

摘要—— 科学大语言模型(Scientific Large Language Models, Sci-LLMs)正在重塑知识在科学研究中的表征、集成与应用方式,然而它们的发展轨迹也受到科学数据复杂性的深刻影响。本综述提出了一种全面的、以数据为中心的综合视角,将 Sci-LLMs 的发展重新框定为模型与其底层数据基质之间的协同进化。我们构建了一个统一的科学数据分类法和科学知识的层次化模型,强调科学语料在多模态、跨尺度以及领域特异性方面所面临的独特挑战,这些特征使其显著区别于通用自然语言处理数据集。我们系统性回顾了近期的 Sci-LLMs,从通用基础模型到各科学科的专用模型,并对 270 余个预训练/后训练数据集进行了深入分析,揭示了 Sci-LLMs 的独特需求——异构的、跨尺度的、充满不确定性的语料,要求具备保持领域不变性和支持跨模态推理的表征方式。在评测方面,我们考察了超过 190 个基准数据集,并追踪了评测范式从静态考试逐步转向过程导向与发现导向的评估协议。基于这些以数据为中心的分析,我们指出科学数据开发中仍然存在的长期问题,并探讨了包括半自动化标注流程与专家验证在内的新兴解决方案。最后,我们展望了一种范式转变,即迈向闭环系统:由 Sci-LLMs 驱动的自主智能体能够主动进行实验、验证,并贡献于一个动态演化的知识库。总体而言,本工作为构建可信赖、可持续进化、并能作为真正科研伙伴的人工智能(AI)系统提供了清晰的路线图,加速科学发现进程。
关键词—— 大语言模型;AI for Science;科学数据;Data4LLM
I. 引言
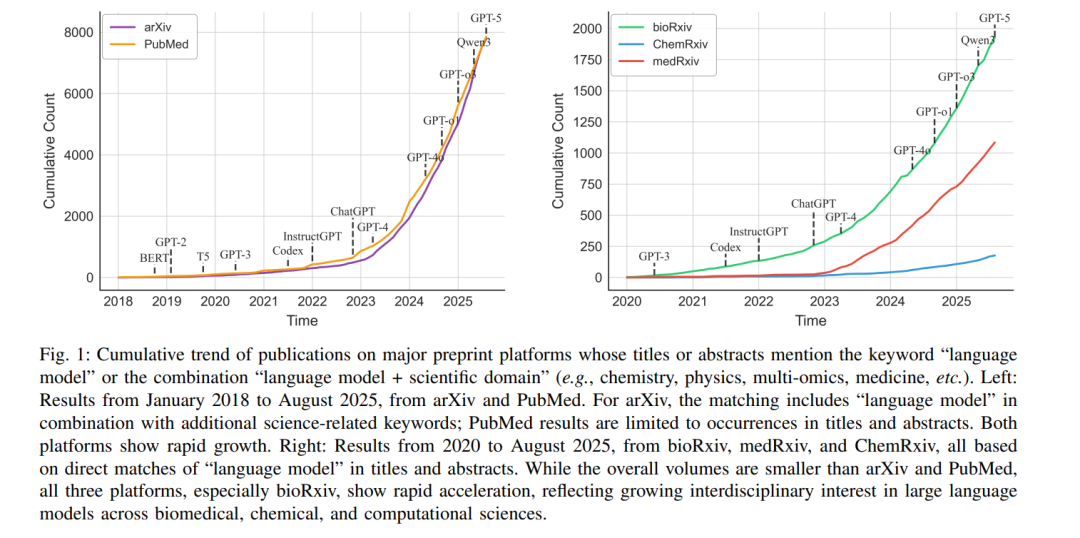
“科学是由事实构建的,正如房子是由石头砌成的。但事实的堆积并不等同于科学,正如石头的堆积并不等于房子。” ——昂利·庞加莱 大语言模型(Large Language Models, LLMs)的快速发展,引发了跨越多个领域的范式转变,通过任务自动化、生产力提升和突破性创新,展现出前所未有的变革潜力 [1]–[5](见图 1)。这些模型从根本上改变了科学研究方式,引入了一种统一的方法论,取代了传统的任务特定方法,并扩展到自然语言处理之外,涵盖分子 [6]、蛋白质 [7]、表格 [8] 以及复杂元数据等多种科学数据类型。LLMs 已经彻底革新了诸如软件工程 [2], [9], [10]、法律 [11], [12]、材料科学 [13], [14]、医疗健康 [15]–[17] 以及生物医学研究 [18] 等领域,并在数学 [19]、物理、化学 [20]、生物学 [21] 和地球科学 [22] 等学科中得到了广泛应用。
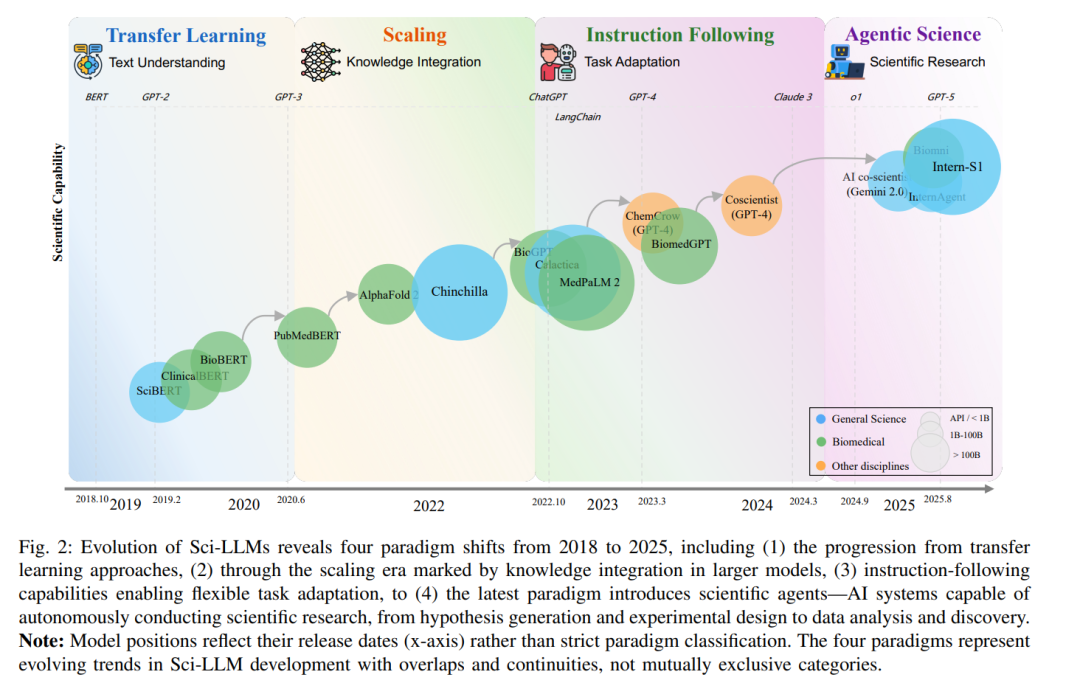
