
IEEE国际计算机视觉与模式识别会议(CVPR),是计算机视觉领域三大顶级会议之一。CVPR 2025将于6月11日至15日在美国田纳西州纳什维尔举办。我们将分期对自动化所的录用研究成果进行简要介绍(排序不分先后),欢迎大家共同交流讨论。
**01. **视频配乐的自定义条件可控生成
Customized Condition Controllable Generation for Video Soundtrack **作者:**亓帆,马锟生,徐常胜 近年来,潜在扩散模型(LDMs)的发展推动了音乐生成领域的创新,使视频配乐在灵活性和多模态融合方面取得了显著突破。然而,现有方法大多采用两阶段流程,难以全面捕捉视频的声音特征,尤其在复杂视频场景下,难以同时呈现准确的音效细节和丰富的音乐情感氛围。为解决上述挑战,我们提出了一种创新性的视频配乐生成框架(C3GVS),能够同步生成与参考视频相匹配的音乐和音效。为此,我们设计了一种基于扩散模型的频谱分歧掩蔽注意力(Spectrum Divergence Masked Attention),该模块利用音乐和音效在时频域中的不同特性,高效融合音乐和音效条件特征,从而实现动态的音画对齐。在此基础上,我们引入了基于评分的引导机制,以增强生成音频的创造性。该方法使音乐创作者能够自定义艺术输入,生成更加个性化的音景,同时确保音频与视频语境保持高度一致。在FilmScoreDB和SymMV&HIMV数据集上的广泛评估表明,我们的方法在主观和客观评测中均显著优于当前最先进的基线方法,展现出其作为视频配乐生成强大工具的潜力。
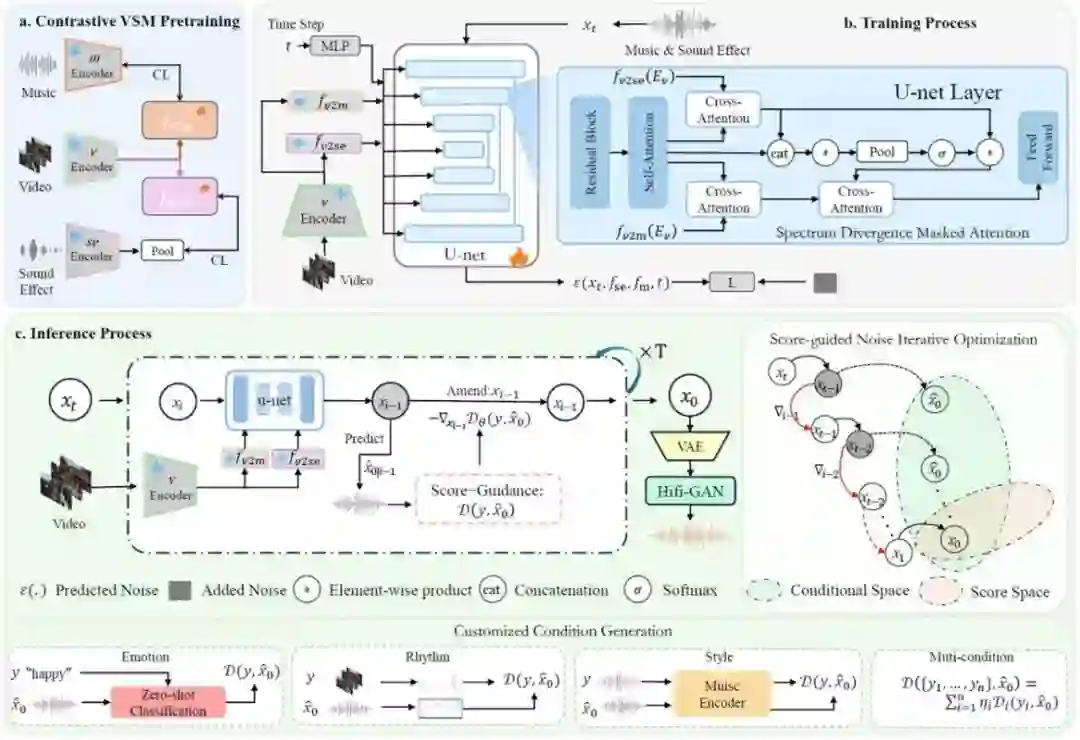
C3GVS框架整体示意图
**02. **基于语言引导的概念瓶颈模型的可解释持续学习
Language Guided Concept Bottleneck Models for Interpretable Continual Learning **作者:**余璐,韩昊宇,陶哲,姚涵涛,徐常胜 持续学习(Continual Learning)的目标是使学习系统能够不断获取新知识,同时不遗忘先前学习的信息。持续面临的挑战在于缓解灾难性遗忘(catastrophic forgetting)的同时保持跨任务的可解释性。现有的大多数持续方法主要侧重于保留已学知识以提高模型性能。然而,随着新信息的引入,学习过程的可解释性对于理解不断演化的决策机制至关重要,但这一方向却鲜少被探索。本研究提出了一种新颖框架,通过整合语言引导的概念瓶颈模型(Concept Bottleneck Models, CBMs)来同时应对这两大挑战。我们的方法利用概念瓶颈层(Concept Bottleneck Layer),与CLIP模型对齐语义一致性,从而学习人类可理解、且能跨任务泛化的概念。通过聚焦于可解释的概念,该方法不仅增强了模型随时间推移保留知识的能力,还提供了透明的决策依据。我们在多个数据集上验证了方法的有效性,其中在ImageNet子集上的最终平均准确率超越现有最优方法达3.06%。此外,我们通过概念可视化展示模型预测依据,进一步推动了可解释持续学习的理解。
