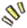中国学者14篇国际顶会IEEE VR 2020论文集锦

2020年IEEE虚拟现实国际会议(IEEE VR 2020)已于3月27日落下帷幕。该会议是虚拟现实领域的国际顶会,CCF A类会议。会议创始于1993年,已经发展为参会人数上千的国际盛会,是聆听大咖主题演讲、精彩学术报告、结识科研同行、拓展人脉网络的极佳场所。
图图整理了IEEE VR 2020中来自中国讲者的14篇论文,与从事虚拟现实领域的图粉分享,文末附论文打包获取方式哦~~

以下内容由CCF虚拟现实与可视化技术专业委员会(CCF TCVRV)主任——天津理工大学罗训教授提供。


罗训,天津理工大学教授、博士生导师,中国计算机学会理事、杰出会员、虚拟现实与可视化专业委员会主任。主要研究方向为虚拟现实中的自动建模技术,数据驱动的大规模仿真,以及普适计算。
E-mail:sherwoodluo@gmail.com

图片来源网络
Investigating Bubble Mechanism for Ray-Casting to Improve 3D Target Acquisition in Virtual Reality
气泡机制对于改善在虚拟现实3维目标获取中光线投射的研究
论文作者:鲁逸沁,喻纯,史元春
作者单位:清华大学计算机科学与技术系人机交互实验室
光线投射(Ray-Casting)是VR/AR中被广泛应用的交互手段。用户一般通过手柄投射出一束射线,穿过需要选择的目标来进行交互。受到气泡式光标——2D图形界面中利用动态伸缩区域进行目标选择的启发,论文研究了如何将这种气泡机制(Bubble Mechanism)应用到光线投射中,即气泡式射线。气泡机制会在每次射线移动时指定一个“最近”的目标作为候选目标,使得用户不必准确地穿过目标来选择目标。

论文首先探究了射线与目标距离的定义标准,提出了基于欧氏距离和角距离的两种方式。然后引入用户评价来对气泡式射线的渲染方式进行了迭代式探索,最终确定了一种基于半透明圆盘、渲染在无穷远处的平滑式气泡渲染方式。
之后进行了两个用户实验,来分别研究气泡式射线在简单和复杂环境下的表现。结果显示,气泡机制能够有效地提高射线选择的性能;同时,基于角距离的气泡式射线在绝大多数场景中,都能够比其余技术具有更高的选择速度和用户满意度,并减少用户疲劳度。



Multiple-scale Simulation Method for Liquid with Trapped Air under Particle-based Framework
基于粒子框架的夹带气体液体多尺度模拟方法
论文作者:刘斯诺,王犇,班晓娟
作者单位:北京科技大学计算机与通信工程学院
论文针对液体模拟过程中夹带的气体进行建模和分析,提出了一种基于粒子框架的多尺度模拟方法,以实现高效、逼真的气液流体模拟。
首先,根据流体粒子的动能和速度差建立统一的气体粒子生成模型。然后,为不同尺寸的气体材料分别建立动力学模型。对于大尺寸气体粒子,使用逆扩散方程首次实现了传质现象,并使用新的高阶核函数实现气气耦合与气固耦合,改善了随机初始化可能造成的不稳定结果。
对于小尺寸气体粒子,论文通过Shlick随机函数实现布朗运动来改善周期分布失真,并根据气体与流体的耦合程度改进了速度计算方程,有利于提高流体模拟的逼真度和丰富度,并使方法能有效与现有粒子方法集成。

图1 垂直注水实验
图1中(a)为真实注水场景,(b),(c),(d)为模拟结果,其中左侧子图为粒子结果,右侧子图为渲染结果。在粒子结果中,小尺寸气体粒子和大尺寸气体粒子分别标记为红色小点和蓝色球体。通过调整控制参数μ,可以改变不同尺寸气体粒子所占的比例,以实现不同的视觉效果。(b),(c),(d)中大尺寸气体粒子的比例分别为0%,8.23%和13.80%。其中,(d)的视觉效果更类似于真实场景。