科学大语言模型(Scientific Large Language Models, Sci-LLMs)的演进,从 2018 年至 2025 年,经历了四个以数据驱动的显著阶段(见图 2)。 * 迁移学习阶段(2018–2020):这一阶段主要基于 BERT [23] 架构进行领域适配,代表性模型如 SciBERT [24]、BioBERT [25] 和 PubMedBERT [26],在大规模科学语料上继续预训练,显著提升了下游科学文本理解任务的表现。这类模型为特定任务提供了可靠但静态的概念表征,但在大规模综合与生成新的科学内容方面表现不足。 * 规模化阶段(2020–2022):参数与语料规模扩张成为核心驱动力。GPT-3 [27] 拥有 1750 亿参数,结合后续的数据/算力最优训练规则 [28], [29],展示了大规模参数扩展与多样化训练数据带来的新兴知识整合能力,从根本上改变了科学 AI 的格局。Galactica [30] 将这一经验拓展到科学领域,基于 1200 亿参数、超过 4800 万篇科学论文、教材和百科训练,设计了适配数学公式、化学结构和引用的专门分词方案。MedPaLM-2 [31] 进一步在多医学领域数据集上进行指令调优,在 USMLE 风格问题上取得超过 85% 的准确率,首次展现了可与执业医生相媲美的专家级医学推理能力。然而,Sci-LLMs 在这一阶段遭遇了“数据壁垒”:不同于通用领域可获得数千亿至数万亿规模的网络语料,高质量科学文本语料数量远小几个数量级,而丰富的原始科学数据在早期大规模尝试中却未得到充分利用。 * 指令跟随阶段(2022–2024):研究重心由模型容量转向对齐,任务适配主要通过人类反馈强化学习(RLHF)实现。典型代表包括 InstructGPT [32] 和 ChatGPT [33],使得科学任务执行更为精确。开源 LLM 架构(如 LLaMA [34]、Qwen [35]、ChatGLM [36] 和 Mistral [37])的兴起,推动了科学应用的多样性。同时,指令数据集的快速扩展催生了一系列里程碑式的 Sci-LLMs。例如,生物医学领域的 Meditron [38] 在 481 亿医学语料上预训练,展示了开源模型在医学推理中的潜力;ProteinChat [39] 基于 150 万蛋白质问答样例训练,助力蛋白质研究;LLaMA-Gene [40] 融合 DNA、蛋白质与文本数据,以及 5 亿条 DNA/蛋白任务指令样例,支持跨模态生物序列理解;跨学科模型 SciGLM [41] 在 25.4 万条精心构建的指令样例上微调,展现了跨学科知识整合能力。大量研究表明,数据规模与模型性能高度相关,例如 HuatuoGPT-II [42] 在 11 TB 医学语料上预训练,NatureLM [43] 在 1430 亿词元上预训练并结合 4510 万条指令响应对进行调优。