
北京交通大学ADaM团队两周前在arxiv上传了类o1的代码生成框架o1-Coder的技术报告,马上在外网获得了关注。Hugging Face对论文进行了推荐,成为了当天#2 Paper of the day。
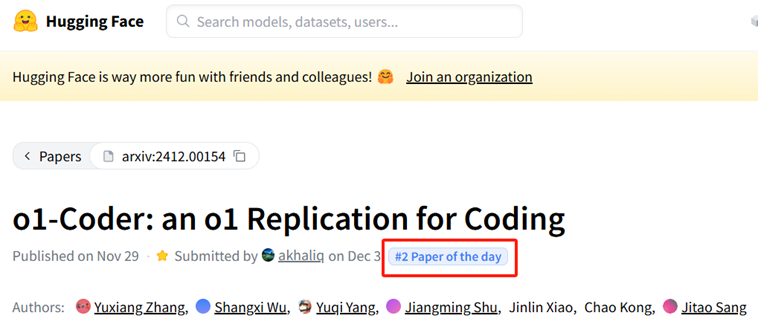
X上也有人对论文进行了分享,2天时间内获得了7万多的阅读量。足见业界对推理大模型这个方向的关注度。
网友表达了对o1-Coder先生成伪代码再生成完整代码的兴趣。
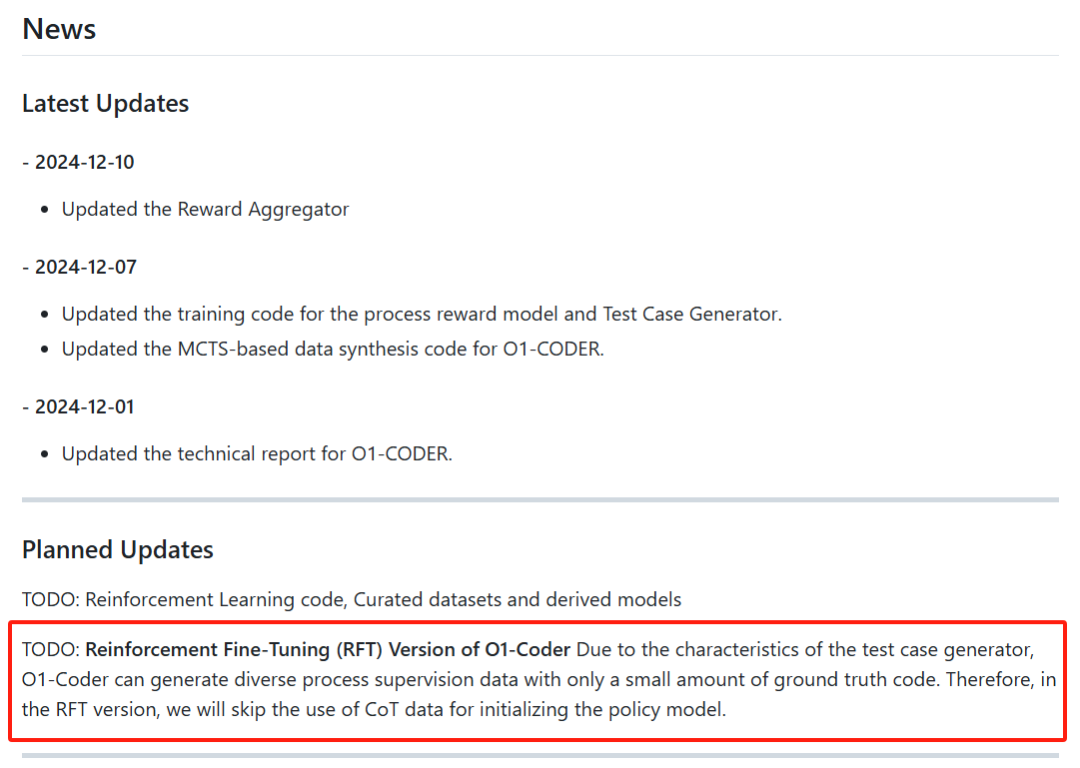
团队昨天在Github开源了o1-Coder项目的代码,包括过程奖励模型训练代码、用于获得结果奖励的测试用例生成器训练代码、合成推理过程数据的蒙特卡洛树搜索代码等。
项目链接:https://github.com/ADaM-BJTU/O1-CODER
值得注意的是,项目主页上将强化微调RFT (Reinforcement Fine-Tuning)的实现作为待更新的计划。相比o1展示的强化微调RFT,字节提出的ReFT需要CoT数据进行监督微调预热,而且在强化阶段没有充分利用过程奖励**。o1-Coder框架支持没有任何推理过程数据情况下的训练**,确实有可能实现RFT的效果。
**1. 引言 **
**
**
目前,实现模型的系统2推理包括三种方法:提示工程、监督学习和强化学习。o1-Coder的报告首先从所采用的方法和面向的任务两个维度总结了最近复现o1的主要工作。

关于方法,o1-Coder希望探索不标注或蒸馏任何推理过程数据情况下的解决方案,选择了强化学习的技术路线。关于任务,可能是高校团队资源有限的原因,只选择了基础的代码生成任务。
面向代码生成任务复现o1有两个主要问题。一是结果奖励,即评估生成代码的正确性。和围棋、数学可以根据游戏规则或提供的答案直接评估不同,代码评估需要在测试环境下运行测试样例来检验。第二个是思考和搜索行为的定义,即过程奖励的对象和粒度,需要设计合适的推理过程和策略行为空间。
