自监督学习在各种视觉基准上表现出优于监督方法的性能。孪生网络(siamese networks)鼓励嵌入不受扭曲影响,是最成功的自监督视觉表示学习方法之一。在所有的增强方法中,掩蔽是最通用和最直接的方法,它有可能应用于各种输入,并且需要最少的领域知识。然而,掩蔽的孪生网络需要特殊的归纳偏置,并且实际上只能与 Vision Transformers 一起工作。
这项工作实验性地研究了带有 ConvNets 的掩蔽孪生网络背后的问题。作者提出了几种设计来逐步克服这些问题。本文的方法在low-shot图像分类上具有竞争力,并且在目标检测基准上优于以前的方法。
Masked Siamese ConvNets
论文地址:
https://arxiv.org/abs/2206.07700
自监督学习旨在从可扩展的未标记数据中学习有用的表示,而不依赖于人工注释。它已在自然语言处理、语音识别和其他领域取得成功。自监督视觉表示学习也成为一个活跃的研究领域。
孪生网络(siamese network)是许多自监督学习方法中的一种有前途的方法,并且在许多方面都优于有监督的同类网络视觉基准。它鼓励编码器对人为设计的增强保持不变,只捕获基本特征。实际上,孪生网络方法依赖于特定领域的增强,例如裁剪、颜色抖动和高斯模糊,它们不适用于新领域。因此,希望找到一种需要最少领域知识的通用增强方法。
在各种增强中,掩蔽(mask)输入仍然是最简单和最有效的方法之一,已被证明对 NLP和语音有用。然而,直到最近视觉Transformer (ViTs)的成功,视觉模型才能利用掩蔽作为一般增强。当与 ViT 结合使用时,带有掩码的自监督学习已展示出更具可扩展性的特性。不幸的是,带有掩蔽的孪生网络不能很好地与大多数现成的架构一起工作,例如 ConvNets。
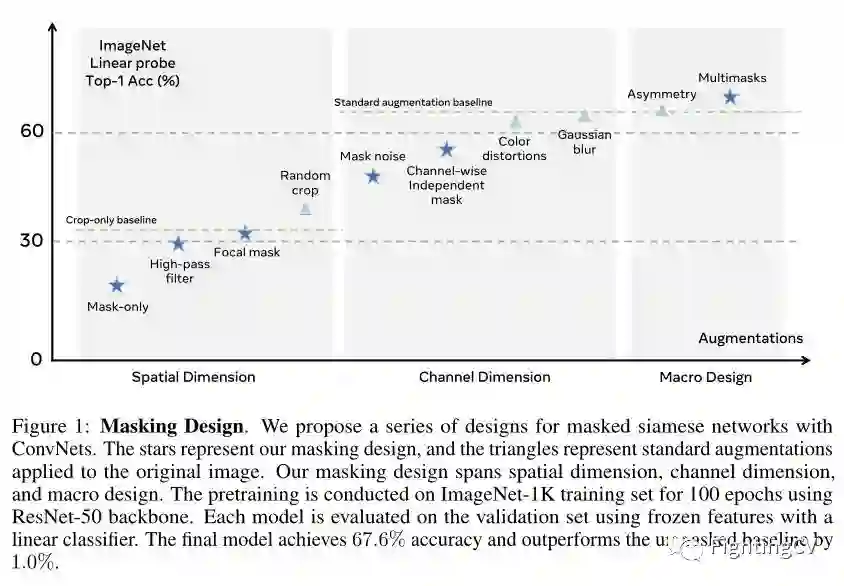
这项工作使用 ConvNets 确定了掩蔽孪生网络背后的潜在问题。作者认为,掩蔽输入会产生寄生边缘,扭曲局部和全局特征之间的平衡,并且训练信号更少。作者提出了几种设计来逐步克服这些问题。如上图所示,实验表明,具有 ConvNets 主干的连体网络可以从这些设计的掩码输入中受益。
1)作者确定了掩蔽孪生网络在 ConvNets 主干上表现不佳的根本问题。
2)作者提出了几种实验设计,并逐渐克服了带有 ConvNets 的掩蔽孪生网络的问题。
3)作者提出了 Masked Siamese ConvNets (MSCN),它在low-shot图像分类基准上具有竞争力,并且在目标检测基准上优于以前的方法。
带有mask输入的孪生网络已经在 ViT上展示了的竞争性能。用现成的 ConvNet替换 ViT 会导致性能明显下降。这里首先确定一些潜在的问题:
卷积核以其边缘检测行为而闻名。应用mask会在图像中产生大量寄生边缘。边缘检测内核生成的特征图被严重扭曲,因此这些核在训练期间被抑制。更重要的是,这些寄生边缘将保留在输出特征图中并影响所有隐藏层。相反,ViT 避开了这个问题,因为mask通常被设计为匹配patch边界。
在上图中,作者可视化了编码器的第一个卷积层核,这些核使用标准增强或掩码输入进行了预训练。由于寄生边缘,许多内核崩溃为琐碎的空白特征。
随机调整大小的裁剪是孪生网络最关键的增强。通过改变裁剪的规模,孪生网络找到了短程和长程相关性的精确组合,称为局部/纹理特征和全局/语义特征。裁剪可以被认为是mask的一种特殊情况,但是随机mask会根据mask网格大小以不同的比率扭曲局部和全局特征。在 ViT 中,mask网格大小是固定的,并设置为与patch大小相匹配。因此,空间掩蔽设计对 ViT 的这种平衡几乎没有影响。然而,具有尺度不变性归纳偏置的卷积网络可能会受益于仔细的空间掩蔽设计。
掩码输入仅包含部分信息,这导致学习信号较少。实际上,掩蔽方法通常需要更长的训练时间或使用multicrops。例如,掩码自动编码器受益于长达 1600 个 epoch 的更长训练。Masked siamese networks通过使用 3 个额外的 multicrops,将 ImageNet-1K 的准确率提高了 20% 以上。这也导致 ConvNets 的计算效率降低,因为它们不能跳过像 ViTs 这样的未屏蔽区域。
在本节中,作者提出了几种实验设计来克服上一节中讨论的问题,并展示了最终掩蔽策略的轨迹。作者使用带有 ResNet-50 骨干网的 SimCLR 作为baseline。对于本节的实验,作者使用 LARS 优化器在 ImageNet-1K训练集上对每个模型进行 100 个 epoch 的预训练,batch大小为 4096。所有结果都是 ImageNet-1K 验证集上的linear probe精度。
此外, 传统模式识别在图像分类或对象检测方面具有手工特征的次优性能表明, 这些任务的有 用特征不具有数学或概念上的简单性。因此, 当设计增强时, 作者正在寻找数学或概念上的简 单特征, 并提出增强以防止网络收敛到这些特征。
标准增强可防止基于简单输入统计的表面特征。但是,使用掩蔽输入,表面特征可能会利用掩蔽区域并超过有用的区域。将掩码表示为,将掩码区域的填充值表示为。这个掩蔽图像可以写成 。因此,得出了本文的掩蔽设计原则。对于一个useful特征 和一个 trivial特征,作者要求和满足:
作者首先关注空间维度来研究如何在孪生网络中最好地利用掩蔽。首先在同一个随机裁剪上应用两个随机网格掩码(网格大小 32),掩蔽率固定为 30%,没有其他增强。为了克服由任意网格掩码边界引入的寄生边缘问题,作者在应用掩码之前应用高通滤波器。如上图所示,使用高通滤波器,寄生边缘变得不可见。此外,输入图像中的特殊值 0 表示空信息,而不是正常的像素值。使用高通滤波器,模型精度提高到 30.2%。平衡输入中的短程和长程特征以学习有用的表示是至关重要的。
除了随机网格掩码(grid mask)外,作者还应用了焦点掩码(focal mask)。如上图所示,焦点蒙版可以看作是随机裁剪,无需调整大小。作者应用 20% 的焦点掩码和 80% 的网格掩码。作者随机组合了随机网格掩码和焦点掩码样本。这将模型精度提高到31.0%。最后,作者将空间掩蔽设计与标准随机调整大小裁剪相结合。允许两个分支使用不同的裁剪视图。这种组合方法达到了 40.0% 的准确率。注意,在没有mask的情况下,使用仅裁剪增强的模型只能获得 33.5% 的准确率。
然后作者关注在通道维度上设计掩码。首先,作者发现向mask区域添加噪声是有益的。如上图所示,这可以防止网络利用整体颜色直方图,并且等效于在mask区域上应用颜色抖动。向mask区域添加噪声可将准确度从 40.0% 提高到 48.2% 接下来,作者随机应用一个通道独立的掩码。除了标准的空间mask,作者在三个颜色通道上应用相同的mask,作者生成三个随机mask并将它们分别应用于每个颜色通道。作者发现以 70% 的概率应用通道独立掩码是最佳的。如上图所示,这将准确度提高到 53.6%。最后,作者将通道mask设计与标准增强相结合。通过在应用蒙版之前对两个分支应用颜色抖动和灰度,该模型达到了 63.0% 的准确率。接下来,在两个分支上随机应用高斯模糊将准确率提高到 65.1%。
作者发现增加两个网络之间的不对称性可以提高准确性。通过改变两个分支之间的概率,模型精度提高到 65.6%。掩蔽孪生网络在每次迭代中接收的信息较少。作者生成多个mask输入并在不对称对上应用联合嵌入损失。这种多mask设计将准确度提高到 67.4%。最终设计比不应用mask好 1.0%,比使用标准增强加上随机mask好 5.2%。
按照本文的设计原则,作者逐步改进了掩蔽策略。将整体设计总结如下:
应用标准增强:RandomResizedCrop、HorizontalFlip、ColorJitter、Grayscale、GaussianBlur;
应用mask(空间维度:焦点掩码和随机网格掩码 通道维度:通道独立掩码和空间掩码),并将随机噪声添加到mask区域;
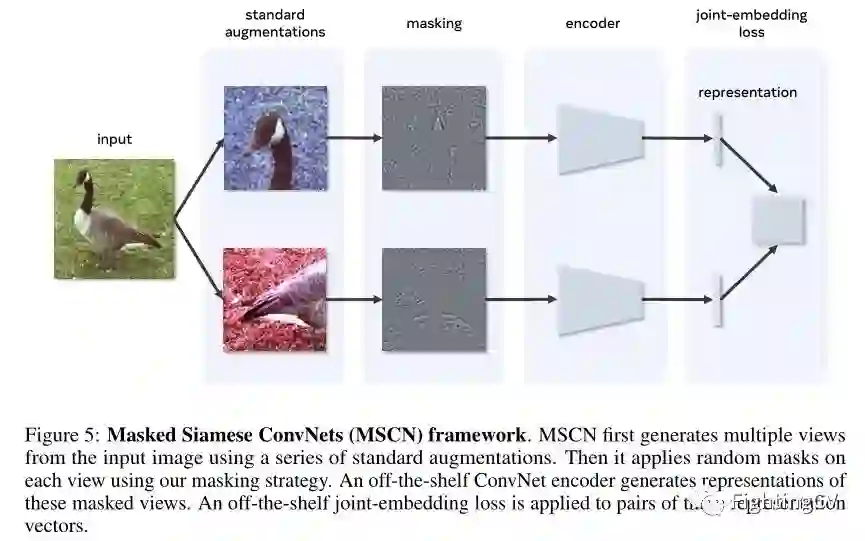