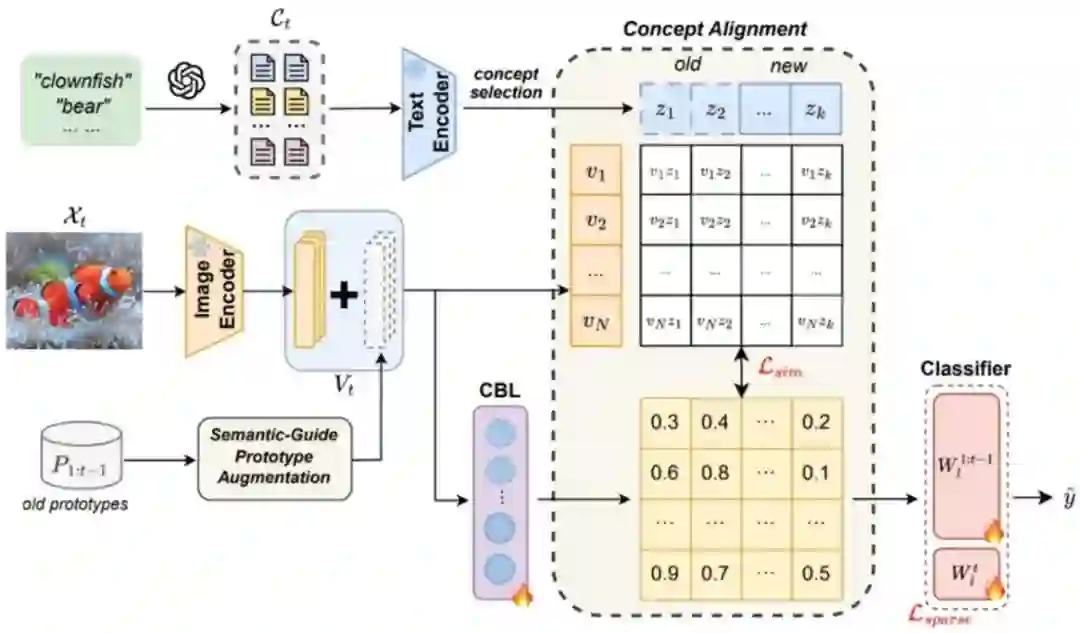
第t个任务时方法框架图
**03. **MV-MATH:多视觉场景下的多模态数学推理能力评估
MV-MATH: Evaluating Multimodal Math Reasoning in Multi-Visual Contexts **作者:**王培杰,李忠志,殷飞,冉德康,刘成林 多模态大语言模型(MLLM)已在各种数学任务中表现出良好的推理能力。然而,大多数现有的多模态数学基准仅限于单视觉环境,这与现实世界数学应用中常见的多视觉场景不同。为了解决这一差距,研究团队推出了 MV-MATH:一个精心策划的数据集,包含 2009 个高质量数学问题。每个问题都集成了多幅与文本交错的图像,这些问题源自真实的 K-12 教育场景并附有详细的注释。MV-MATH 包括多项选择题、自由形式题和多步骤题,涵盖 3 个难度级别的 11 个主题领域,是评估 MLLM 在多视觉环境下数学推理的全面而严格的基准。通过大量实验,我们观察到 MLLM 在多视觉数学任务中遇到了巨大的挑战,与人类在 MV-MATH 上的能力相比,其性能存在相当大的差距。此外,我们还分析了不同模型的表现和错误模式,为多视觉场景下大语言模型的数学推理能力提供了深入见解。
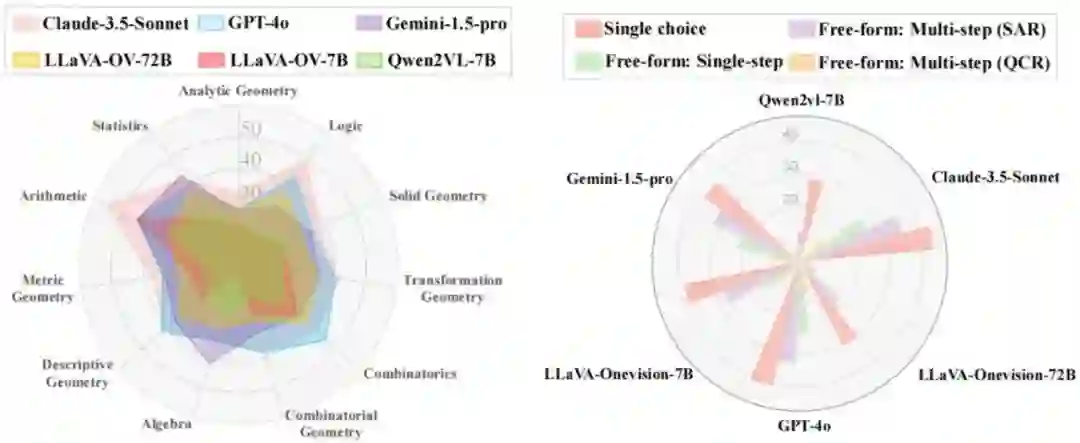
图1. 在 MV-MATH 数据集上,六个多模态大模型的性能比较,涵盖 11 个主题(左)和 3 个问题类型(右)。SAR:步骤准确率,QCR:问题完整率。

图2. MV-MATH的样本示例(上)与数据集特性统计(下),每个样本都包含了多个视觉输入
**04. **DocSAM:基于查询解耦和异质混合学习的通用文档图像分割方法
DocSAM: Unified Document Image Segmentation via Query Decomposition and Heterogeneous Mixed Learning **作者:**李晓辉,殷飞,刘成林 文档图像分割在文档分析和识别中至关重要,但由于文档格式的异质性和分割任务的多样性,这一过程仍然充满挑战。现有方法通常单独处理这些任务,导致泛化能力有限且资源浪费。本文提出一种基于Transformer的统一框架DocSAM,将文档分割建模成实例分割和语义分割的组合,用于多种文档图像分割任务,包括文档布局分析、多粒度文本分割和表格结构识别等。具体而言,DocSAM使用文本编码器将每个数据集中的类别名称描述映射到与实例查询相同维度的语义查询,这些语义查询不仅作为分割提示,指导模型识别需要分割的具体区域类型,还充当类别原型辅助实例查询进行开放集分类。