对第一个问题,o1-Coder提出训练一个测试用例生成器TCG (test case generator),基于问题来自动生成测试样例,构建标准化的代码测试环境,为模型强化学习训练提供结果奖励。基于DeepSeek-1.3B-Instruct进行SFT和DPO,在TACO数据集上分别获得了80.8%和89.2%的通过率。由于所设计的TCG只需要问题而不需要准确代码,因此可以同时应用推断阶段,作为生成代码质量的验证器,支持inference-time search。
对第二个问题,有两种思路。一种是**“三思而后行”,即先逐步思考,形成完整的思维链,再一起输出最终答案;另一种是类似Quiet-STaR 的“边思考边行动”,在思考的同时同步输出答案的一部分。o1-Coder选择了前者:先分布思考写出完整的伪代码,再基于伪代码生成可运行的最终代码。这样的好处一是适配性,同样的伪代码可以生成不同的具体代码实现;二是粒度可控**,可以通过调整伪代码的详细度控制思考/搜索行为的粒度。在不同规模Qwen2.5上的初步实验发现:**(1)由伪代码生成最终代码的准确率显著高于直接生成最终代码;(2) 包括专门的Coder模型在内,目前LLM生成伪代码的能力不足。**而这也正是要通过推理过程数据和过程奖励来优化的原因。

**2. **** 框架 **
**
**
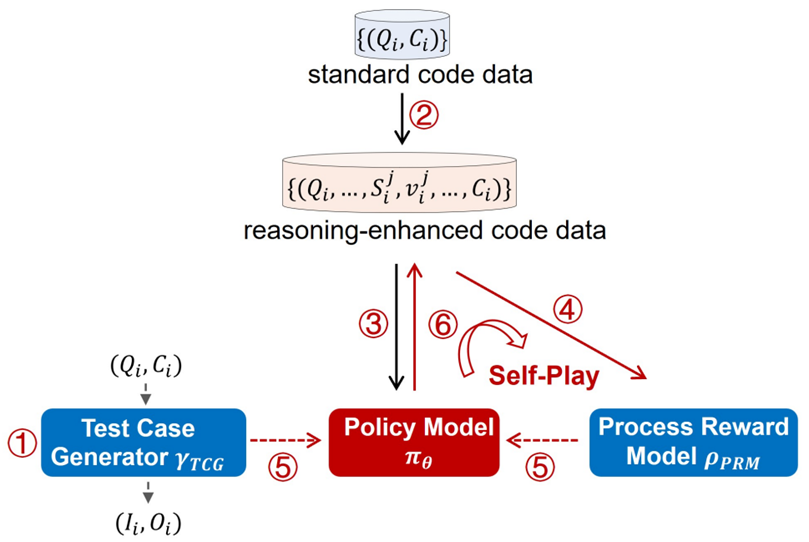
具体来说,o1-Coder设计了一个包含六个步骤的框架。
- 第一步是训练测试用例生成器(TCG),根据问题自动生成测试用例。
- 第二步在原始代码数据集上运行蒙特卡洛树搜索(MCTS),生成包含推理过程的代码数据集,同时包括一个有效性标记来区分正确和错误的推理步骤。
- 基于生成的初始包含推理过程的数据,可以对标准的LLM或代码模型进行微调,初始化策略模型具备“先思考再行动”的行为方式。
- 初始的推理过程数据同时可以用来初始化过程奖励模型(PRM),在RL训练过程中评估评估推理步骤的质量。
- 有了提供过程奖励的PRM和提供结果奖励的TCG,策略模型通过强化学习进行更新。
