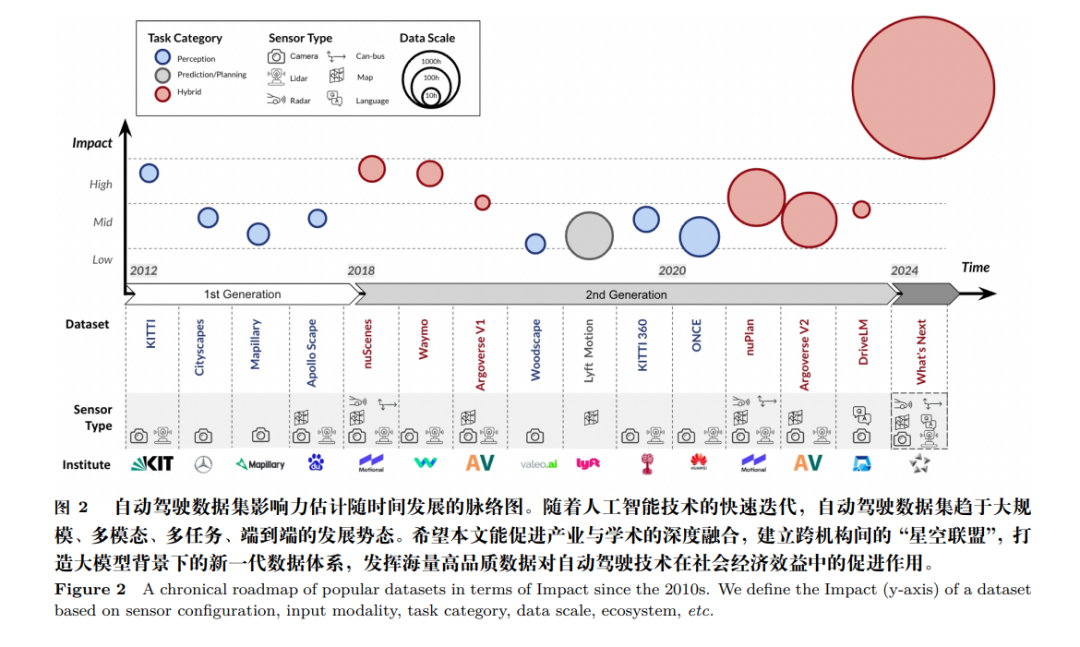
随着自动驾驶技术的不断成熟与应用,系统性梳理开源自动驾驶数据集有利于产业生态良性 循环。现有自动驾驶数据集可大致分为两代,第一代数据集的传感模态复杂度相对较低、数据集规 模相对较小,且大多局限于感知级任务,以发布于 2012 年的 KITTI 为代表。相比于第一代数据集, 第二代数据集的特征为传感模态复杂度较高、数据集规模与多样性较丰富、所设置任务从感知扩展 到预测、规控上,以 2019 年前后提出的 nuScenes、Waymo 为代表。本评述联合学术界、产业界同仁, 首次系统性梳理了国内外七十余种开源自动驾驶数据集,对如何构建高质量数据集、数据在算法闭 环体系中发挥的核心作用、如何利用生成式大模型规模化生产数据等进行了总结。此外,就未来第三 代自动驾驶数据集应该具备的特质和数据规模,以及需要解决的科学与技术问题,我们进行了详细 分析与讨论。希望本文的归纳与展望能促进新一代自动驾驶数据集与生态体系的建设、推动关键领 域自主原创与科技自强的发展。更多内容请参见 https://github.com/OpenDriveLab/DriveAGI。
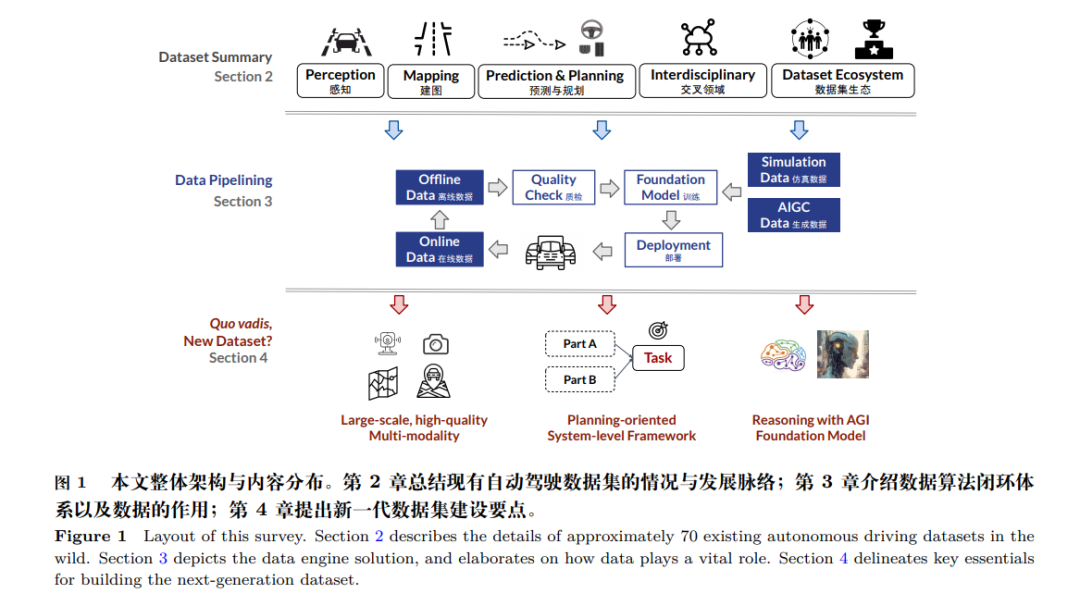
当前发展人工智能已经成全球之势,引发了新一轮国际竞争,许多国家已将其上升为国家战 略 [1∼3]。习近平总书记曾多次强调 [4],人工智能是新一轮科技革命和产业变革的重要驱动力量,加 快发展新一代人工智能是我们赢得全球科技竞争主动权的重要战略抓手,是推动我国科技跨越发展、 产业优化升级、生产力整体跃升的重要战略资源。国务院在《新一代人工智能发展规划》[1] 中明确, 以人工智能技术突破带动国家创新能力全面提升,引领建设世界科技强国进程,其中凸显了以自动 驾驶为代表的智能运载工具的关键性作用,自动驾驶技术的突破有利于加快人工智能关键技术转化 应用和促进技术集成与商业模式创新。 作为人工智能重要应用领域之一,自动驾驶有望重塑现有的交通和运输模式,大大提高交通效 率和安全性,深刻影响着未来的城市和社会发展。中共中央、国务院印发《交通强国建设纲要》 [5] 明确,加强智能网联汽车包括智能汽车、自动驾驶、车路协同等在内的研发,形成自主、可控、完 整的产业链。