
上海交通大学ReThinklab近期在国际机器学习顶会ICML2024上录用10篇论文,涉及时间序列、组合优化的学习求解、量子多体问题的学习求解、神经科学、分布外泛化、跨模态大模型等领域,其中包括1篇与联想的合作论文。 ICML是由国际机器学习学会(International Machine Learning Society,IMLS)主办的年度机器学习国际顶级会议之一。具有广泛而深远的国际影响力,受到来自学术界和工业界的广泛关注,也是中国计算机学会(China Computer Federation, CCF)推荐的A类会议。unsetunset【论文1】How Graph Neural Networks Learn: Lessons from Training Dynamicsunsetunset 作者:杨晨晓,吴齐天,David Wipf,孙若愚,严骏驰
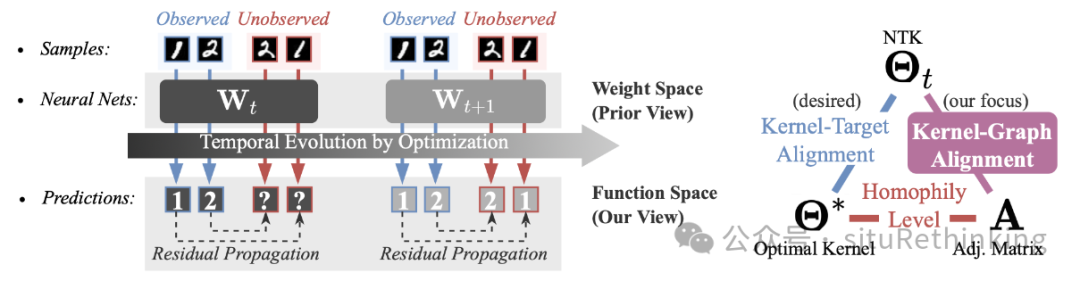
简介:深度学习长期以来的一个目标是以更可解释的方式描述黑箱模型的学习行为。对于图神经网络(GNNs),现有工作在研究它们表达能力上已经取得了很大的进展,但在优化过程中GNNs是否真的会学习到预期的函数仍然不清楚。为填补这一空白,我们研究了它们在函数空间中的训练轨迹。特别的,我们发现通过梯度下降训练GNNs时,它们通过对齐核函数和图来隐式地利用图结构来更新学习到的函数。这种从优化视角出发的新分析框架可以提供关于学到的GNN函数何时以及为何能够泛化的解释,这也与它们在异质图上的局限性相关。从实际角度来看,它还提供了设计新算法的原则。我们通过展示一个远比GNNs简单高效的非参数算法来例证这一点。该算法通过显式使用图结构来更新学习到的函数,而且性能可以始终与GNNs竞争。unsetunset【论文2】SEMIQ: Semi-Supervised Learning of Quantum Data with Application to Quantum System Certificationunsetunset 作者:唐叶辉,杨念祖,龙马彪,严骏驰
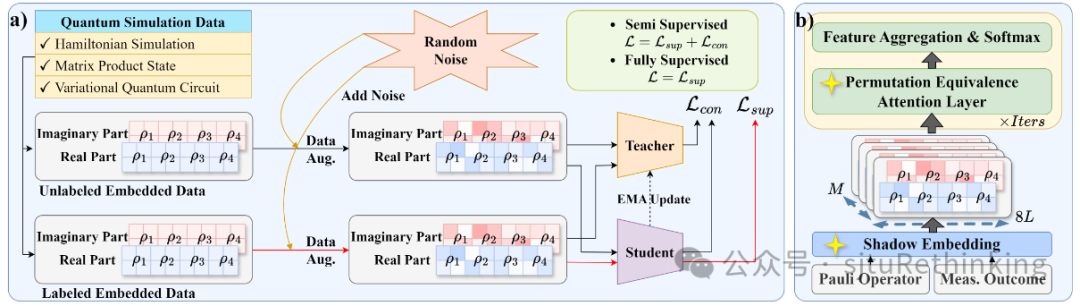