图2 倾斜注水实验
为了更清楚地观察到布朗运动的效果,本实验仅渲染了小尺寸的气体粒子。通过调节布朗系数κ,气体粒子的运动自由度发生改变。图2中(b),(c),(d)中的κ值分别为1、0.8、0.6。当κ= 1时,相当于没有添加布朗运动,气体粒子的分布呈现出周期性。添加布朗运动后,视觉效果得到极大的改善。我们发现,κ= 0.8时可获得最佳视觉效果。

图3 大尺寸气体粒子传质实验
半径小的气体离子趋向于将空气挤压到半径较大的空气粒子中,且体积差异较大的两个空气粒子将具有更快的传质速度。在最后一个子图中,由于两个空气粒子的体积比接近0.8,因此它们之间的气体传输速度非常慢。



Real-time VR Simulation of Laparoscopic Cholecystectomy based on Parallel Position-based Dynamics in GPU
GPU下基于并行位置动力学的实时胆囊切除术仿真
论文作者:潘俊君,张雷宇,禹鹏,沈阳,王海鹏,郝爱民,秦洪
第一作者单位:北京航空航天大学计算机学院
虚拟手术技术改变了外科医生的学习模式,它可以在视、听、触觉上实现手术过程的模拟,降低了病人真实手术的风险和传统外科培训的成本。腹腔镜胆囊切除是微创外科的代表性手术,发病率高,其基于虚拟现实的手术仿真及应用对住院医师培训具有重要意义。
论文提出了一种基于并行位置动力学的胆囊切除虚拟手术框架,其主要贡献如下:
1. 在位置动力学算法的框架下,通过图着色并行求解,提出了并行位置动力学的软体变形算法。应用CUDA对着色后的约束并行求解,极大提高了系统的实时性。
2. 结合热扩散模型,在物理准确的基础上设计了软组织电凝灼烧与肝胆分离的模拟算法。依据是否达到沸点,改变四面体结构来实现脂肪消融。在肝胆分离阶段,通过施加额外的约束提出了一种多模型混合联动的方法。
3. 搭建了胆囊切除虚拟手术系统,最后与北京航空总医院合作,邀请经验丰富的外科医生利用匿名打分的方式对该系统进行了验证与评估。

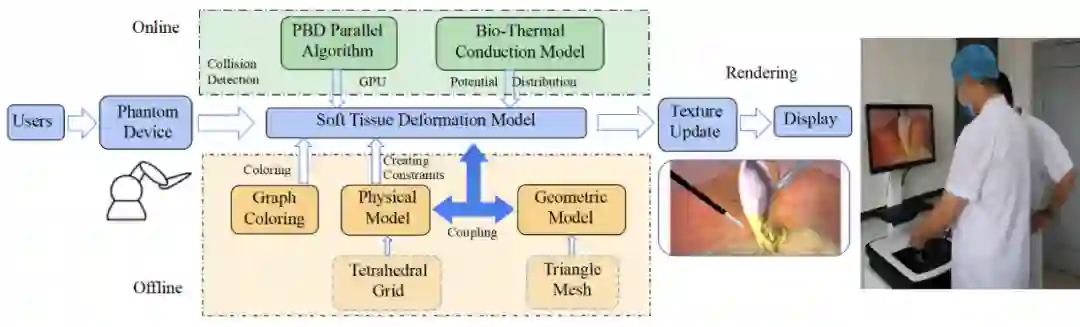
Exploring Visual Techniques for Boundary Awareness During Interaction in Augmented Reality Head-Mounted Displays
增强现实头戴式显示器交互边界的可视化技术研究
论文作者:徐温格,梁海宁,陈宇正,李想,喻康尤
作者单位:西交利物浦大学计算机科学与软件工程系
尽管悬空手势交互是一种更自然的输入方法,但当前增强现实(AR)头戴式显示器(head-mounted displays, HMDs)所支持的手部交互区域十分有限。因此,在交互过程中,尤其是在动态任务中(例如移动虚拟物体),用户很容易将手移出AR设备的手部识别范围。与常见的悬空交互问题(例如手势识别,手臂/手疲劳,或不自然的悬空交互方式)相比,AR设备中的边界感知问题很少受到关注。
论文针对AR HMDs下虚拟物体的移动任务,探索了交互边界的视觉提示技术。首先,通过系统的形成性研究,确定了用户在没有任何交互边界信息的提示下使用AR HMDs交互时所遇到的问题。基于前期研究结果,提出了4种提示交互边界的方法(即静态界面,动态界面,静态坐标线和动态坐标线),并将这些方法与基准方法(即无交互边界提示)进行了对比评估。用户实验结果表明,论文所提出的交互边界的可视化方法有助于用户使用AR HMDs完成基于手部的动态交互任务,但其效果和应用取决于用户。


