EMNLP 是自然语言处理领域的顶级会议,EMNLP 2023 将于 12 月 6 日 - 10 日在新加坡举行。大会官方公布了今年的论文获奖情况,包括最佳长论文(1 篇)、最佳短论文(1 篇)等。 https://2023.emnlp.org/
最佳长论文**
**


论文:Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning * 论文链接: https://www.zhuanzhi.ai/paper/29fca732d2f01931972a2a63a7dc4674
论文摘要:
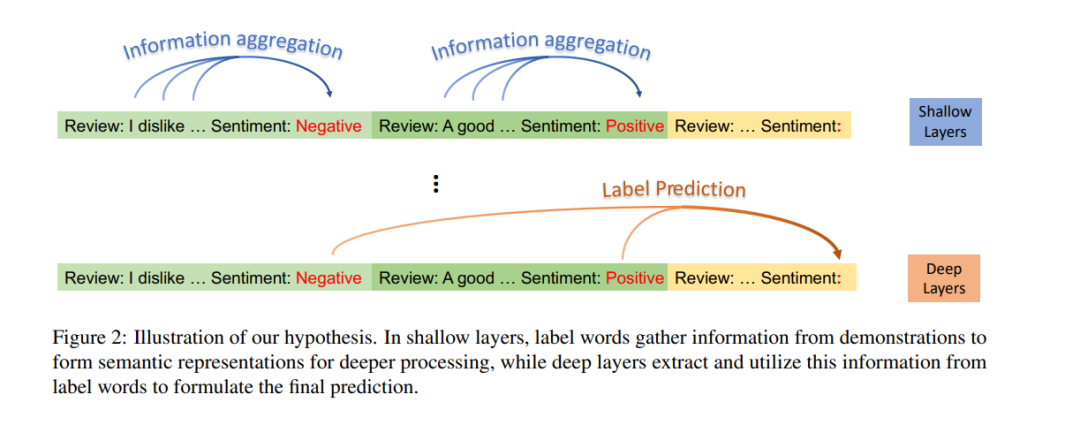
在上下文学习(ICL)作为大型语言模型(LLMs)的一种有前景的能力出现时,它通过提供示例演示来执行多种任务。然而,LLMs如何从提供的上下文中学习的底层机制仍未被充分探索。 在这篇论文中,我们通过信息流的视角来探讨ICL的工作机制。我们的发现揭示了演示示例中的标签词功能作为锚点:(1)在浅层计算层处理期间,语义信息聚集到标签词表征中;(2)标签词中的综合信息作为LLMs最终预测的参考。基于这些洞见,我们引入了一种锚点重新加权方法来提高ICL性能,一种演示压缩技术来加快推理,以及一种用于诊断GPT2-XL中ICL错误的分析框架。我们发现的应用再次验证了所揭示的ICL工作机制,并为未来的研究铺平了道路。
最佳短论文


论文介绍:https://aclanthology.org/2023.emnlp-main.767/
论文摘要:最小贝叶斯风险(MBR)解码输出在某个效用函数上对模型分布具有最高预期效用的假设。已经证明,在条件语言生成问题中,尤其是在神经机器翻译中,MBR在人类和自动评估中都能提高比束搜索更高的准确性。然而,标准的基于采样的MBR算法在计算上比束搜索显著更昂贵,需要大量样本以及对效用函数的二次数调用,限制了其应用性。我们描述了一种MBR算法,该算法逐渐增加用于估计效用的样本数量,同时根据通过自助采样获得的置信度估计剪除不太可能具有最高效用的假设。 我们的方法相比标准MBR需要更少的样本,并极大地减少了对效用函数的调用次数,同时在准确性方面在统计上无可区分。我们在三种语言对上的实验中展示了我们方法的有效性,使用chrF++和COMET作为效用/评估指标。

其他奖项