简介:量子系统验证旨在通过分析量子测量的统计数据来估计量子设备的准确性和正确功能。传统的监督方法依赖于大量标记的测量结果来推断未知量子系统的属性,但这一过程需要的计算和存储资源随着量子位数的增加而呈指数级增长。文章提出了半监督学习方法SEMIQ,主要针对量子系统验证中量子态分类这一子问题。SEMIQ通过特殊的网络架构来保证无序量子测量的排列不变性,并在量子测量不确定性面前保持模型预测的鲁棒性。该研究模拟了两种量子系统并采集测量数据,包括海森堡模型和变分量子电路(VQC)模型,系统规模达到50量子位(高达2^50维)。为了处理无序量子测量数据,SEMIQ设计了影子嵌入(Shadow Embedding)和排列等价注意力层(PEA)。模型的训练方法结合了监督损失和一致性损失,通过教师和学生模型(mean-teacher)的双重学习机制来提高模型的性能。实验结果验证了SEMIQ在海森堡模型和VQC模型上的有效性,即使在标签稀缺的情况下,也能显著提高对量子系统的认证精度,效果整体优于传统的监督模型。总的来说,这项研究为AI4Quantum中的半监督学习开辟了新的可能性,并为实际量子计算应用中处理有限标签的量子数据提供了一个有效的框架。unsetunset【论文3】MorphGrower: A Synchronized Layer-by-layer Growing Approach for Plausible Neuronal Morphology Generationunsetunset 作者:杨念祖*, 曾锴鹏*,逯昊天,元泽欣,陈丹妮,吴叶鑫,姜升殿,吴家祥,王宜敏,严骏驰
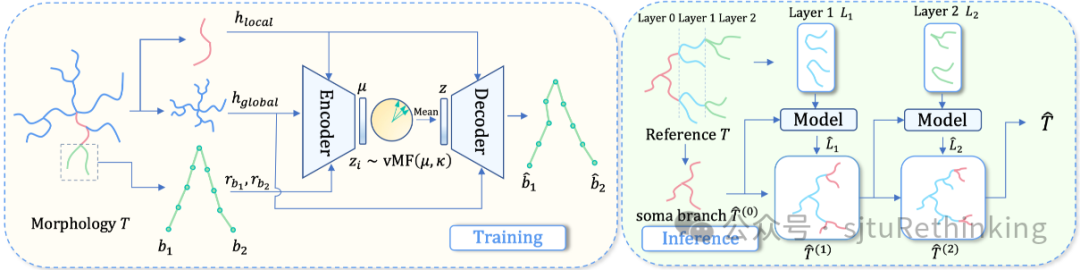
简介:神经元形态样本(树状)数据对于研究大脑功能和理解神经退行性疾病至关重要。然而,现实中获取形态数据成本高昂。因此,已有研究者提出了一些用于生成形态学的传统计算方法,以快速扩充神经元形态样本数据库。但是,传统方法严重依赖专家设置的规则和参数调整,这使得在不同类型神经元的形态之间进行泛化变得困难。最近,MorphVAE被提出用于生成形态样本,这是现有的唯一的基于机器学习的方法。然而,其生成的样本缺乏可信度,即生成的形态学看起来不够真实,而且大部分生成的样本在拓扑上是非法的。为了解决MorphVAE的局限性,本文提出了MorphGrower。MorphGrower模仿神经元自然生长机制进行生成。具体来说,MorphGrower逐层生成形态样本,每个后续层都以先前生成的结构为条件。在生成每层时,MorphGrower利用分支对这一细粒度作为基本生成块,同一层内的分支对们可以同时生成。