Transfer of Coordination Skill to the Unpracticed Hand in Immersive Environments
在沉浸式环境中将协调技能传递给未经训练的手的方法
论文作者:肖汕, 叶旭鹏, 郭雅秋, 高博宇, 龙锦益
作者单位:暨南大学信息科学技术学院

双手协调控制技能对我们的日常生活至关重要。但是,卒中通常会导致上肢一侧手的肌肉无力或僵硬,从而导致肢体间协调技能受损。因此论文设计了一种类似于游戏的互动系统探索可视化反馈对协调技能传递的影响。具体贡献包括下面两个方面:
1. 参与者通过以下4种训练策略同时绘制非对称的三边正方形(例如U和C)来学习双手协调技能,从而完成控制任务:
执行并看到双手任务(BH-BH)
用右手执行任务并看到化身的双手动作(RH-BH)
不执行任务而是看到化身的双手动作(noH-BH)
执行并看到单手任务(RH-RH)。
结果发现与其他训练策略相比,BH-BH和RH-BH后的学习表现更好。
2. 检查了虚拟手真实性表示对RH-BH后协调技能转移效果的影响。发现,训练后的表现随着虚拟手的真实感水平而提高。
这些结果表明,具有真实虚拟手的RH-BH方法将导致协调技能转移到未练习的手,从而为卒中患者偏瘫手的协调技能的学习和康复提出了一种新的方法。

Real Walking in Place: Hex-Core-Prototype Omnidirectional Treadmill
在原地真正的行走:海克斯核心原型全向跑步机
论文作者:王子峣,魏海坤,张侃健,谢丽萍
作者单位:东南大学自动化学院
移动问题是虚拟现实中(VR)至为关键的问题之一,自然的移动体验对于探索虚拟世界尤为重要。目前针对该问题有诸多解决方案,大体可分为,如按键、摇杆、超距传送等模拟方式,以及如大空间行走、重定向、全向跑步机等真实行走方式。其中模拟方式由于并非真正行走,往往会带来如晕动症,方向感丢失等问题。由于大空间行走和重定向由于所需空间较大,因此在针对于小房间规模的VR体检,全向跑步机将会是最有效的解决方案。
在全向跑步机这项分支领域中,又可以根据跑步机表面形式分为低摩擦表面类型以及驱动表面类型。目前有诸多商用产品是基于低摩擦表面类型的基本原理,通常使用滚珠或铁氟龙等构成低摩擦表面。驱动表面类型的万向跑步机往往是通过不同的机械结构构成速度场将人体位移进行抵消,但由于机械结构限制使得机器往往过于庞大。