现如今,我国智能网联汽车产业迈入了商业化的试水和起步阶段,道路测试和示范应 用场景趋于成熟,自动驾驶功能技术加速迭代,车联网应用场景日益丰富,各层面相关法规政策加 速出台 [6],共同推动市场进入高速发展期。自动驾驶技术需要大量数据来训练算法模型,以识别和 理解道路环境,从而做出正确的决策和行动,实现准确、稳定和安全的驾驶体验。数据的建设对于 自动驾驶技术的发展至关重要。以美国特斯拉公司为例,截至 2023 年第二季度,其完全自动驾驶测 试版系统(Full Self-Driving Beta)的总行驶里程已达到前所未有的 3 亿英里(约 4.83 亿公里),并 将随着测试用户规模的扩大实现指数增长。特斯拉所积累的海量数据和驾驶场景是保持其算法优势 的重要原因。另一方面,自然语言处理和通用视觉领域大模型的出现,更加印证了海量高质量数据 的重要性,给予自动驾驶的数据集建设以启发。 图 1 展示了本文主要内容与组织架构。第二章从自动驾驶任务侧,将数据集分为感知类、建图 类、预测与规划类数据集,分别介绍各种类型数据集现状及发展,并围绕社区生态以及相关国际赛 事展开数据集影响力方面的讨论。第三章面向数据算法闭环体系,对比多家商业解决方案,针对数 据算法闭环中数据标注与质量把控、仿真技术、基于大模型的数据生成以及自动标注技术环节进行 阐述。第四章就新一代数据集应有的特性进行展望。 本文系统地梳理了现有的自动驾驶数据集。图 2 展示了公开数据集按照时间发展的脉络与分类 (见第 2.1节)。该图以数据集发布时间为横轴、数据集影响力估计值为纵轴,其中数据集影响力估 计值由数据集质量与数据生态决定,具体定义在 2.2 节中说明。根据不同数据集的传感模态复杂度、 数据规模与场景丰富度、任务多样性等综合因素,我们把目前开源的近百种数据集分为两代:第一 代数据集以 KITTI [7] 为标志,该数据集于 2012 年提出,输入传感模态由前视摄像头与激光雷达构 成,并提出了一系列综合感知任务。第二代数据集由 nuScenes [8] 及 Waymo [9] 数据集为代表,传 感模态复杂度变高,环视相机、激光雷达、定位信息以及高精地图成为常见组成部分,下游任务面 向感知、建图、预测与路径规划综合任务。