这种方法能够确保生成结果的拓扑合法性,且提高了最终生成形态样本的真实性。在四个真实数据集上的实验结果表明,MorphGrower显著优于MorphVAE。此外,通过电生理反应模拟,我们从神经科学的角度进一步证明了我们生成样本的可信度。unsetunset【论文4】ACM-MILP: Adaptive Constraint Modification via Grouping and Selection for Hardness-Preserving MILP Instance Generationunsetunset 作者:郭子奥,郦洋,刘畅,欧阳文理,严骏驰
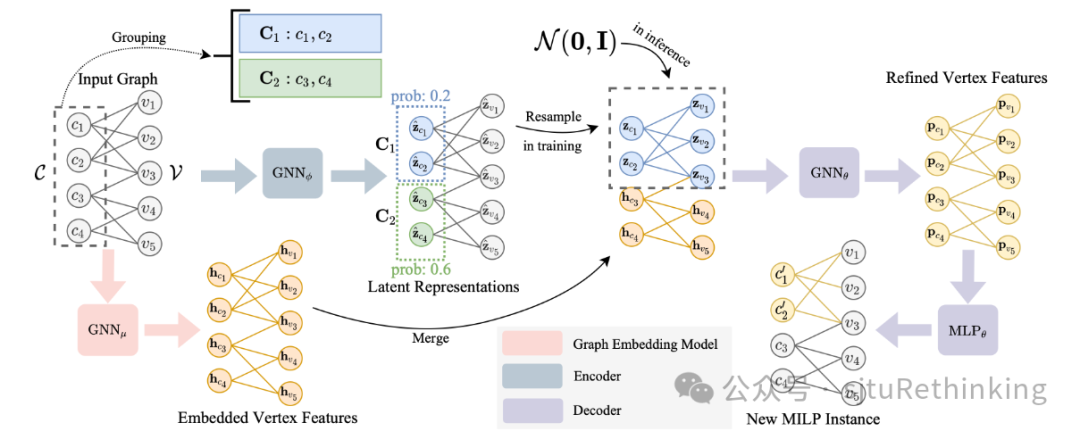
简介:随着混合整数线性规划(MILP)研究的不断发展,数据的重要性变得越来越显著。高质量的数据对于改进基于机器学习的求解器以及传统求解器的开发至关重要。然而,由于MILP的复杂性和特异性,以及数据隐私和专有约束,可用的真实世界数据相当稀缺,催生了对MILP实例生成方法的需求。目前已有的MILP生成方法主要依赖于通过迭代随机修改单一约束来生成新实例,但这种方法忽视了约束之间相互关联以及问题的固有结构,影响生成实例的质量。针对以上问题,我们提出了ACM-MILP框架,用于MILP实例生成,旨在实现自适应约束修改和约束之间关系建模。ACM-MILP采用基于隐空间内概率估计的自适应约束选择机制来保持实例特征。同时,ACM-MILP通过社区检测对强相关约束进行分组和耦合,实现了考虑约束依赖性的集体修改。实验证明,在我们的框架下,生成实例与原实例求解难度的相似性得到了显著提高。此外,在下游任务中,我们展示了ACM-MILP生成的实例在超参数调整中的有效性。unsetunset【论文5】UP2ME: Univariate Pre-training to Multivariate Fine-tuning as a General-purpose Framework for Multivariate Time Series Analysisunsetunset 作者:张昀浩,刘洺皓,周晟洋,严骏驰
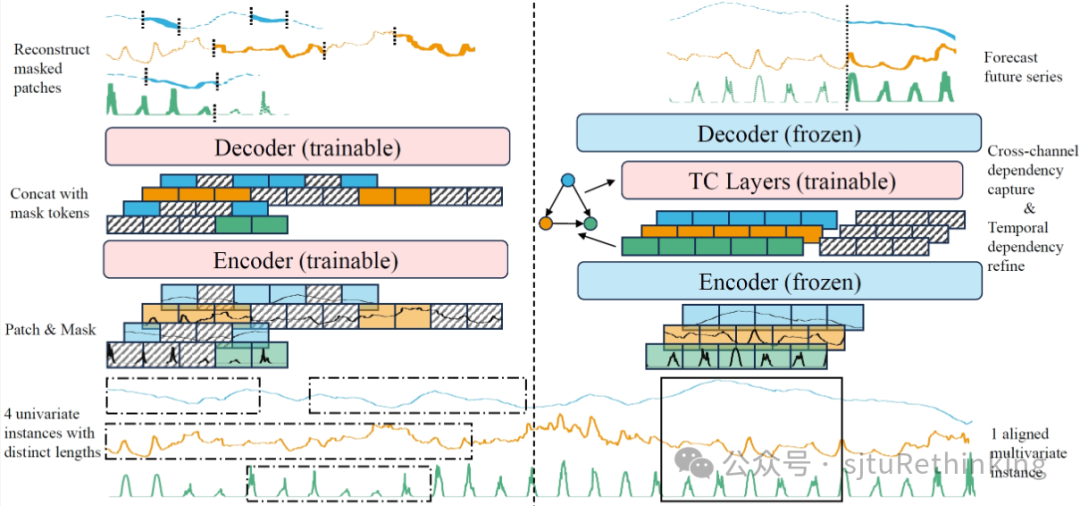
