武大提出FarSeg:遥感图像分割新网络,解决前景背景不平衡问题 | CVPR 2020
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:AI算法修炼营

本文收录于CVPR2020,由武大提出的遥感图像的分割算法,主要有意思的点是:基于关系和基于优化的前景建模的方法来解决误报和前景背景不平衡问题,其中基于关系的方法有点类似于自注意力机制,方法值得借鉴;基于优化的方法关键在损失函数的构建,有用到模拟退火算法,可以学习一下。
论文地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Zheng_Foreground-Aware_Relation_Network_for_Geospatial_Object_Segmentation_in_High_Spatial_CVPR_2020_paper.pdf
遥感图像中的地理空间对象分割作为一种特殊的语义分割任务,却始终面临较大的尺度变化,较大的背景类内差异以及前景与背景之间的不平衡等问题。然而,一般语义分割方法主要关注自然场景中的尺度变化,而没有充分考虑大面积遥感图片场景中通常发生的其他问题。在本文中,认为问题在于缺少前景建模,并从基于关系的和基于优化的前景建模的角度提出了前景感知关系网络(FarSeg),以缓解上述两个问题。同时,从优化的角度出发,提出了一种基于前景的优化算法,重点关注前景样本和训练背景中的困难样本,以达到均衡优化的目的。使用大规模数据集获得的实验结果表明,该方法优于最新的常规语义分割方法,并在速度和准确性之间取得了较好的折衷。
地理观测技术提供了大量的高空间分辨率(HSR)遥感图像,可以精细地描述各种地理空间对象,如船舶、车辆和飞机等,从HSR再遥感图像中自动提取感兴趣的对象,对城市管理、规划和监测等领域非常有帮助。地理空间对象分割作为对象提取环节中的重要角色,可以为感兴趣的对象提供语义和位置信息,它属于一种特殊的语义分割任务,目标是将图像像素分为前景对象和背景区域两个子集。而与此同时,它需要进一步为前景对象区域的每个像素分配一个统一的语义标签。
与自然场景相比,HSR 遥感图像中的地理空间对象分割更具挑战性,主要有三个原因:
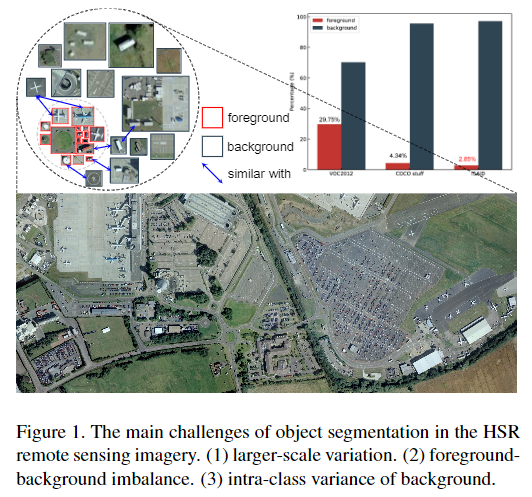
1、在HSR遥感图像中,物体总是有较大尺度的变化,这就造成了多尺度的问题,使得物体难以定位和识别。
2、HSR遥感图像中背景更为复杂,由于类内差异较大,容易造成严重的误报。
3、前景的比例比远小于自然图像中,如图1所示,造成前景-背景不平衡问题。
对于自然图像,目标对象分割任务被直接视为计算机视觉领域中的语义分割任务,其性能主要受到多尺度问题的限制。因此,当前最新的通用语义分割方法集中于scale-aware和multi-scale方面来进行建模。然而,对于遥感图像的分割,在这些常规语义分割方法中忽略了误报和前景与背景不平衡等问题。本文认为这是因为这些方法缺乏针对前景的显式建模。
为了解决上述两个问题,本文提出了一种前景感知关系网络(FarSeg),该前景网络明确地利用前景建模技术在遥感图像中进行更鲁棒的目标分割。同时探索了显式前景建模的两种方法:基于关系和基于优化的前景建模,并且进一步在FarSeg中提出了两个模块:前景场景关系模块(foreground-scene relation module)和前景感知优化(foreground-aware optimization)。前景-场景关系模块学习场景与前景之间的共生关系,以关联与前景相关的上下文以增强前景特征,从而减少误报。前景感知优化通过抑制背景中的多个简单示例,将模型集中于前景,从而减轻前景背景不平衡问题。
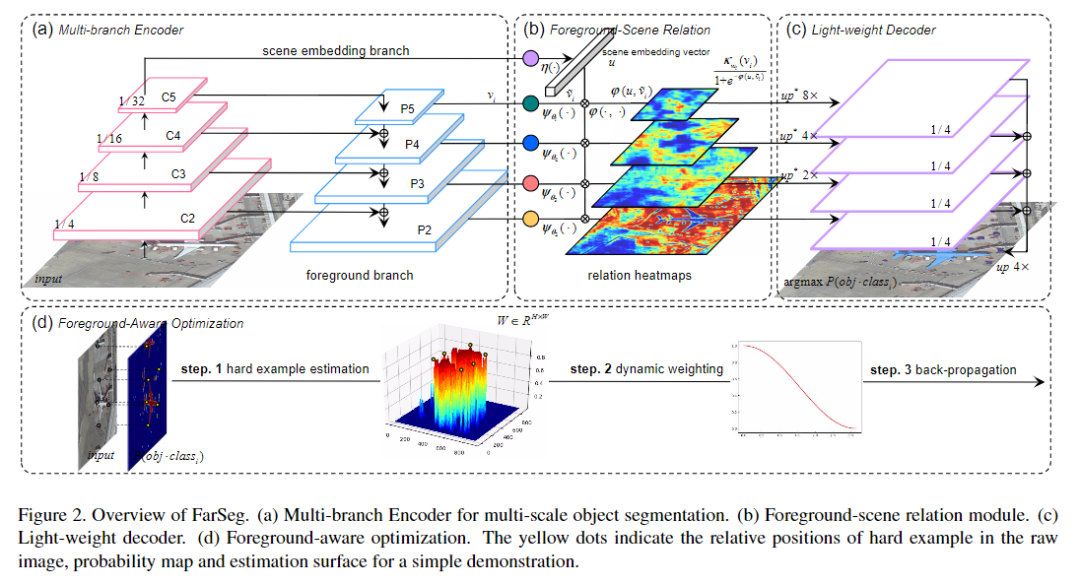
为了对遥感图像中的物体分割前景进行显式建模,本文提出了一种前景感知关系网络(FarSeg),如图2所示。FarSeg由特征金字塔网络(FPN)、前景场景(F-S)关系模块、轻量级解码器和前景感知(F-A)优化组成。FPN负责多尺度对象分割。在F-S关系模块中,首先将误报问题表述为前景中缺乏区分性信息的问题,然后介绍潜在场景语义和F-S关系以改善对前景特征的区分。轻量级解码器仅设计用于恢复语义特征的空间分辨率。为了使网络在训练过程中集中在前景上,提出了F-A优化来减轻前景背景不平衡的问题。
1、 Multi-Branch Encoder