- 最后,基于更新后的策略模型,可以生成新的推理过程数据。这些新数据反过来用来再次微调PRM(第4步)。因此,步骤4、5和6形成了一个迭代循环,自我对弈self-play不断推动模型的改进。
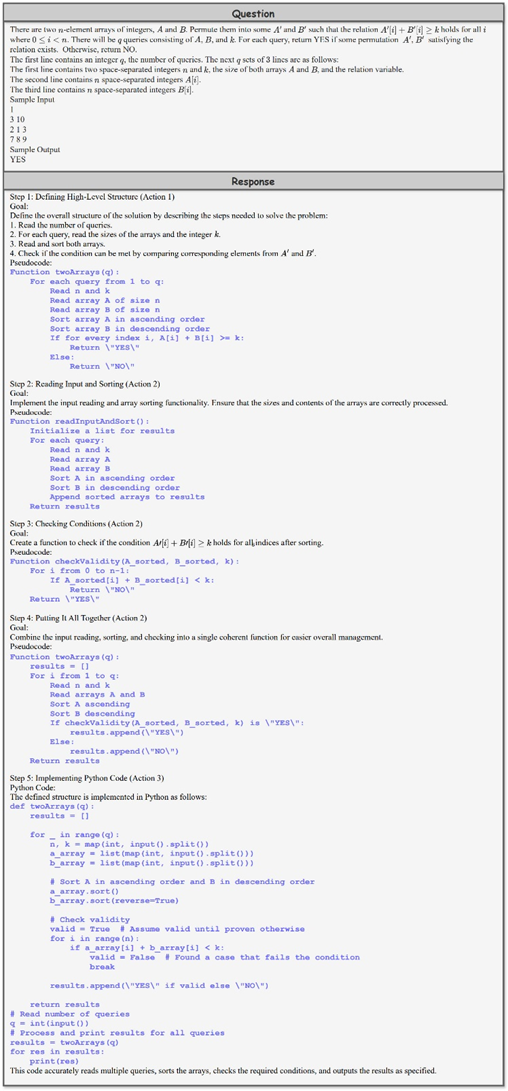
其中,o1-Coder定义了生成伪代码的三种推理过程行为: * 定义伪代码算法结构:概述主要函数的结构和接口,目的是让模型理解整体任务结构,包括每个主要函数的输入、输出和核心功能。 * 细化伪代码:迭代细化第一步中定义的伪代码,逐步明确每个函数的步骤、逻辑和操作。 * 从伪代码生成代码:将伪代码的结构和逻辑准确转换成可执行代码。
需要注意的是,这三个步骤在具体的推理链中会实例化成不同的表达。从报告提供的例子看,每个推理步骤会根据上下文选择行为,并生成相应的伪代码。
**3. 讨论 **
项目主页目前并没有公开数据集和训练得到的模型。但报告中提供了一些有意思的讨论。
Bitter Lesson: Data is All You Need
报告引用了o1研究员Hyung Won Chung总结的过去十几年来AI发展的一个线索:如何高效地将日益增长的算力转化为模型智能水平的提升。具体分为两个阶段:(1)**早期聚焦模型,从SVM到DNN再到Transformer,设计可扩展的模型架构以充分利用算力可以在海量数据上训练有大规模参数的模型;(2)最近转向数据**,预训练阶段的自监督学习和后训练阶段的强化学习,分别致力于有效地利用自然和合成数据。
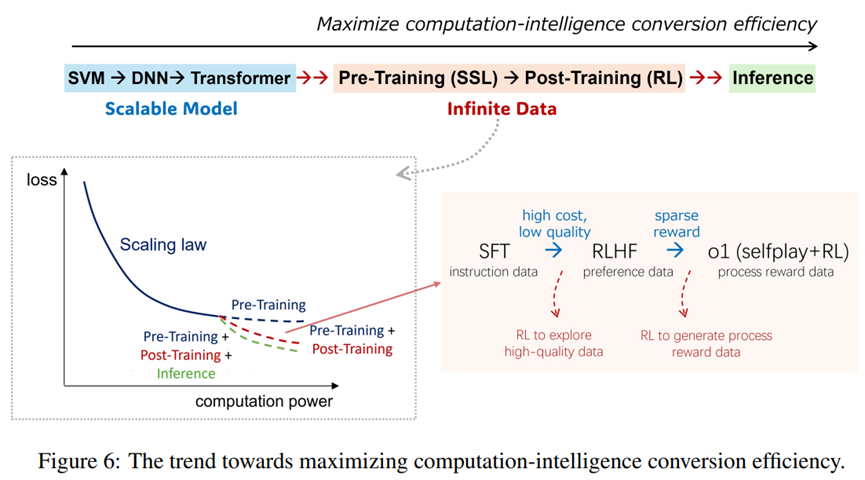
后训练内部又可分成三个阶段:SFT利用高质量任务相关的监督数据、RLHF基于少量标注的偏好数据训练环境以获取理论上无限的反馈数据、和o1所延续的从探索的推理过程中得到的过程奖励信号。
Sweet Lesson: Beyond Human Data
LLM一直受诟病的问题是只能依赖人类记录下来的数据进行学习,o1的成功向我们展示了通过RL来探索数据背后的思维过程的可能,意味着模型从对人类语言的模仿逐步发展为自主的认知。