这两组查询通过注意力机制相互作用,并与多尺度图像特征进行交叉注意解码并预测实例和语义分割掩码。基于上述设计,DocSAM可以在异构数据集上联合训练,增强了鲁棒性和泛化能力,同时减少了计算和存储资源的需求。综合评估表明,DocSAM在准确性、效率和适应性方面均优于现有方法,突显了其在推进文档图像分割在各种应用中的潜力。
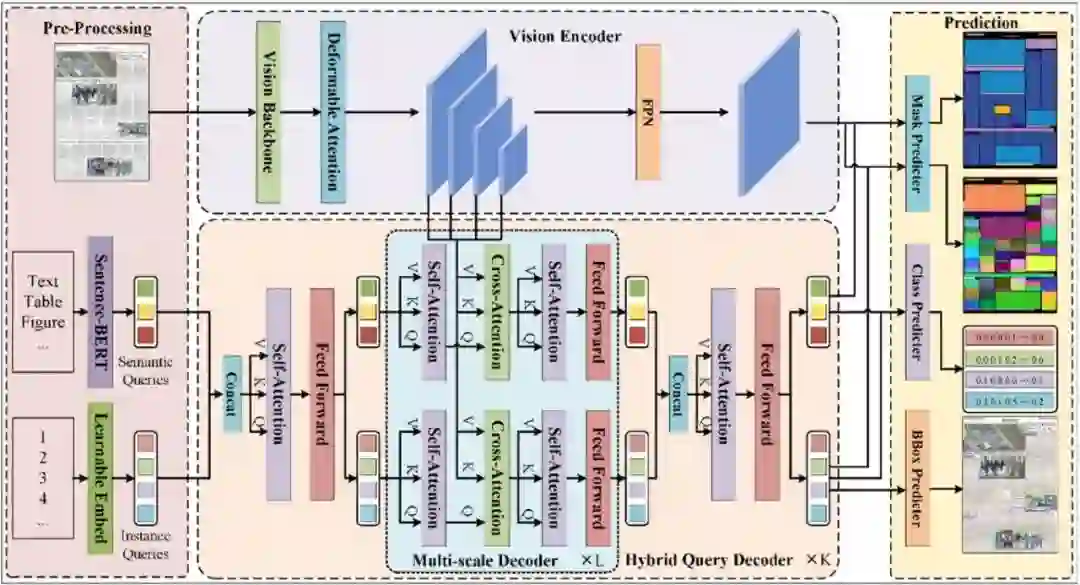
DocSAM模型框架图。DocSAM主要由视觉主干网络、可变形注意力模块、Sentence-BERT和混合查询解码器组成。对于带有自然文本格式类名的文档图像,首先通过视觉主干提取多尺度图像特征并利用可变形注意力模块进行增强,之后将类别名称输入Sentence-BERT转换为语义查询,并与随机初始化的实例查询一同进入混合查询解码器对图像特征进行解码,二者协作完成语义和实例分割任务。
**05. **视觉引导的一体化图像修复扩散模型
Visual-Instructed Degradation Diffusion for All-in-One Image Restoration **作者:**罗文阳,覃海纳,王立彬,陈泽文,刘雨帆,李宇明,郑丹丹,李兵,胡卫明 去模糊、去噪和去光晕等图像复原任务通常需要为每种退化类型分别建立模型,这限制了它们在现实世界中可能出现混合退化或未知退化的场景中的通用性。在这项工作中,我们提出了一种利用视觉指令引导退化扩散的新型一体化图像修复框架 Defusion。与依赖于特定任务模型或含糊的基于文本的先验的现有方法不同,Defusion 构建了与视觉退化模式相一致的明确的视觉指令。这些指令的基础是对标准化的视觉元素进行降级,从而捕捉内在的降级特征,同时与图像语义无关。然后,Defusion 使用这些视觉指令来指导基于扩散的模型,该模型直接在降解空间中运行,通过对降解效果去噪来重建高质量的图像,同时增强稳定性和通用性。综合实验证明,Defusion 在各种图像复原任务(包括复杂的真实世界退化)中的表现优于最先进的方法。
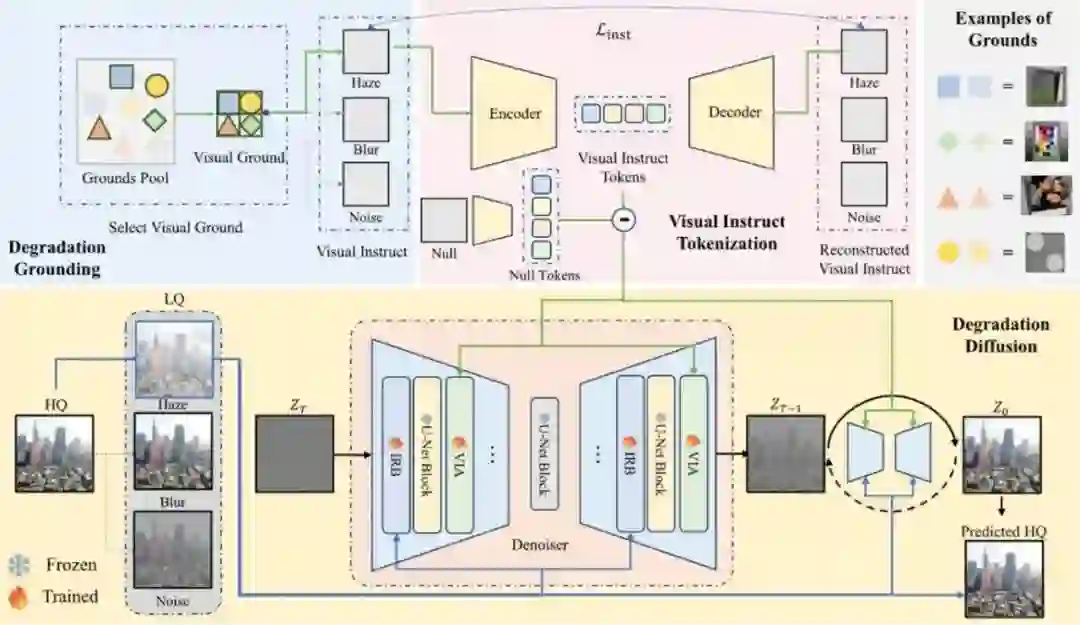
所提出方法的框架。1)从视觉理由中构建视觉指令,以展示图像退化的视觉效果;2)对视觉指令进行标记化,并与 "干净" 视觉元素进行对比;3)最后,视觉指令标记引导去噪扩散模型,该模型根据视觉指令的提示估计退化程度。视觉指令标记符是由损失训练的量化自动编码器,而只有编码器用于推理。