论文提出的新型全向跑步机,运用速度合成与分解的原理来形成全向速度场,与当前的最佳系统相比,HCP的高度仅为其的40%。



Dynamic Artificial Potential Fields for Multi-User Redirected Walking
面向多用户重定向行走的动态人工势场研究
论文作者:董天阳、陈贤威、宋一凡、应文渊、范菁
作者单位:浙江工业大学计算机学院
为用户提供逼真的无限空间感知和虚拟环境的自然行走功能是当前虚拟现实技术研究的热点之一。为了解决共享同一物理空间多用户漫游的碰撞问题,该论文在动态人工势场构建方法研究的基础上,提出了一种面向大规模虚拟场景漫游的多用户重定向行走方法。该方法能够产生排斥力将用户“推离”障碍物和其他用户,并利用吸引力将用户“吸引”到无障碍的物理空间,有助于增强用户的VR体验。
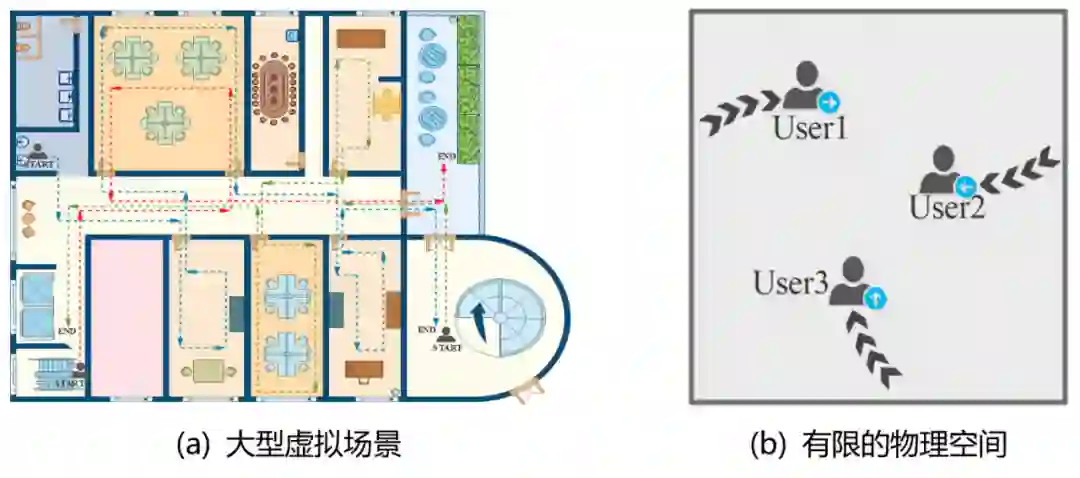
该论文的主要工作包括:
1.根据漫游用户受到的物理空间中墙壁和其他用户产生的排斥力,以及用户自己当前的运动状态,对用户的优先级进行排序,并按照优先级在用户未来的位置创建用户化身,通过用户化身对其他用户产生一定的排斥力。
2.为了更好地利用物理空间和让用户尽可能分散于空间的不同位置,对物理空间栅格化,并根据每个网格的中心与物理空间中其他用户之间的距离计算和优化引导目标的位置,尽可能将用户引导到无障碍的区域。
3.当用户将与障碍物或其他用户碰撞时,把动态人工势场中所有力矢量组合为一个合力矢量,触发重置机制并引导用户转向与合力矢量对应的方向,从而减少有限物理空间中多个用户沉浸式漫游的用户碰撞和重置次数。

Data-Driven Spatio-Temporal Analysis via Multi-Modal Zeitgebers and Cognitive Load in VR
虚拟现实环境下以数据驱动的多模态授时因子和认知负载时空分析
论文作者:廖昊东,谢宁,李慧媛,李雨杭,苏建平,姜峰,黄炜朋,申恒涛
作者单位:电子科技大学
论文针对 VR 环境中的人机工效开展研究。从多模态数据处理的角度对授时因子(Zeitgeber) 进行采集、量化与分析用户对于VR环境的时间长度感知。在此基础上,结合认知负荷理论(Cognitive Load Theory)共同探究授时因子和认知负载对 VR 环境中用户时距估计和临境感的影响。进一步结合主观问卷调查与客观生理指标测量方法,提出以多模态数据驱动的时距估计与临境感的预测模型。
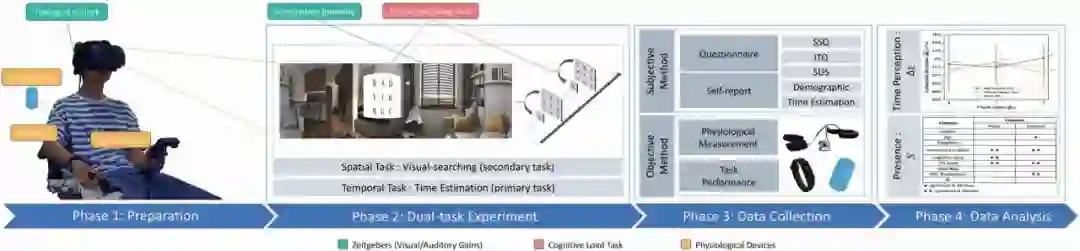
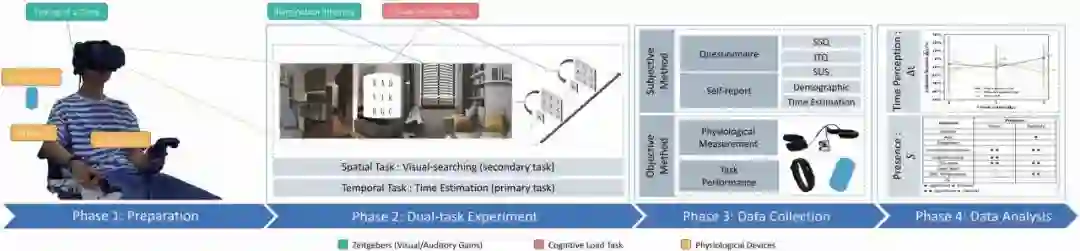
实验结果表明论文提出的预测模型对于涉及时间感知和临境感的沉浸式虚拟环境的搭建具有指导意义。在VR与非VR对比实验中,结果显示出VR场景比起传统平面非VR场景在影响用户时间感知方面确实更具潜力。在VR应用设计中,为达到更好的任务表现和降低用户的主观时距估计,实验结果表明应将听觉授时因子(背景音)纳入到环境构建中。