多分支编码器由前景分支和场景嵌入(scene embedding)分支组成。如图2(a)所示,这些分支建立在一个主干网络上。在所提出的方法中,选择ResNets作为主干网络进行基本的特征提取,与原FPN类似,采用自上而下的路径和横向连接的方式,生成金字塔状的特征图。
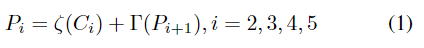
其中ζ表示由可学习的1×1卷积层实现的横向连接,Γ表示比例因子为2的最近邻上采样。通过这种自上而下的路径和横向连接,可以通过浅层的高空间细节和深层的强语义来增强特征图,这有助于恢复对象的详细信息和多尺度上下文建模。除了金字塔形特征图6外,在C5上附加了分支以通过全局上下文聚合生成地理空间场景特征C6。为了简单起见,使用全局平均池作为聚合函数。其中C6用于对地理空间场景与前景之间的关系进行建模。
2、Foreground-Scene Relation Module
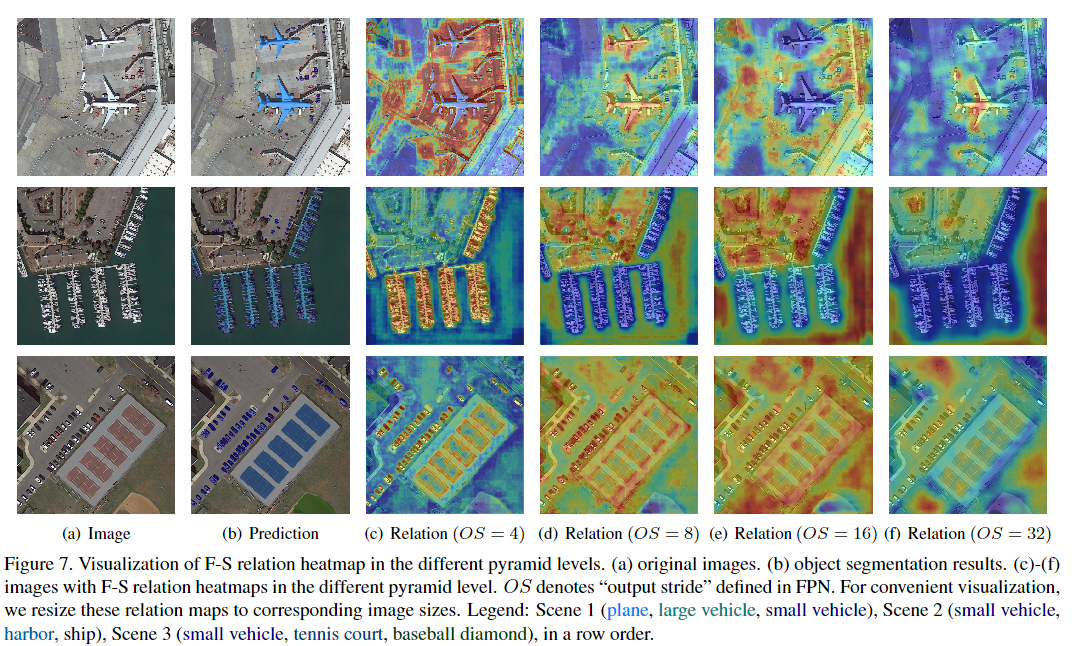
遥感图像中的背景要复杂得多。这意味着背景中存在更大的类内差异,这会引起误报问题。为了减轻这个问题,提出了前景场景(F-S)关系模块,以通过关联与地理空间场景相关的上下文来改善前景特征的辨别力。主要思想如图3所示。
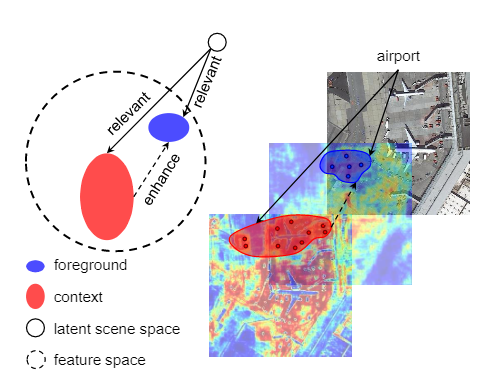
图3. F-S关系的概念。前景要素通过其协作的潜在地理空间场景空间与相关的上下文要素相关联。同时,利用相关的上下文特征来增强对前景特征的区分。
F-S关系模块首先对前景和地理空间场景之间的关系进行显式建模,并使用潜在的地理空间场景将前景和相关上下文关联。然后利用该关系来增强输入特征图,以增加前景特征与背景特征之间的差异,从而改善前景特征的辨别力。
如图2(b)所示,对于金字塔特征图vi,F-S关系模块将生成一个新的特征图zi。特征图zi是通过重新编码vi然后使用关系图ri对其进行加权而获得的。关系图ri是地理空间场景表示和前景表示之间的相似度矩阵。为了将这两个特征表示对齐到共享的manifold R中,分别需要两个投影函数来学习地理空间场景和前景。