更有趣的是,这些思维过程不一定局限于自然语言。近期一篇《自然》文章指出:“语言是交流的工具,而非思维的本质。”报告中提到团队发现了一个o1思维链包含无意义文本的例子,有可能这些思维信息不完全对应离散的自然语言。遗憾的是,报告并没有提供这个例子。如果模型为思维过程发展出更高效的内在表征,这将大大提升思维过程和问题解决机制的效率,不仅突破了人类语言数据的局限性,还进一步解锁了模型的潜在能力。
机会:系统1+X -> 系统2+X
SelfPlay RL为探索潜在的过程数据提供了可行的方案,使得许多传统依赖系统1能力的任务可以借助系统2推理方法来增强。如奖励建模、机器翻译、基于检索的生成(RAG)和多模态问答等任务。通过将逐步推理加入任务执行过程,相信可以为不同的任务带来提升。
ADaM团队沿这一思路,在安全对齐方面做了探索,近期提出了“System-2 Alignment”的概念。

论文链接:https://arxiv.org/pdf/2411.17075
首先在复杂的越狱攻击数据上对o1进行了安全测试,包括对抗性提示和数学编码的越狱提示。实验表明,o1模型在安全性表现上有所改进,但仍存在漏洞,特别是针对利用数学编码的攻击。

接着提出实现系统2对齐的三种方法:Prompting、SFT和基于过程监督的RL。报告中给出了prompting和SFT的实验结果,正在将o1-Coder中的self-play RL框架应用于系统2对齐,实现细节和实验结果将在未来版本中呈现。

挑战:编码世界模型
OpenAI已经在o1正式版中加入了多模态能力和函数调用功能。o1-Coder报告中讨论了另一个待改进的方向是推理时间优化。一方面是推理效率的提升—即在单位时间内实现更大的性能提升,另一方面是根据任务的复杂度自适应调整推理时间:包括动态调整系统2推理过程,以及能在系统1和系统2推理模式之间无缝切换的能力。
o1等推理模型在更广泛的现实场景中应用,还要解决两个主要挑战。其中一个是奖励函数如何泛化,目前讨论的比较多了。报告主要讨论的是另一个挑战:规划过程中的环境状态更新。团队负责人桑基韬教授最近在大模型智能生成大会的深度推理论坛上,也提到了这个挑战。
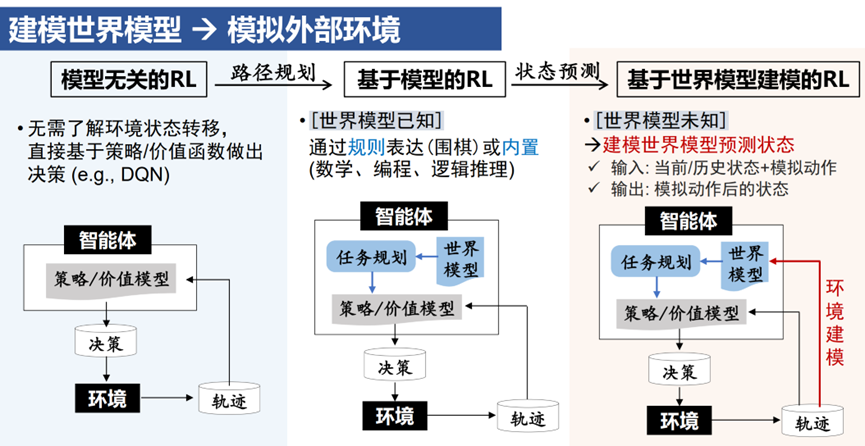