整体 Masked Siamese ConvNets (MSCN) 架构如上图所示。MSCN 利用任意骨干架构和各种联合嵌入损失函数。
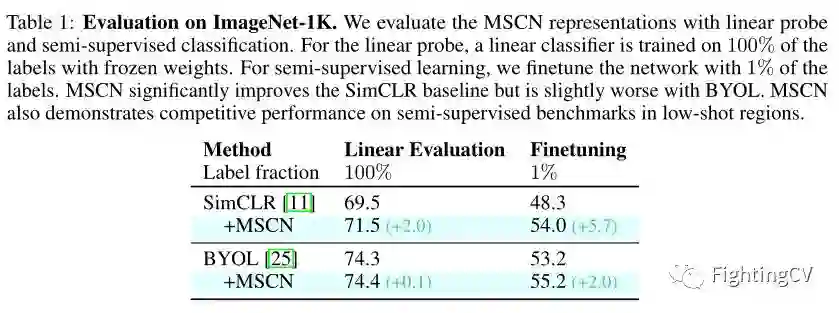
作者首先使用linear probe和半监督分类评估 ImageNet-1K 数据集上的表示。在上表中,作者将 MSCN 与baseline进行比较,可以看出,本文方法相比于其他方法有明显的提升。
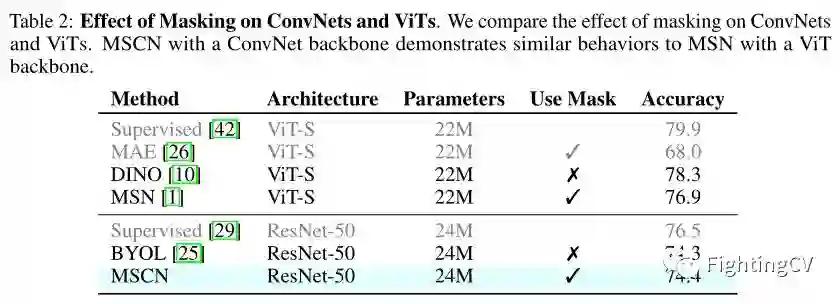
作者在上表中比较了mask对 ConvNet 和 ViT 的影响。具有 ConvNet 主干的 MSCN 与具有 ViT 主干的 MSN 表现出相似的表现。
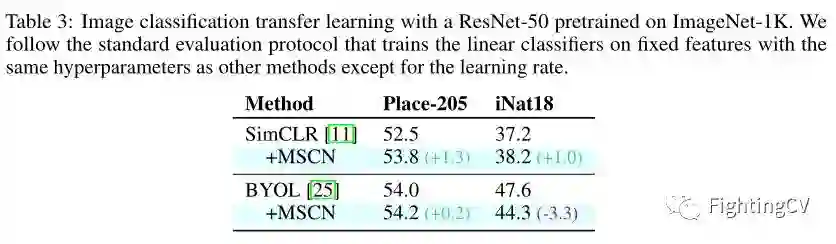
作者在上表中报告了 iNaturalist 2018数据集和 Places-205数据集上的迁移图像分类结果。
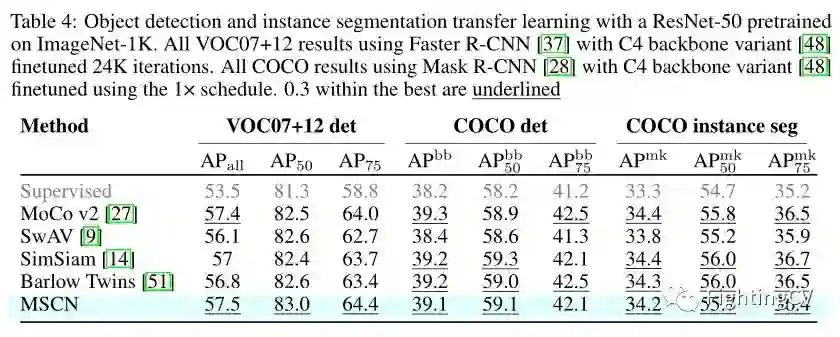
在表中,作者报告了 VOC07+12 和 COCO 数据集上的目标检测和实例分割性能。
在上表中,作者探索了最佳掩蔽率。0.15 的小掩蔽率对于 ResNet-50 主干网络是最佳的。作者还观察到,使用本文的掩蔽策略,对于高达 0.50 的掩蔽率,精度相对稳定。
在上表中,作者展示了学习表示可以从更好的掩码网格大小中受益。
在本文的mask策略中,作者应用标准增强来生成多个视图,然后在这些视图上随机应用mask。一种替代方法是在同一增强视图上应用随机掩码。上表显示,在同一视图上应用掩码会导致显着更差的表示。
这项工作提出了一种使用 ConvNets 向孪生网络添加掩蔽增强的方法。作者首先介绍使用掩蔽作为增强引入的问题。然后仔细研究如何通过改变掩蔽策略来逐步提高下游任务的性能以解决或缓解问题。本文的方法在low-shot图像分类基准上具有竞争力,并且在目标检测基准上优于以前的方法。
公众号后台回复“ 项目实践 ”获取50+CV项目实践机会~
极市平台深耕CV开发者领域近5年,拥有一大批优质CV开发者受众,覆盖微信、知乎、B站、微博等多个渠道。通过极市平台,您的文章的观点和看法能分享至更多CV开发者,既能体现文章的价值,又能让文章在视觉圈内得到更大程度上的推广。
对于优质内容开发者,极市可推荐至国内优秀出版社合作出书,同时为开发者引荐行业大牛,组织个人分享交流会,推荐名企就业机会,打造个人品牌 IP。
2.
极市平台尊重原作者署名权,并支付相应稿费。文章发布后,版权仍属于原作者。
3.原作者可以将文章发在其他平台的个人账号,但需要在文章顶部标明首发于极市平台
添加小编微信Fengcall(微信号:fengcall19),备注:姓名-投稿