ThermAirGlove: A Pneumatic Glove for Thermal Perception and Material Identification in Virtual Reality
支持虚拟现实中材料温度触感的气动手套
论文作者:蔡绍禹,柯平川,鸣海拓志,朱克宁
第一作者单位:香港城市大学创意媒体学院
触觉交互技术一直是虚拟现实领域的研究重点。当我们在现实中触摸真实物体的时候,我们可以感受出不同物体材料表面的热学特性的不同,例如金属物体摸起来要比木头的凉一些,所以可以通过人体接触不同材料时皮肤表面温度的变化来推断材料的组成。有研究表明,人类可以通过温度信号来辨别一些热学特性有很大差别的材料,如泡沫,玻璃,铜等。

论文提出ThermAirGlove, 一种为手掌提供可控的温度反馈的气动手套,以模拟VR中不同温度的物体和材料,提升VR的沉浸感。ThermAirGlove可以基于半无限大物体导热模型来模拟人手与不同材料接触时皮肤温度的瞬态变化过程,来支持用户在VR中对不同材料的辨别。

在半无限大物体导热模型中,Ts(t)和To(t)分别表示接触时皮肤和物体的温度变化。

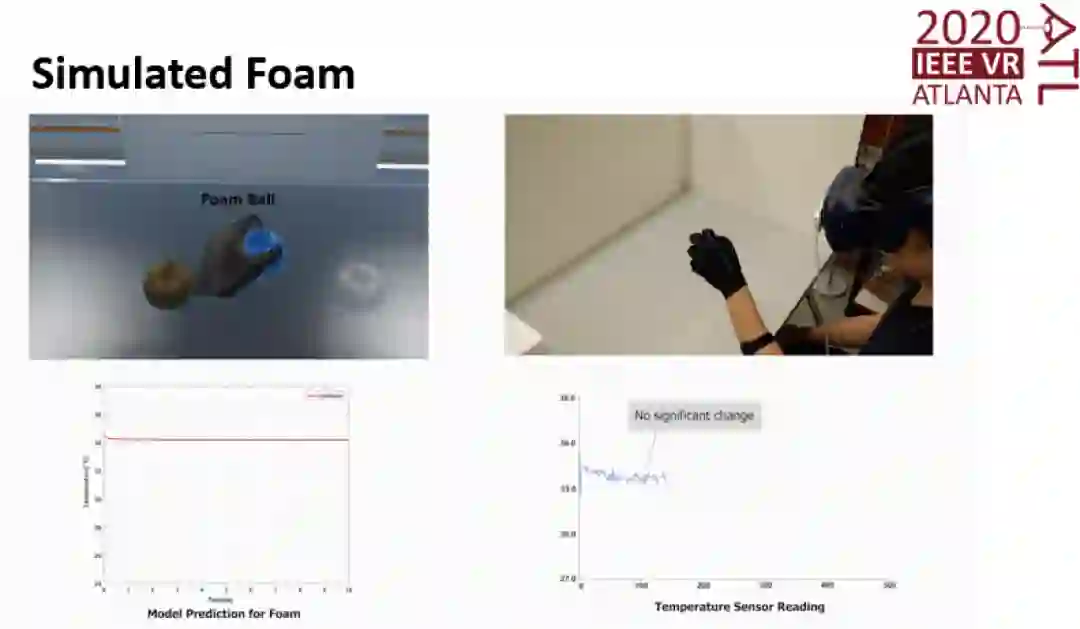
温度追踪实验结果
温度追踪实验结果表明ThermAirGlove可以很好地追踪到理论模型中皮肤表面的温度变化。论文之后进行的一系列用户感知实验和VR沉浸感的用户研究结果支持了系统的有效性。此项技术可被运用在多个场景中,例如VR游戏或者多媒体,以及一些利用虚拟现实的康复训练中。