这种“架构多样性 + 数据扩展”的双轮驱动范式,成为当前 Sci-LLM 发展的核心框架。 * 科学智能体阶段(2023–至今):AI 系统逐步具备“科学能动性”,能够规划、行动并在发现过程中迭代。已有大量工作展示了端到端的科学工作流 [44], [49],并越来越多地聚焦于多智能体 [50], [51] 与工具生态系统 [18], [52]。多智能体设计模拟实验室层级(从首席科学家到领域专家),通过正式化的会议协议与批评–迭代循环实现协作 [53], [54],从而在科学团队合作与科学规律约束下生成更具新颖性与可行性的研究构想 [55], [56]。更大规模的协作框架可管理完整的研究生命周期(问题定义、论文撰写等),并保存持久的研究产物与审计记录 [57];其具身化变体则整合机器人执行与自适应规划 [58]。与此同时,工具集成的进展主要集中在知识图谱驱动的编排 [59] 以及与数百种软件工具、数据库和实验仪器的领域级智能体交互,并配备可溯源机制 [18]。
然而,Sci-LLMs 面临的根本挑战来自科学数据与知识表征的独特特征。与通用 LLM 发展中相对同质的文本语料不同,科学数据集呈现出跨模态与跨格式的极端异质性。例如,仅在化学领域,模型就需要处理分子字符串、三维分子坐标、光谱数据与反应机理,这些均需要不同的处理策略 [60];在生命科学中,模型必须同时处理基因组序列、蛋白质结构、多组学数据与临床影像 [61]–[63];在天文学中,则需要整合跨越巨大时空尺度的光变曲线、光谱观测和多波段成像 [64], [65]。 此外,科学知识本身具有层次化特征,从原始观测数据到抽象理论框架,每一层都有其独特的表征需求 [66], [67]。科学数据往往包含难以直接通过分词或嵌入处理的领域语义:数学公式具有必须保留的精确符号关系 [68], [69];晶体学信息文件则编码了材料科学中至关重要的三维结构约束 [70], [71];如 LIGO 等仪器的时间序列数据中,包含淹没在噪声中的微弱信号,需要专门的预处理以确保物理可解释性 [65], [72]。这些多样化数据类型无法通过传统文本方法充分表征,亟需能够保持领域不变性并支持跨模态推理的新型架构 [73]–[75]。 这种异质性与多尺度特性带来了额外的计算与方法学挑战:从量子力学计算到宏观现象的跨尺度建模,要求模型能够捕捉多分辨率依赖关系 [76];实验测量的不确定性还要求模型能够传播误差边界,并在推理过程中保持科学严谨性 [77]–[79]。这些约束使得科学 AI 与通用语言建模存在根本性差异,必须发展尊重科学认知论基础的专门化解决方案。 这种复杂性自然延伸到 Sci-LLMs 的评测问题。传统的 NLP 基准无法有效衡量领域特定能力。