次变换技术进行求解。其假设无人机服务的地面用户通过地面基站接入核心网络。这类非学习方案在用户数量庞大、无人机编队复杂的高动态环境中可能难以适用,且需要系统先验知识(如用户位置),这对实时解决方案并不现实。相较而言,学习算法可通过低复杂度系统迭代学习解决问题,且无需完整先验信息。此外,无人机轨迹常基于非学习视角(如凸优化[22])在2D场景中建模,但实际部署需考虑三维(3D)空间。2D与3D部署模式将改变无人机轨迹规划,并对多项性能指标产生影响,因此需评估算法在不同维度的适用性。由于传统2D方法难以捕捉3D空间复杂性,部分基于深度强化学习(DRL)的研究正致力于此问题[23][24]。现有用户层假设(如静态用户与固定用户-基站关联)可能与实际存在偏差,因此需考虑用户移动性假设。
为系统研究无人机辅助空天地一体化网络(SAGIN)设计中基于学习的方法,需对主流学习方法进行客观、前沿的综述与对比分析。本研究的主要贡献总结如下:
-
提供了无人机辅助SAGIN完整技术覆盖框架。
-
在考虑2D与3D无人机轨迹设计的实施路径下,构建了无人机辅助SAGIN的通用问题模型。
-
针对无人机辅助SAGIN适用的学习算法(如强化学习、深度强化学习、满意度学习与启发式方法)进行了前沿讨论。
-
基于核心体验质量(QoE)指标,结合实际部署考量,对各类算法方法开展一致性与系统化评估。
本文聚焦于优化SAGIN中无人机的轨迹规划、部署位置与资源分配。这些优化对实现吞吐量、覆盖范围、公平性、系统负载与QoE等关键性能指标具有决定性意义。为此,我们深入探究了Q学习、多臂赌博机算法(MAB)、深度Q学习、启发式方法(如粒子群优化[PSO])及满意度学习等多种算法,揭示其在有效整合天基、航空与地面组件方面的能力。这些算法提供了创新解决方案,例如自适应决策与计算高效的实际应用路径。此外,我们在真实SAGIN部署场景中开展综合性仿真,对比各类算法性能以突显其相对优势与局限。与现有综述不同,本研究专注于无人机辅助SAGIN的算法路径。通过剖析这些算法及其实际部署考量,我们为无人机赋能一体化网络的研究者提供了宝贵洞见与设计指南。
选择强化学习与粒子群优化算法用于SAGIN优化的决策源于该一体化网络范式的独特挑战。强化学习因其对动态环境的适应性、复杂决策能力与经验学习特性而被选用,这些特点使其适合真实SAGIN场景建模。粒子群优化则因其群体优化机制、全局与局部搜索平衡性、简洁性与高效性而被采纳。这些算法因其在整合SAGIN天基、航空与地面组件复杂性方面的适用性而被特别选取。本文探讨了其在该领域的应用,并重点阐述了其在实际SAGIN部署场景中的优势与局限。
论文剩余部分结构如下:第二章综述SAGIN近期发展动态;第三章提出联合优化问题的数学建模;第四章概述强化学习方法并讨论适用于SAGIN的典型Q学习与多臂赌博机算法;第五章探讨SAGIN的深度强化学习路径;第六章阐述SAGIN的满意度学习方法;第七章分析基于粒子群优化的启发式方法;第八章评估各算法性能并讨论开放挑战;第九章为结论性评述。
SAGIN中的强化学习
强化学习(Reinforcement Learning, RL)是一种基于反馈的机器学习技术,智能体通过选择动作并观察其后果来学习与环境交互[49][50]。理论上,RL算法采用由环境与智能体集合构成的马尔可夫决策过程(Markov Decision Process, MDP)框架。智能体面临探索与利用的权衡:既需利用当前最高奖励的动作,又需探索其他动作以优化对动作奖励值的估计。RL算法的核心要素定义如下:
智能体:决策主体,通过探索环境采取行动,并接收与其动作关联的奖励。
环境:智能体所处并与之交互的情境。
动作:智能体执行的决策行为。
奖励:智能体执行动作后从环境获得的反馈,用于评估其表现。
状态:智能体执行选定动作后,环境返回的当前情境。
价值函数:在给定策略下,表示各状态经折扣因子调整后的预期回报。
接下来,详细阐述学习算法的分类,这对理解其在SAGIN中的适用性与效能至关重要。本研究中的学习算法基于关键特征与方法论进行分类,包括模型基础与无模型、价值基础与策略基础、在线策略与离线策略算法。
模型基础与无模型算法
• 模型基础算法:此类算法利用显式环境模型进行决策并学习最优策略。通常需要构建系统动态的预测模型以估计未来状态与结果。
• 无模型算法:与之相反,无模型算法通过与环境直接交互学习最优策略或价值函数,无需显式建模系统动态。其依赖试错学习机制,不要求系统动态的先验知识。
价值基础与策略基础算法
• 价值基础算法:旨在学习环境中不同动作或状态关联的价值函数。其核心在于估计特定动作的预期回报或效用,并基于最大化该价值函数选择动作。
• 策略基础算法:直接学习将状态映射至动作的策略或行为函数。不单独估计每个动作的价值,而是通过优化策略参数直接寻找最优策略。
在线策略与离线策略算法
• 在线策略算法:基于当前策略生成的数据更新策略。直接优化当前遵循的策略,虽能实现更稳定的学习,但可能收敛速度较慢。
• 离线策略算法:利用与当前优化策略不同的(通常为探索性)策略生成数据进行学习。虽能通过多样化数据源提升学习效率,但需采用重要性采样等技术以应对数据分布与目标策略的不匹配问题。
在众多RL算法中,聚焦于文献中广泛用于解决各类应用问题的多臂赌博机(MAB)与Q学习算法。需特别指出的是,近期研究验证了深度确定性策略梯度(DDPG)与近端策略优化(PPO)在类似网络场景中的有效性,凸显了其处理复杂决策任务与优化系统性能的能力。然而,这两种RL算法专为连续动作空间设计。在DDPG中,行动者网络直接输出连续动作值,支持连续动作空间下的精细化控制;PPO则通过神经网络参数化策略并采用随机梯度上升优化,同样适用于连续动作空间。因此,DDPG与PPO均适用于动作非离散的场景。由于本研究主要关注离散动作空间而非连续空间,故未对这两种RL方法进行专门对比,但此方向为未来研究提供了拓展空间。