Weakly Supervised Adversarial Learning for 3D Human
基于弱监督对抗学习的点云中三维人体姿态估计
论文作者:张子豪,胡磊,邓小明,夏时洪
第一作者单位:中国科学院计算技术研究所
针对基于点云的3D人体姿态估计方法,现有方法的成功往往建立于3D人体关节标注的大规模数据上。但是,由于身体各关节之间的自遮挡以及3D点云中的标注困难等原因,从输入深度图像或点云中标注3D人体关节是费力且容易出错的过程。

为了解决这个问题,论文提出了一种基于点云的3D人体姿态估计的弱监督对抗学习框架。该框架能够同时利用带有2D人体关节标注的弱监督数据和带有3D人体关节标注的全监督数据。同时,为了解决监督信号不足造成的人体姿态歧义性,采用对抗学习来确保估计的人体姿态合理且有效。
与以前的方法中仅使用深度图像的2D表示或3D表示不同,论文同时采用点云和深度图像对其进行表示。采用state-of-the-art的stacked hourglass网络模型从输入的深度图像中提取2D人体关节,这有助于获得初始3D人体关节并有效地进行深度点云的降采样。针对不同情况的标注数据,利用示性函数激活不同的损失函数,从而达到扩宽训练数据,提升模型鲁棒性的目的。得益于弱监督的对抗学习框架,论文方法可以从点云中获得准确的3D人体姿态。在ITOP数据集和EVAL数据集上的实验表明,论文方法可以达到state-of-the-art的性能。




DGaze: CNN-Based Gaze Prediction in Dynamic Scenes
基于卷积神经网络的动态场景视觉注意预测模型
论文作者:胡志明、李胜、张琮毅、易康睿、汪国平、Dinesh Manocha
第一作者单位:北京大学
用户的注视行为分析和预测是一个被广泛研究的问题。在虚拟现实领域中,用户的注视信息可以被应用到很多不同的方面。目前虚拟现实中眼动追踪的解决方案主要是基于眼动仪。眼动仪虽然准确,但是价格昂贵、需要校准、且并非广泛可用。此外,眼动仪只能够测量用户当前时刻的注视位置,不能预测用户在未来时刻的注视。因此,有必要研究眼动仪的替代方案。

DGaze模型的结构
在DGaze论文中,作者对用户在动态虚拟场景中的注视行为进行了充足的分析。在分析的基础上,作者提出了一个新颖的基于CNN的注视预测模型DGaze,该模型可以用于虚拟现实头盔(HMD)中的注视预测。DGaze模型结合了动态物体位置序列、用户头动速度序列、以及场景内容的显著性特征来预测用户的注视位置。作者也提出了该模型的一个变体DGaze_ET,DGaze_ET可以通过结合眼动仪提供的用户在过去时刻的眼动数据,来以更高的精度预测用户在未来时刻的注视位置。该论文的数据和源代码已经发布,网址为

Outdoor Sound Propagation Based on Adaptive FDTD-PE
基于自适应FDTD-PE的室外声音传播
论文作者:刘世光, 刘锦
作者单位:天津大学
声音是仅次于视觉的重要感知通道,声音传播的模拟可以提供用户声源方向及空间尺寸等信息,可以大大提高用户在虚拟环境中的沉浸感。考虑到大气的不均匀性及地面效应,论文提出了一种基于自适应FDTD-PE的预计算室外声音传播模型,用来模拟室外三维虚拟场景的声音传播。在柱坐标系下将三维场景划分为二维平面,将每个二维平面划分为近声源复杂区域和远声源区域。