**06. **可逆归一化流图像复原
Reversing Flow for Image Restoration **作者:**覃海纳,罗文阳,王立彬,郑丹丹,陈景东,杨铭,李兵,胡卫明 图像复原的目的是通过逆转退化的影响,从低质量(LQ)的退化图像中恢复出高质量(HQ)的图像。现有的图像复原生成模型,包括扩散模型和基于分数的模型,通常将退化过程视为随机变换,从而带来了低效率和复杂性。在这项工作中,我们提出了一种新颖的图像修复框架 ResFlow,它将降解过程建模为使用连续归一化流的确定性路径。ResFlow 通过辅助过程来增强降解过程,从而消除 HQ 预测中的不确定性,实现降解过程的可逆建模。ResFlow 采用熵保存流路径,并通过匹配速度场来学习增强降解流。ResFlow 显著提高了图像复原的性能和速度,只需不到四个采样步骤即可完成任务。广泛的实验证明,ResFlow 在各种图像复原基准测试中都取得了最先进的结果,为实际应用提供了实用高效的解决方案。我们的代码将公开发布。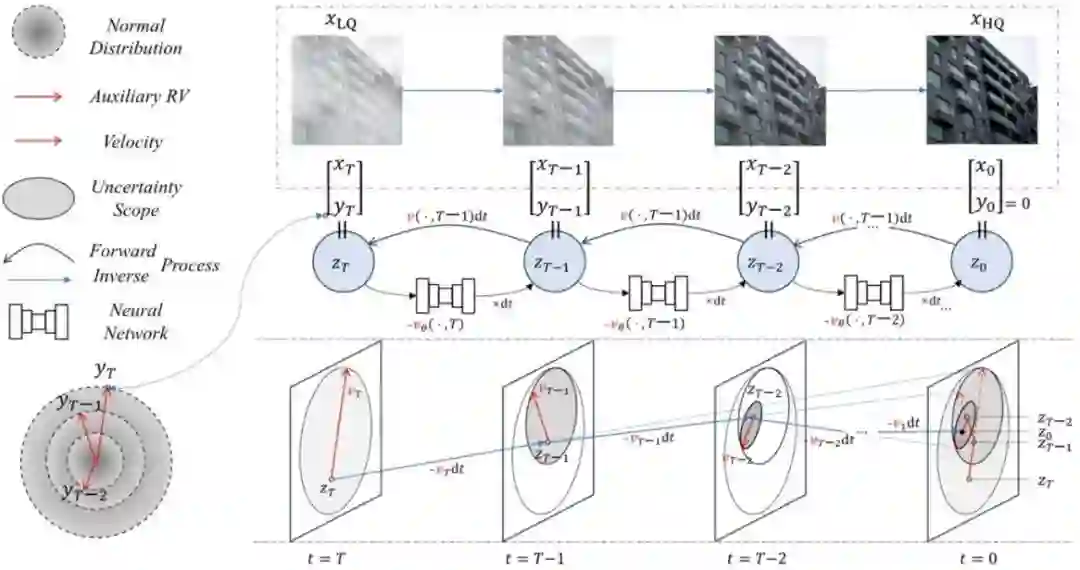

**07. **基于最优传输的开放词汇多标签识别
Recover and Match: Open-Vocabulary Multi-Label Recognition through Knowledge-Constrained Optimal Transport **作者:**谭淏,谭资昌,李俊,刘阿建,万军,雷震 受到DETR启发,我们发现简单的区域-文本匹配能显著提升开放词汇多标签识别性能,并将该过程建模为最优传输问题以抑制负类匹配。然而直接进行最优传输是失效的:(1)预训练局部语义缺失;(2)匹配结果难以泛化到开放词汇场景。为此我们提出局部语义恢复模块捕捉精确的区域性语义,并引入教师传输模型增强开放词汇下的泛化性。方法在自然图像、遥感图像、行人属性等多领域取得大幅性能提升。更重要的是,该方法能作为一种框架提升现有方法的表现,扩展潜力良好。
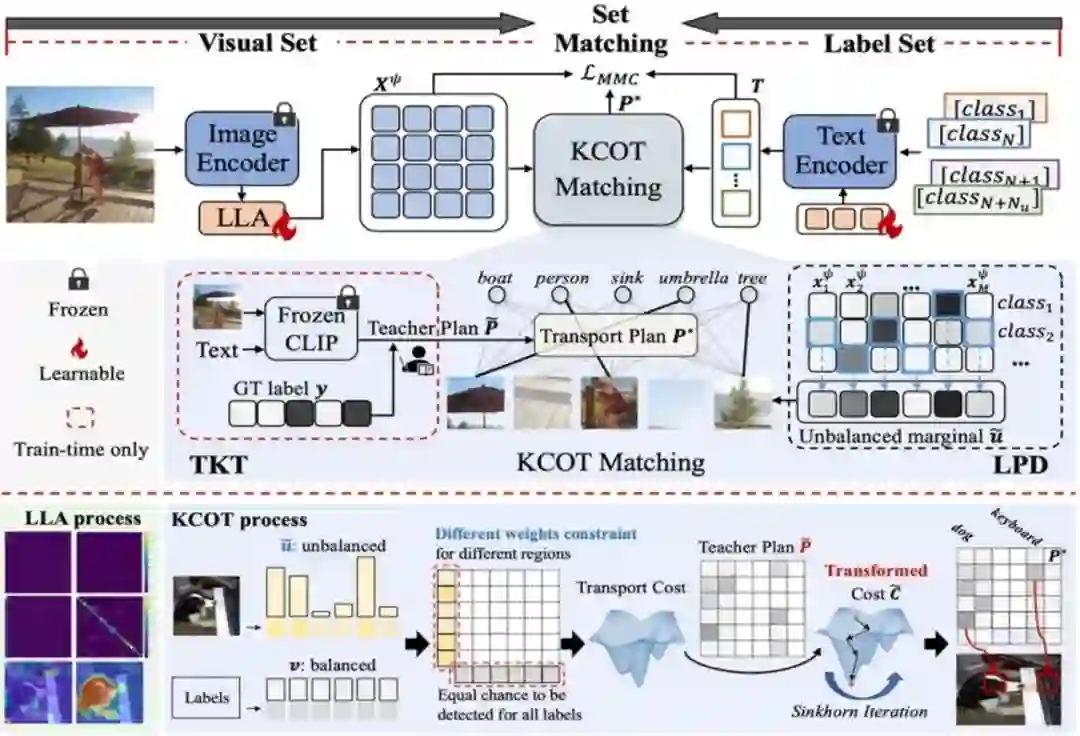
图1. RAM框架示意图
**08. **基于一致性学习潜能的多模态媒体篡改检测与定位
Unleashing the Potential of Consistency Learning for Detecting and Grounding Multi-Modal Media Manipulation **作者:**李毅恒,杨阳,谭资昌,刘欢,陈威华,周旭,雷震 为了应对虚假新闻的威胁,研究人员对多模态媒体篡改检测与定位的研究日益增加。然而,现有方法难以深入建模局部内容,导致其对细粒度伪造的感知能力不足、判定结果不够可靠。针对这一现象,本文提出了一种 “上下文-语义一致性”的新学习范式,提升伪造内容细粒度感知能力。该方法构建了图像模态和文本模态两个分支,它们均包含了两个级联的解码器:上下文一致性解码器和语义一致性解码器,并且遵循相同的标准分别应用于模态内和跨模态场景,以捕捉细粒度的伪造细节。一方面,每个模块引入额外的监督信息学习一致性特征;另一方面,利用伪造感知推理或聚合,深入挖掘伪造线索并进行定位。在公开数据集DGM4上的广泛实验证明了:所提出的方法领先现有的技术,尤其在篡改内容的定位方面性能提升显著。