简介:尽管自监督预训练在CV和NLP领域取得了巨大的成功,但在多变量时间序列分析上,预训练模型依然落后于针对预测、缺失补全和异常检测等任务专门设计的专用模型。在这项工作中,我们提出了一个通用框架,名为UP2ME(Univariate Pre-training to Multivariate Finetuning)。在下游任务未确定时,UP2ME可进行与任务解耦的预训练。一旦下游的任务及任务设定(例如预测长度)确定,UP2ME可以在不经过微调的情况下直接使用预训练参数给出合理的初始解,这是之前的模型无法做到的。UP2ME还可通过微调得到进一步增强。技术上,我们设计了一种从单变量预训练到多变量微调的范式,以解决多变量时间序列中时间和通道的异质性。在单变量预训练中,我们生成具有不同长度的单变量实例进行Masked AutoEncoder(MAE)预训练,完全忽略跨通道依赖。预训练模型通过将下游任务建模为特定的掩码—重构问题来直接处理这些任务。在多变量微调中,UP2ME利用预训练Encoder构建通道之间的依赖图,以增强跨通道依赖关系的捕获。在八个真实世界数据集上的实验表明,UP2ME在预测和缺失补全方面达到了SOTA效果,并在异常检测中接近专用模型的性能。unsetunset【论文6】Node Out-of-Distribution Detection Goes Neighborhood Shapingunsetunset 作者:鲍天怡,吴齐天,蒋泽天,陈奕廷,孙嘉伟,严骏驰
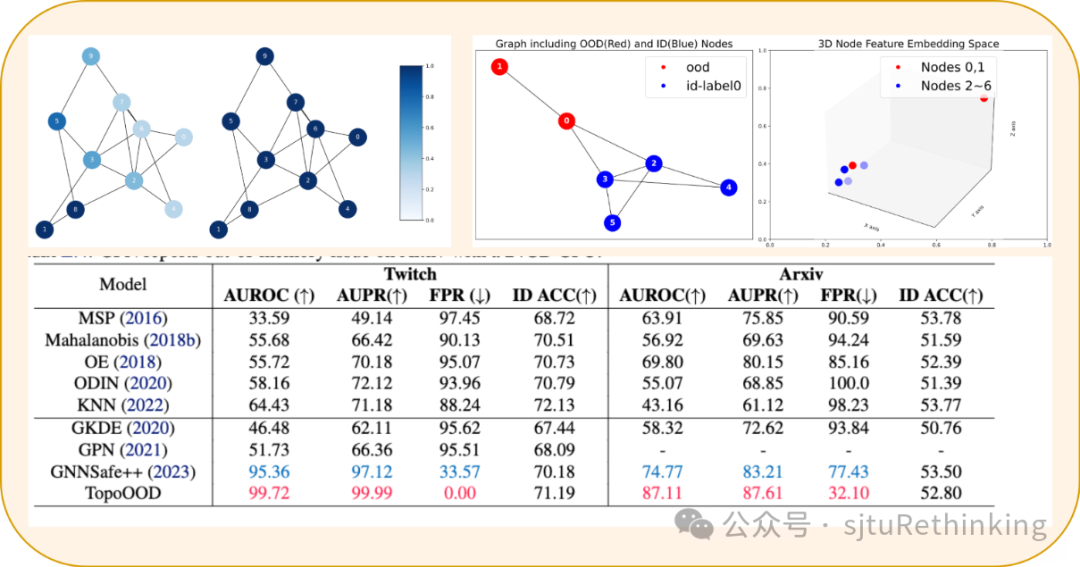
简介:探究分布外检测(Out-of-Distribution Detection)对于提高机器学习模型的鲁棒性至关重要,特别是在安全和高风险领域的实际应用中。在当前的机器学习领域,尽管对图像的分布外检测研究已相当丰富,但针对结构化数据,如图数据的OOD检测研究还相对有限。在传统的图神经网络(GNN)模型中,常常假设训练和测试数据具有相同的分布,这在现实世界的应用中往往不成立。与此同时,图数据内部节点的相互依赖性使得针对其OOD检测更为复杂。针对这一问题,我们设计提出的针对图数据的分布外检测模型——TopoOOD,从节点的邻域拓扑出发,将节点的相互依赖特征结合起来。我们创新设计了节点级迪利克雷能量,用以衡量节点邻域中的扰动程度,结合节点的导出子图结构权重作为置信度评分。通过在多个数据集上的广泛实验验证,TopoOOD显示出显著优势。此外,我们还针对图数据设计了一种新的实验设置,为图结构数据的OOD检测扩展出新的基准测试。unsetunset【论文7】OT-CLIP: Understanding and Generalizing CLIP via Optimal Transportunsetunset 作者:史良良,范济国,严骏驰