在近声源复杂区域采用自适应FDTD计算时间的方法计算声压,及远声源区域采用自适应PE计算区域的方法计算声压。并针对远声源区域的声音传播特性,提出基于函数拟合的声压数据压缩编码方法。然后,根据函数拟合的编码方法,提出了基于线性插值法的解码及可听化的方法。
实验表明,该方法能较为准确且快速地模拟出室外不均匀大气中的声音传播而且能够较为真实且快速地模拟出地面效应对声音传播的影响。

SalBiNet360: Saliency Prediction on 360° Images with Local-Global Bifurcated Deep Network
基于局部-全局分叉深度网络的360°全景图显著性预测
论文作者:陈东文、青春美、徐向民、朱焕升
作者单位:华南理工大学电子与信息学院
随着虚拟现实应用的发展,在360°全景图上预测人类的视觉注意对理解用户行为至关重要。基于360°全景图全局和局部视觉显著性的特点,论文提出了一个用于360°全景图显著性检测的框架(SalBiNet360)。如图1所示,该分叉深度网络分成了两个子网络,分别用于全局和局部的显著性检测。
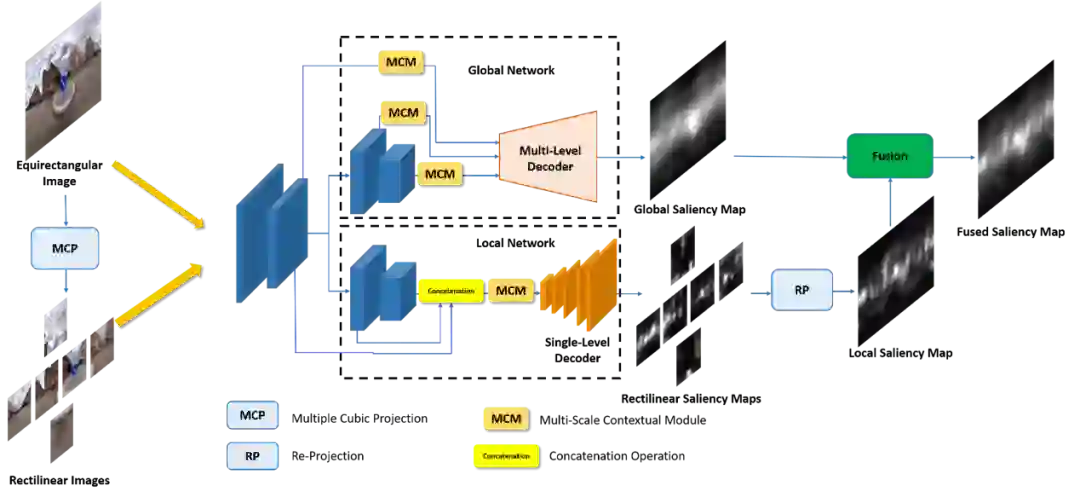
图 1 SalBiNet360的网络框架
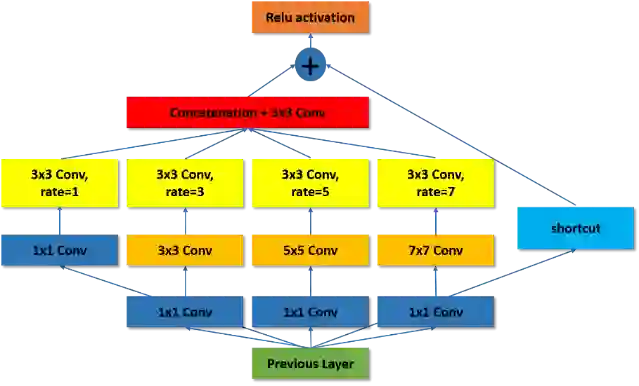
图 2 多尺度上下文模块的架构

图 3 多层解码器的架构
其中,全局子网络包含3个多尺度上下文模块(图2)和一个多层解码器(图3)来提取360°全景图的多尺度上下文特征,并生成一张全局显著图;而局部子网络只包含一个上下文模块和一个执行卷积—上采样操作的单层解码器,以减少局部显著图的冗余度。最后利用线性组合方法,结合全局和局部显著图的特点,生成最终的融合显著图。在两个公开数据集上进行的定性和定量实验表明,SalBiNet360的性能优于当前最先进的方法,特别是能够更好地预测低显著性区域和图像左右边界附近的区域。