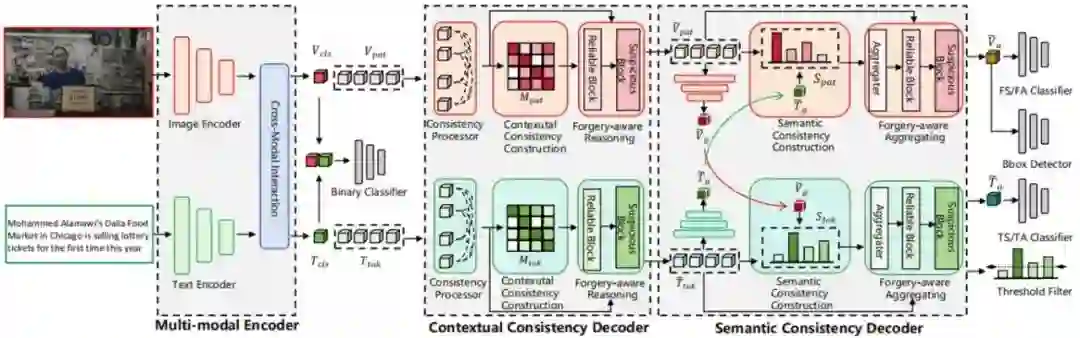
提出的框架包含上下文一致性解码器和语义一致性解码器。它们构建了细粒度一致性矩阵,并且使用一致性损失进行监督。在每个解码器中,采用防伪功能推理或聚合模块以减少混淆内容的干扰,深入挖掘伪造线索。
**09. **MVBoost:利用多视图修正策略增强3D重建
MVBoost: Boost 3D Reconstruction with Multi-View Refinement **作者:**刘祥宇,张小梅,马致远,朱翔昱,雷震 最近在3D生成方面的进展令人瞩目,但目前大多数3D重建模型在很大程度上依赖于现有的3D数据集。多样化3D数据集的稀缺导致3D重建模型的泛化能力有限。本文提出了一种通过生成伪GT数据来增强3D重建的创新框架——MVBoost。MVBoost的关键在于结合多视图生成模型的高精度和3D重建模型的一致性,以创建可靠的数据源。具体而言,给定单视图输入图像,我们采用多视图扩散模型生成多个视图,然后使用大型3D重建模型生成一致的3D数据。MVBoost随后自适应地精炼这些从一致的3D数据渲染的多视图图像,以构建一个用于训练前馈3D重建模型的大规模多视图数据集。此外,输入视图优化模块旨在根据用户的输入图像优化相应的视点,确保最重要的视点能够准确满足用户的需求。大量实验评估表明,我们的方法在重建结果和鲁棒泛化方面优于先前的工作。
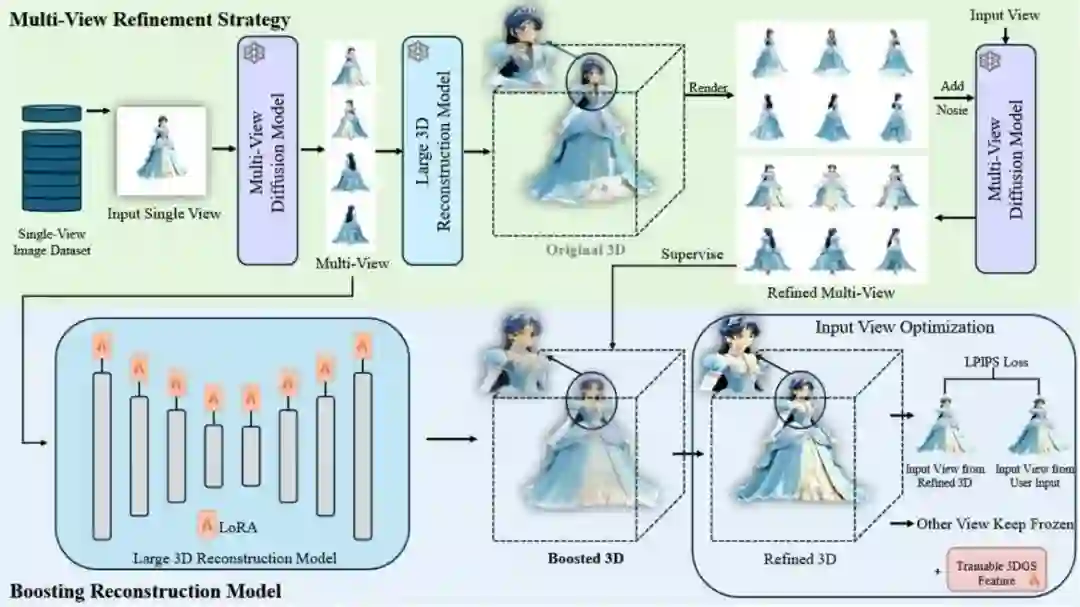
MVBoost框架概述。给定一个单视图图像数据集,我们首先采用多视图扩散模型生成原始多视图数据集。然后将原始多视图输入到大型3D重建模型中,以生成3D高斯。从这个3D高斯点云中渲染出多个视图,并通过扩散模型进行精细化的多视图数据集生成。在训练过程中,精细化的多视图数据集用于通过LoRA监督3D重建模型。最后,生成的3D高斯以优化的方式与特定输入视点对齐,从而获得高保真重建结果。
**10. **基于贝叶斯理论的视觉语言模型的测试时间自适应
Bayesian Test-Time Adaptation for Vision-Language Models **作者:**周李华,叶茂,李帅锋,李念欣,朱霞天,邓磊,刘宏斌,雷震 预训练视觉-语言模型通过在大规模图文对数据上的训练,展现出了强大的多模态表征能力,在图像分类等任务中表现出很好的性能。然而在应用中,测试数据往往和预训练数据的分布存在较大差异,会导致模型性能下降。研究团队提出一种新的TTA方法,称为Bayesian Class Adaptation (BCA),能够在动态环境中提升CLIP的分类精度和推理效率。BCA 基于贝叶斯框架,将预测过程分解为两个部分:可能性和先验,并通过动态更新使模型适应测试数据,该方法核心创新点包括:
- 先验的动态适应。传统方法通常忽略先验的存在,缺少灵活性,BCA能根据测试数据动态调整先验以适应当前数据分布。
- 高效的设计。BCA 不依赖反向传播,而是通过轻量级的统计更新实时适应。在 ImageNet 数据集(ResNet-50模型)上的测试表明,BCA 的推理时间仅为 2.42 分钟,内存占用只比 CLIP 增加了约 4MB。 实验结果表明,该方法在精度、鲁棒性和效率上超越现有方法,适用于动态现实场景,为视觉-语言模型的测试时适应提供了新思路。
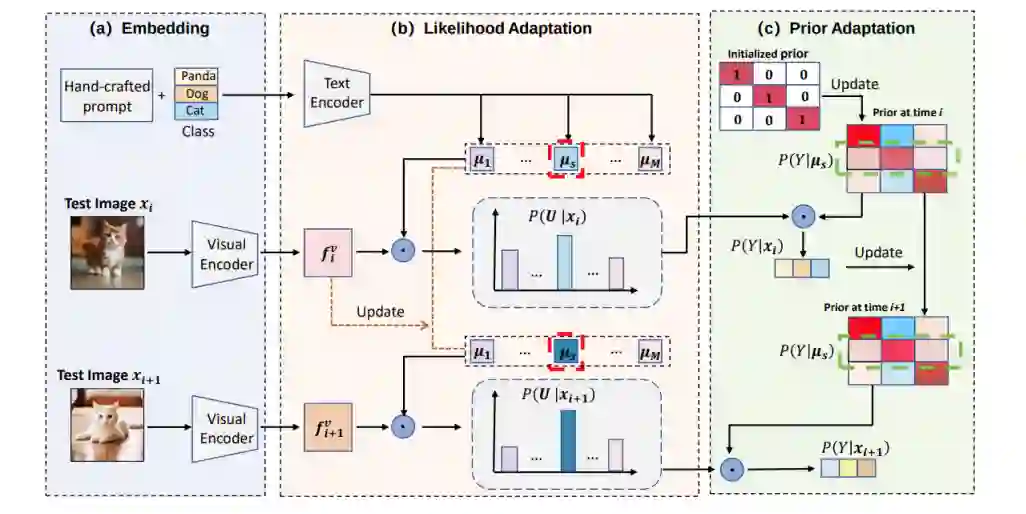
BCA流程:第 i 个测试图像到达时,首先通过视觉编码器生成visual embedding,然后模型基于这个visual embedding进行可能性更新,即更新模型中存储的class embedding,然后再对模型执行先验更新,即调整模型中的类别先验,最终输出后验概率(预测)。
**11. **大规模三维建图的超轻量神经表达
3D-SLNR: A Super Lightweight Neural Representation for Large-scale 3D Mapping **作者:**师晨辉,唐付林,安宁,吴毅红 本文为大场景3D建图提出了一个新的超级轻量的神经表达,具有出色的表现力。该表达基于一组锚定在支持点上的带限局部距离函数(SDF)定义了近表面空间的全局SDF。支持点从点云中采样得到。这些局部 SDF 仅由一个小型的多层感知机(MLP) 参数化,不依赖高维的特征向量。每个 SDF 的状态由位置、旋转和缩放三个可学习的几何属性控制,这使得该表示法能够适应复杂的几何形状。然后,本文开为这种无序表示开发了一种新型并行算法,以高效检测包含每个采样点的局部 SDF,从而能够在训练过程中实时更新局部 SDF 状态。此外,本文还引入了一种剪枝-扩展策略,以进一步增强适应性。本文的低参数模型及其自适应能力的协同作用,使表达极其紧凑,同时具有出色表达能力的。实验结果证明,本文的方法可以以1/5的内存占用达到最好的重建质量。
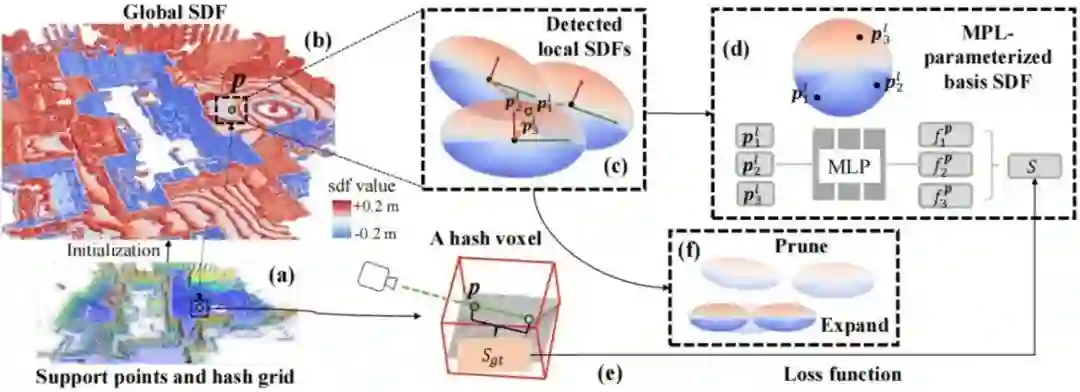
提出方法的框架
**12. **基于置换等变性的相对相机位姿估计
EquiPose: Exploiting Permutation Equivariance for Relative Camera Pose Estimation **作者:**刘雨臻,董秋雷 相对相机位姿估计是三维计算机视觉领域中一个重要的研究主题。近年来,研究者提出了许多相对位姿估计网络,来学习从两幅输入图像到它们对应的相对位姿之间的映射关系。然而,这些网络并不具备相对位姿固有的姿态置换等变性(Pose Permutation Equivariance, PPE):从图像A到图像B的相机位姿矩阵,等于从图像B到图像A的相对位姿矩阵的逆。