近年来,出现了诸如 ScienceQA [80] 和 MMLU-Pro [81] 等评测套件,分别覆盖从小学到研究生的多模态科学理解,以及量子物理、分子生物学等专业领域的严格评估。然而,它们往往无法反映科学发现的细微需求,例如提出新假设、发现跨领域的非显性联系、或设计实验以验证理论预测。为此,Liu 等人提出了 ResearchBench [82],覆盖 12 个学科的大规模科学发现基准,用于系统性评估 LLM 的假设生成能力。同时,研究者们也开始开发面向过程的评测方法,考察中间推理步骤而不仅是最终答案,例如 ScienceAgentBench [83] 可在文献综述、实验设计和结果解读等复杂科学工作流中进行评估。MultiAgentBench [84] 与 WorkflowBench [85] 进一步量化了模型在协作、协调与工作流合成方面的能力,标志着科学自动化逐步走向可度量、安全感知与可复现。学界也认识到,科学有效性不仅仅依赖于语言流畅性,模型必须遵循物理定律、化学价态规则和生物学可行性 [21], [86], [87]。因此,符号推理模块与约束满足系统开始作为护栏集成到生成过程中,确保输出保持在科学可行的范围内,同时允许在知识前沿进行创造性探索。 在此背景下,已有一些综述研究聚焦于特定方面:如生物医学数据建模 [88], [89];Zhang 等人 [21] 从生物与化学领域出发探讨了 Sci-LLMs;部分工作 [60] 研究了其在科学发现中的应用;Wei 等 [90] 与 Wang 等 [91] 回顾了科学智能体范式与自主科研系统设计;Ni 等 [92] 总结了不同学科下的 LLM 基准。然而,这些综述大多以主题为中心,且往往仅对底层科学数据(预训练、后训练、评测阶段)进行有限触及。 与之互补,我们的综述贡献在于提供一个统一的跨学科综合视角,将数据基础与智能体前沿显式关联起来。主要贡献如下: * 提出统一的科学数据分类法与科学知识层次化模型,为分析科学信息表征的挑战提供新的认识论框架,涵盖从原始观测数据、符号表达到抽象理论洞见的多层次。 * 系统梳理快速发展的 Sci-LLMs 研究版图,覆盖物理、化学、生命科学、地球科学、天文学与材料科学六大领域(见图 3)。 * 系统分析 270 余个预训练与后训练数据集,全面揭示支撑 Sci-LLMs 发展的科学数据现状,提炼出多模态、跨尺度、领域特异性等核心挑战。 * 回顾超过 190 个评测数据集,总结评测从静态考试向科研级科学发现转变的趋势,分析领域特定指标的日益结合与先进评估方法的涌现。 * 识别科学数据管理中的结构性缺陷,并提出面向未来的数据发展议程,倡导构建自主科学发现与科学数据基础设施之间的闭环反馈。
综上,本综述建立了一个统一的参考框架,并为构建可信赖、可持续演化的 Sci-LLMs 指明了清晰路线图,助力加速数据驱动的科学发现。