由于类o1的推理模型需要进行路径规划,因此要预测动作执行后的环境状态。像围棋、编程、数学这些任务的世界模型可以通过规则来表达或已经内置于LLM中。而Device Use、具身这些场景的世界模型是不确定的,获取状态更新通常需要与外部环境或模拟器进行交互。规划过程涉及大量行为模拟,这会带来了巨大的算力和时间成本。而且这会导致无法进行在线搜索,因为模型无法通过回溯到先前状态来验证或修正其行为,从而无法进行在线的决策反思和调整。
一个解决方案就是通过构建世界模型来进行状态转移预测,使得智能体不必直接与真实环境或模拟器交互。近期交互内容生成领域,比如Genie-2等工作的发展,为更准确、实用的环境建模提供了积极的前景。
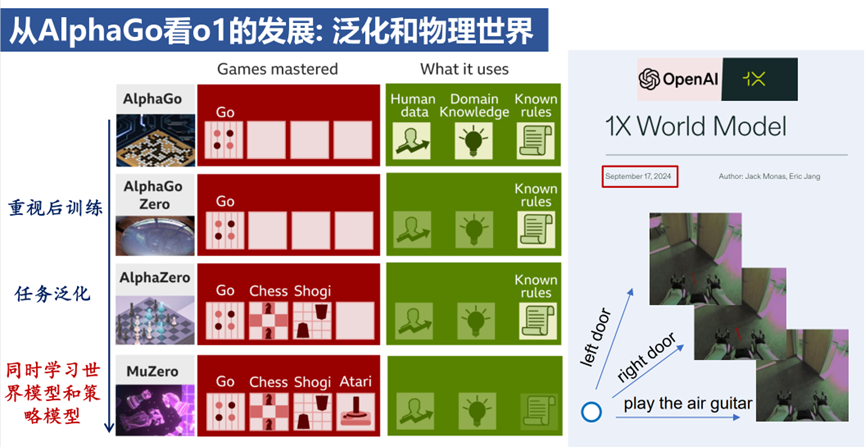
报告的最后从AlphaGo来预测o1可能的发展。AlphaGo通过模仿学习初始化策略网络,使用强化学习微调策略并学习价值网络,再通过蒙特卡罗树搜索(MCTS)作为在线搜索策略,这与LLM的预训练、后训练和推理过程非常相似。AlphaGoZero去掉模仿学习的做法,则跟当前LLM越来越强调后训练阶段不谋而合。 之后,Alpha系列模型向通用化方向发展:AlphaZero被应用到围棋、国际象棋和将棋中。而MuZero旨在应对更复杂的Atari视频游戏场景,这需要一个专门的世界模型来建模状态转移。MuZero的做法是同时更新世界模型和奖励模型,在潜在空间中实现基于模型的规划。这样来看,选择紧凑的状态表示并构建有效的世界模型,也是o1类模型应用于实际场景,特别是解决长程推理任务的关键。报告最后提到了OpenAI在世界模型和具身方向的一个进展:就在o1发布后一周,OpenAI投资的机器人公司1X发布了世界模型项目,项目旨在开发一个预测框架,通过模拟和预测实际环境中行为的结果。这给具身智能领域的o1类推理模型带来了极大的想象空间。
专知便捷查看,访问下面网址或点击最底端“阅读原文”
https://www.zhuanzhi.ai/vip/11fc5883167c00ac391c9323dda4cebc

点击“阅读原文”,查看下载本文