HiPad: Text entry for Head-Mounted Displays Using Circular Touchpad
虚拟现实中基于圆形键盘的文本输入技术
论文作者:江海燕,翁冬冬
第一作者单位:北京理工大学光电学院
用于虚拟现实移动式头戴式设备(HMD)的文本输入技术仍然是一个未解决的问题。手持控制器设备已经成为VR中交互以及文本输入的重要方式。然而,目前常用的基于控制器的文本输入技术——手柄射线射击技术,繁琐并且不够高效,特别是对于长文本的输入而言。此外,由于在较大的空间中选择字符,长时间大范围的动作容易引起疲劳。因此,该研究基于目前常见的手柄控制器,利用圆形触摸板,结合圆形输入布局,实现快速、准确的单手文本输入技术。通过将所有字符分配到圆形布局圆周的6个键中,基于空间模型、语言模型以及贝叶斯算法,实现了单词级别的输入。

图中展示了用户利用该技术输入文本的过程。用户研究结果表明,通过60个短语的简短训练,新手用户在60个短语的输入训练以后使用“VE布局”每分钟可以输入13.57个单词,修正错误率0.22%;使用“TP布局”每分钟可以输入11.60个单词,修正错误率0.30%。该输入技术基于目前常用手柄控制器设计,具有良好的可用性以及应用前景。






前沿进展 | 多媒体信号处理的数学理论
中国卫星遥感回首与展望
单目深度估计方法:现状与前瞻
目标跟踪40年,什么才是未来?
10篇CV综述速览计算机视觉新进展
算法集锦 | 深度学习在遥感图像处理中的六大应用
封面故事 | 从传统到深度:火灾烟雾识别综述
封面故事 | 光场数据压缩综述
学者观点 | 结合深度学习和半监督学习的遥感影像分类
编辑推荐 | 视频 + 地图!四维信息助力实景中国
深度学习+图像降噪,如何解决“卡脖子”问题?
专家推荐|高维数据表示:由稀疏先验到深度模型
专家报告 | AI与影像“术”——医学影像在新冠肺炎中的应用
专家推荐|真假难辨还是虚幻迷离,参与介质图形绘制让人惊叹!
学者推荐 | 深度学习与高光谱图像分类【内含PPT 福利】
专家报告|深度学习+图像多模态融合
专家报告 | 类脑智能与类脑计算
100页PPT!道尽Pansharpening 的数学建模机理
实战例题!200+PPT带你看懂监督学习
118页PPT!机器学习模型参数与优化那些事儿~
专家开讲 | 机器学习究竟是什么?
Hinton,吴恩达,李飞飞 !大师深度学习课程集锦
羡慕别人中了顶会?做到这些你也可以!
如何阅读一篇文献?
共享 | SAR图像船舶切片数据集
资源分享| 不知道如何获取最新的算法资讯?快来这里看一看
资源分享|热门IT资讯号推荐
《中国图象图形学报》2020年第2期目次
《中国图象图形学报》2020年第1期目次
《中国图象图形学报》2019年第12期目次
《中国图象图形学报》2019年第11期目次
《中国图象图形学报》2019年第10期目次
本文内容仅供学习交流
版权属于原作者
欢迎大家关注转发!
编辑:秀 秀
指导:梧桐君
审校:夏薇薇
总编辑:肖 亮
声 明
欢迎转发本号原创内容,任何形式的媒体或机构未经授权,不得转载和摘编。授权请在后台留言“机构名称+文章标题+转载/转发”联系本号。转载需标注原作者和信息来源为《中国图象图形学报》。本号转载信息旨在传播交流,内容为作者观点,不代表本号立场。未经允许,请勿二次转载。如涉及文字、图片等内容、版权和其他问题,请于文章发出20日内联系本号,我们将第一时间处理。《中国图象图形学报》拥有最终解释权。
与你同在
前沿 | 观点 | 资讯 | 独家
电话:010-58887030/7035/7418
网站:www.cjig.cn