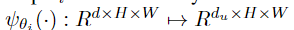
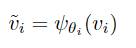
ψθi(·)仅由1×1卷积层,然后依次进行批归一化和ReLU来实现。
为了计算关系图ri,需要一个1-D场景嵌入向量(scene embedding vector)u与共享的前景特征图交互。场景嵌入向量u是通过在C6上应用η(·)来计算的。

其中η表示用于地理空间场景表示的投影函数,并且由具有du输出通道的可学习的1×1卷积层实现。每个潜在金字塔共享场景嵌入向量,因为潜在的地理空间场景语义跨越所有金字塔,并且是尺度不变的。因此,关系图ri可以由下面等式获得。
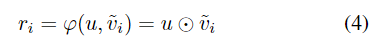
其中φ表示相似的估计函数,并通过逐点内积实现,以简化操作并提高计算效率。
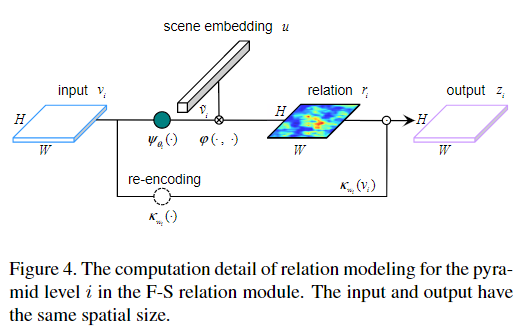
对于每个金字塔层,关系建模的过程细节如图4所示,关系增强前景特征图zi的计算方法如下所示:
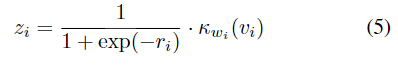
其中κwi(·)是带有输入特征图的学习参数的编码器。编码器被设计为引入一个额外的非线性单元,以避免特征退化,因为加权操作是线性函数。因此,该编码器由1×1卷积层,批处理归一化和ReLU实现,以实现高效的参数和计算。该项目包括等式。公式5表示用于加权重编码特征图,该特征图是使用基于简单sigmoid函数的归一化关系图。
3、 Light-weight decoder
轻量级解码器旨在以轻量级方式从F-S关系模块中恢复关系增强的语义特征图的空间分辨率。轻量级解码器的详细架构如图5所示。
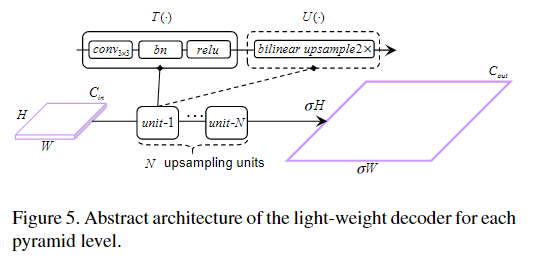
为了汇总每个金字塔的上采样特征图,采用逐点平均运算后跟1×1卷积层进行计算和提高参数效率。然后使用4×双线性上采样来生成与输入图像大小相同的最终类别概率图。
4、Foreground-Aware Optimization
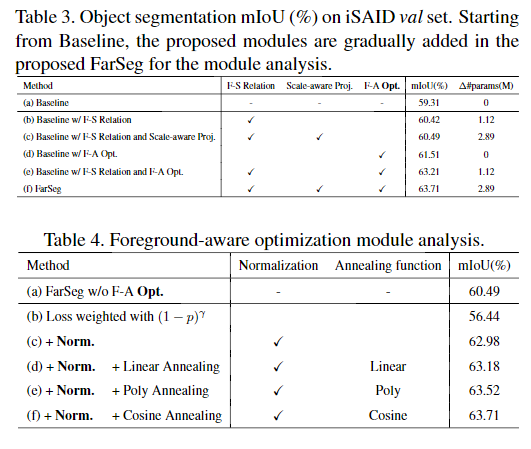