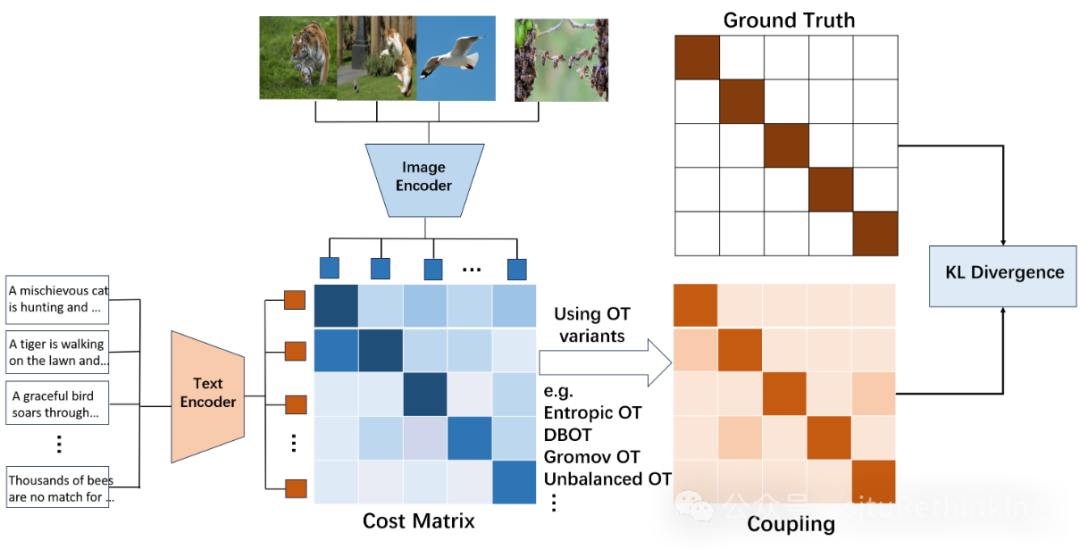
简介:我们提出从最优传输(Optimal Transport,OT)的角度来理解对比语言图像预训练模型(CLIP)。具体而言,我们展示了CLIP的训练是逆OT的一种体现,而CLIP所采用的两个InfoNCE损失对应于修改过的熵正则化OT的双层优化问题的特殊情况。然后,我们将原始的CLIP损失推广为基于OT的损失函数族,使用正则化OT的变体(例如融合Gromov OT、非平衡OT等),并展示了它们在图像和文本领域的公共数据集上在下游任务中的优越性能。我们还通过使用OT的工具重新思考了CLIP的推理阶段,并提出采用融合Gromov OT进行(零样本)分类,其中预测基于图表示,图中的节点为图像和文本用于图匹配。通过我们的新技术,我们展示了如何将零样本分类推广到其他更加灵活的零样本任务,并取得了有竞争力的性能:长尾分类和选择性分类。前者假设已知标签的先验分布,而后者仅要求对一部分样本进行预测,但需要高置信度的预测结果。unsetunset【论文8】Learning Diffusion Fields for Shift-Robust Message Passingunsetunset 作者:吴齐天,聂帆,杨晨晓,严骏驰
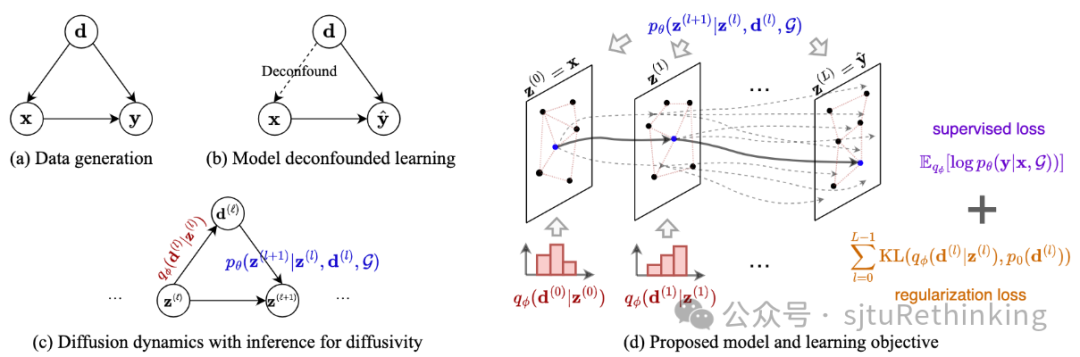
简介:如何提升机器学习模型在分布外数据上的泛化性是一个基础问题。本文从几何约束的扩散方程出发,研究了非欧式数据(例如图)的分布外泛化问题。特别地,本文基于消息传递机制(即图神经网络与Transformer的共有设计)与(热)扩散方程的本质联系,首先提出将扩散方程中的扩散率函数定义为一个概率分布下的随机样本,从而使得扩散模型可以建模数据间的多重不确定的相互作用。基于此,本文进一步提出了一个基于因果干预的变分目标函数,它可以在理论上引导模型学习数据间稳定的相互作用关系,以帮助提升在分布外数据上的测试性能。在实现层面,本文给出了三种具体的模型实现,分别对应于GCN、GAT和DIFFormer模型的扩展形式,并在多个实验数据集上展示了它们的分布外泛化效果。