这意味着,当交换两幅图像的输入顺序时,这些网络将无法获得一致的相对位姿结果。针对这一问题,我们首次引入“PPE映射”的概念,即满足上述PPE特性的映射。进一步地,我们提出了一个通用的相对位姿估计框架EquiPose,该框架可以使用不同的相对位姿估计网络作为基线模型,并约束基线模型具有PPE属性。我们还从理论上证明:EquiPose框架学习到的映射一定是一个PPE映射。在四个公开数据集上的实验结果表明,对于若干预训练的基线模型,EquiPose框架无需微调即可直接提升其性能,而在进行微调后可以进一步提升其性能。
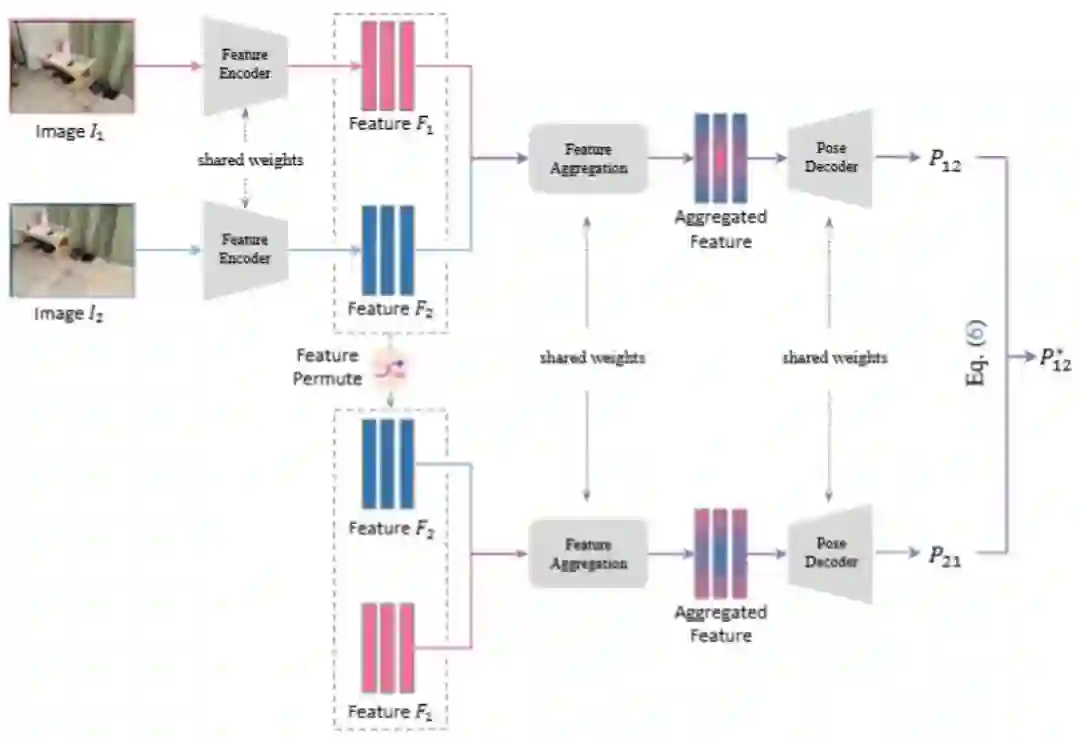
EquiPose框架结构图
**13. **基于遮挡感知神经域自适应的自监督物体位姿估计
ONDA-Pose: Occlusion-Aware Neural Domain Adaptation for Self-Supervised 6D Object Pose Estimation **作者:**谭涛,董秋雷 物体位姿估计是计算机视觉领域中的一个重要主题,传统方法依赖于高质量的物体位姿标签进行全监督训练,而自监督方法则通过利用未标注的真实图像和合成数据进行训练,避免了对手动标注的依赖。针对现有自监督方法在合成图像与真实图像之间的域差距以及遮挡问题,本研究提出了一种基于遮挡感知神经域自适应的自监督物体位姿估计方法——ONDA-Pose。该方法采用三阶段训练策略:首先,利用未标注的真实图像和CAD模型,通过神经辐射场技术,生成与真实图像具有相同物体位姿且纹理与CAD模型渲染图像相似的合成图像;其次,使用在CAD模型渲染的合成数据上预训练的位姿估计器对合成图像进行初始位姿估计,并通过全局物体位姿优化器生成伪标签;最后,利用带有伪标签的真实图像和合成图像对位姿估计器进行自监督训练,进一步提升其性能。实验结果表明,相较于现有主流方法,我们的方法在大多数情况下取得了领先的性能。
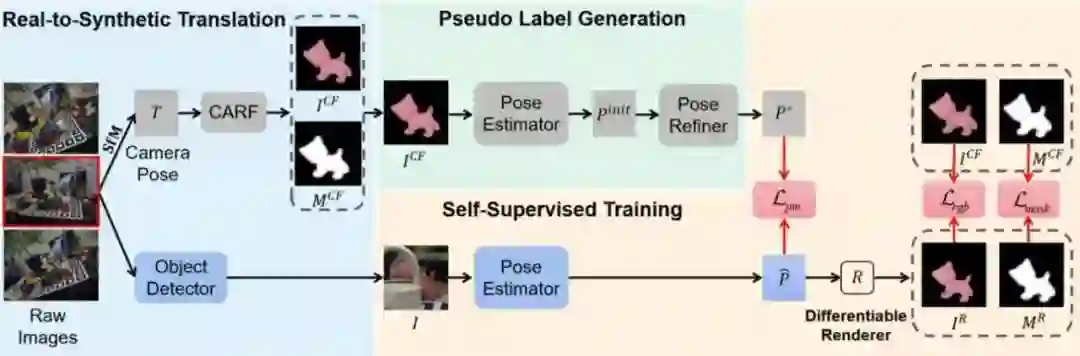
ONDA-Pose框架图
**14. **RoboBrain:实现从抽象指令理解到具象动作表达的具身多模态模型
RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete **作者:**冀昱衡,谭桦杰,史佳禹,郝孝帅,张袁,张恒源,王鹏伟,赵梦迪,穆尧,安鹏举,薛昕达,苏庆杭,吕怀海,郑晓龙,刘家铭,王仲远,仉尚航 近年来,多模态大语言模型(MLLMs)的快速发展显著推动了通用人工智能的研究进程。然而,尽管 MLLMs 在通用任务中表现出色,其在具身场景中的应用仍面临巨大挑战,尤其是在长程操作任务中。这些任务不仅要求机器人能够理解抽象指令,还需具备将指令转化为具体动作的能力。具体而言,长程操作任务的成功执行依赖于以下三种核心能力:任务规划能力、可操作区域感知能力和轨迹预测能力。