前景与背景之间的不平衡问题通常导致在训练过程中背景示例主导了梯度。但是,只有背景示例的困难部分(分类错误的样本)对于训练后期的优化是有价值的,其中,背景中的困难样本比简单样本要少得多。以此为动力,本文提出了前景感知优化,以使网络集中在前景和背景中的困难样本上,以实现均衡优化。前景感知优化包括三个步骤:困难样本估计,动态加权和反向传播,如图2(d)所示。
hard example estimation
该步骤用于获得反映样本的难易程度的权重,以调整像素方向损失的分布。该样本越难表示其权重越大。在Focal loss的基础上做了改进,引入Z函数保证归一化。
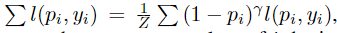
dynamic weighting
困难样本估计依赖于模型的判别。然而,在训练的初期,区别是不确定的,这使得很难对样本进行估计。如果使用此不确定的样本权重,则模型训练将不稳定,从而影响聚合性能。为了解决这个问题,提出了一种基于退火函数的动态加权策略,设计了三种退火函数作为候选函数,如表1所示。给定交叉熵损失l,动态加权损失可表示为:
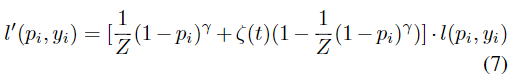

通过这种方式,损失分布的焦点可以随着困难样本估计的置信度的增加而逐步转移到困难样本上。
数据集: iSAID dataset
实验细节:backbone:ResNet-50,输入图像分辨率(896,896), sliding window striding 512 pixels
对比实验
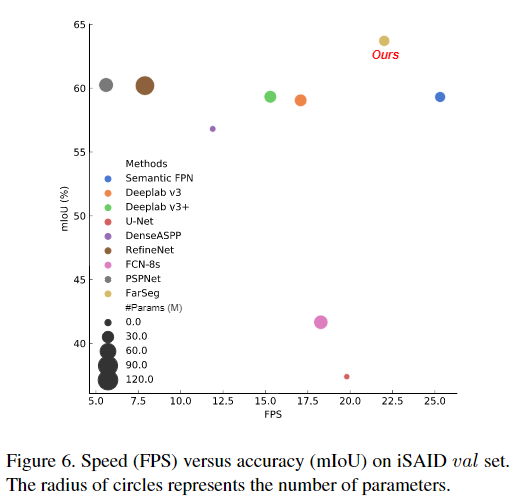
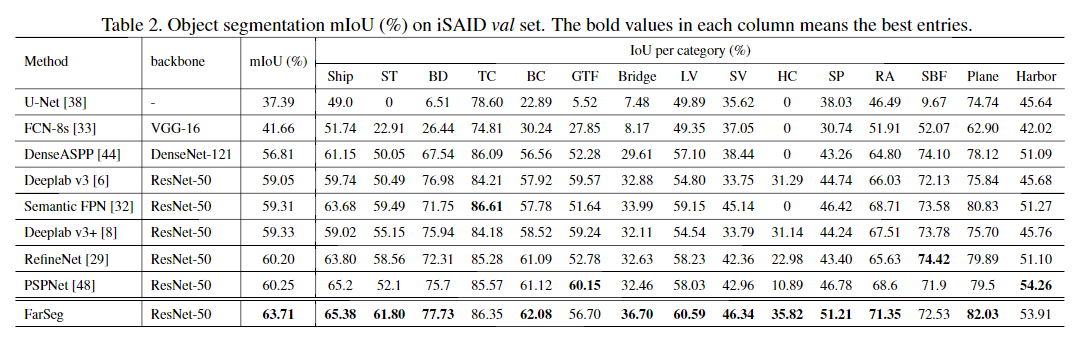
消融实验
可视化实验
更多细节可参考论文原文。

重磅!CVer-图像分割交流群成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,目前已满1500+人,旨在交流语义分割、实例分割、全景分割和医学图像分割等方向。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
点赞和在看!让更多CVer看见