unsetunset【论文9】On The Emergence of Cross-Task Linearity in Pretraining-Finetuning Paradigmunsetunset 作者:周展鹏*,陈梓俊*,陈一览,张铂,严骏驰 简介:这篇文章在NeurIPS 2023(LLFC)的基础上更进一步,我们发现在预训练-微调的范式下,不同的微调模型之间也满足LLFC的性质,更进一步地,我们称之为Cross-Task Linearity (CTL)。我们发现实际上,在预训练-微调的范式下,网络实际上更近似于一个从参数空间到特征空间的线性映射。CTL将LLFC的定义扩展到了不同数据集上训练的模型上。有趣的是,我们还能用CTL的发现来解释两种常见的模型融合的技术:1)Model Averaging取多个模型在相同数据集上但使用不同超参数配置微调的权重的平均值,以提高准确性和鲁棒性。我们将权重的平均解释为在每一层特征的平均,从而建立了Model Averaging和模型集成(Model Ensemble)之间的紧密联系,进而解释了Model Averaging的有效性。2)Task Arithmetic通过简单的算术操作合并在不同任务上微调的模型的权重,从而相应地控制模型的行为。我们将参数空间中的算术操作转化为特征空间中的操作,从特征学习的角度解释了Task Arithmetic。随后,我们探究了CTL产生的条件,并且强调了预训练对于CTL的重要性。我们通过实验证明,从预训练阶段获得的共同知识有助于满足CTL。我们还初步尝试证明CTL,并发现CTL的出现与Network Landscape的flatness以及两个微调模型之间权重的差距有关。unsetunset【论文10】MILP-FBGen: LP/MILP Instance Generation with Feasibility/Boundednessunsetunset 作者:张亚红,范晨晨,陈东辉,黎丛瑞,欧阳文理,朱明达,严骏驰 简介:该研究提出了一种基于扩散模型生成混合整数线性规划(mixed-integer linear programming, MILP)实例的方法,生成的样例保持了与训练实例的相似性,同时保证了可行性和有界性,复杂困难数据集上的大量实验验证该方法的有效性。