随着对自动驾驶任务认知不断加深,数据集建设呈现传 感模态不断丰富、数据集规模和场景丰富度不断扩充、由单一感知任务演变为感知及决策综合性任 务的发展趋势。 随着自然语言和视觉大模型的迅速发展,自动驾驶数据集的建设迎来了新的机遇和挑战。传统 的数据集搭建需要经过多传感器标定、数据采集、数据标注与清洗等多个步骤。传统数据搭建方案存在采集成本过高、过度依赖人力标注、标注质量难以把控等问题,如何有效提高数据质量并降低 数据标注成本逐渐成为数据侧的新研究热点。近年来出现新的数据集搭建方法,如人工智能生成内 容(Artificial Intelligence Generated Content,AIGC),该技术可以生成逼真的城市道路环境、多 类型的交通参与者、道路标志标线、天气状态等多种数据元素,构建出逼真的自动驾驶场景,用于 面向多流程自动驾驶任务的算法测试与评估。通过 AIGC 技术获得的合成数据不受地点、时间和气 候等条件的限制,可以覆盖更广泛的场景和环境,尤其是罕见但十分重要的危险场景。因此,通过 AIGC 生成自动驾驶数据可以大大降低数据获取成本和缩短自动驾驶研发流程。然而,AIGC 生成 的虚拟环境与真实世界的差异性仍然较大,生成数据的质量和适用性需重点关注。 自动驾驶技术研究已经步入深水区,面向集成化多任务、复杂人机交互、多类型驾驶任务的应用, 对新一代的自动驾驶数据在数据体量、质量、精细化加工等方面提出了更高的要求。通过第二章和第 三章中对现有数据集与技术的总结分析,我们认为新一代自动驾驶数据集需要具备以下特点:(1)传 感器类别全覆盖,数据量充足并全面覆盖各种自动驾驶场景,并具有高质量的原始数据与标注;(2) 数据组织形式灵活多样,可以覆盖自动驾驶短中长期发展需求,并能够充分支持端到端框架、世界 模型等任务新范式;(3)面向智能化,能够赋能对自动驾驶系统可解释性的检验,并具有语言等支 持逻辑推理的数据。 综上,本文的贡献如下:(1)全面分析现有自动驾驶数据集分布、侧重点等,提出数据集综合 性影响力估计指标,并对现有数据集归纳总结;(2)分析搭建高质量自动驾驶数据集的关键要素与 核心科学技术问题;(3)联合产业界,分析实际自动驾驶诉求,展望与规划大模型背景下的新一代 自动驾驶数据集。