然而,现有 MLLMs 在这些方面存在显著不足,这主要源于当前缺乏专门为MLLMs和机器人长程操作任务设计的大规模、细粒度数据集。为了填补这一空白,我们提出了ShareRobot,一个专门为机器人操作任务设计的高质量异构数据集。基于ShareRobot,我们开发了 RoboBrain,这是一个能够实现从抽象指令理解到具象动作表达的统一具身多模态大脑模型,旨在增强机器人在长程操作任务中的能力。通过精心设计的数据比例、多阶段训练策略以及长视频和高分辨率图像输入,RoboBrain 实现了从抽象指令理解到具象动作表达的认知跨越,展现了其在机器人实际应用中的潜力。
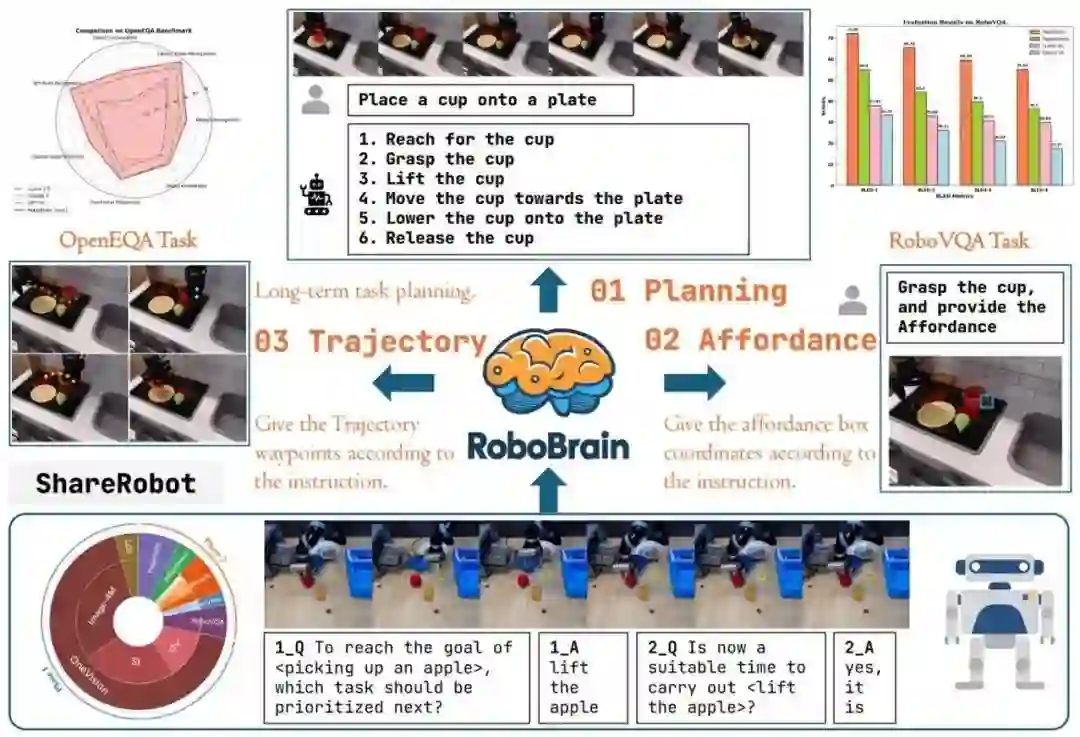
RoboBrain具备完成长程操作任务的三项核心能力:任务规划能力(Planning)、可操作区域感知能力(Affordance Perception)和轨迹预测能力(Trajectory Prediction)。基于我们构建的ShareRobot数据和通用多模态数据,RoboBrain经过精心设计的多阶段训练,在多个具身场景基准中取得了最先进的性能,实现了从抽象指令理解到具象动作表达的认知跨越。
**15. **生成模型在专业图像设计中的差距与挑战
IDEA-Bench: How Far are Generative Models from Professional Designing? **作者:**梁晨,黄梁华,方景武,窦洹彰,王威,吴志凡,石宇鹏,张俊格,赵鑫,刘宇 当前生成模型在文本到图像(T2I)任务上取得显著进展,但在专业设计领域仍存在能力缺陷,难以处理复杂指令、多输入/输出任务或实现专业级细节控制。为了量化这一差距,我们提出 IDEA-Bench,一个涵盖 100 个专业设计任务的基准测试,全面评估当前生成模型在专业设计场景下的表现,并提供改进方向。 IDEA-Bench 包含 100 个任务、275 个测试案例,覆盖文本到图像、图像编辑、多图生成等五大类别,并提供 IDEA-Bench-mini(18 个代表性任务) 进行自动评测。评估采用 1,650 个二元评分项,并结合多模态大模型(MLLM)辅助,以确保专业级任务的精准评估。 实验评测了 FLUX-1、GPT-4o + Stable Diffusion 3、DALL-E 3 等模型,最高得分仅 22.48/100,远未达到专业级设计要求。结果表明,现有模型在多模态理解、风格一致性和任务泛化方面仍存在显著挑战,需进一步优化以缩小与专业设计师的能力差距。
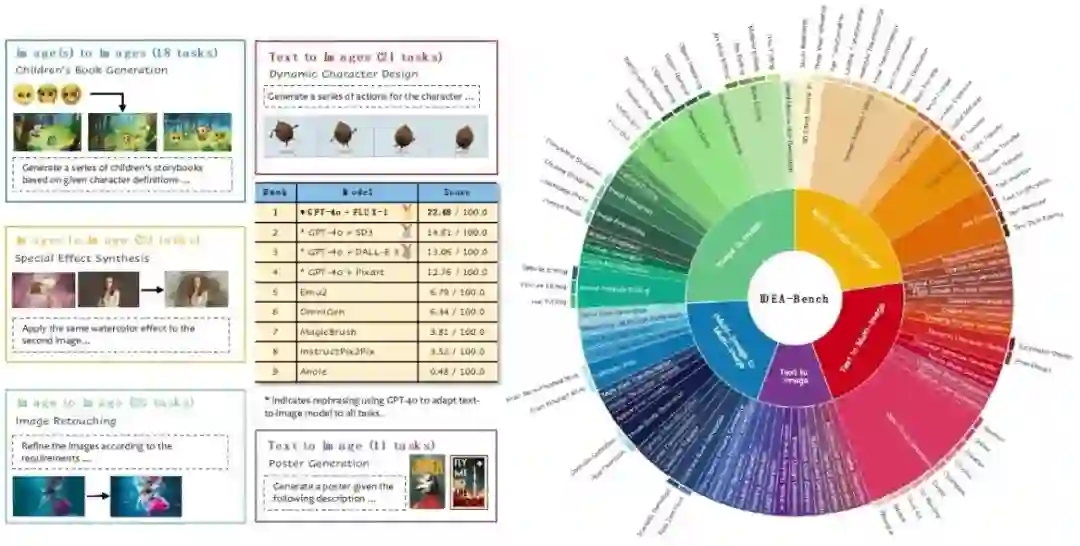
图1. IDEA-Bench概览。IDEA-Bench 包含5个类别,共计100个专业级子任务、275个测试用例、1,650个层次化评估问题。图中提供每个类别子任务示例和定量统计数据,以及主流模型的排行榜。
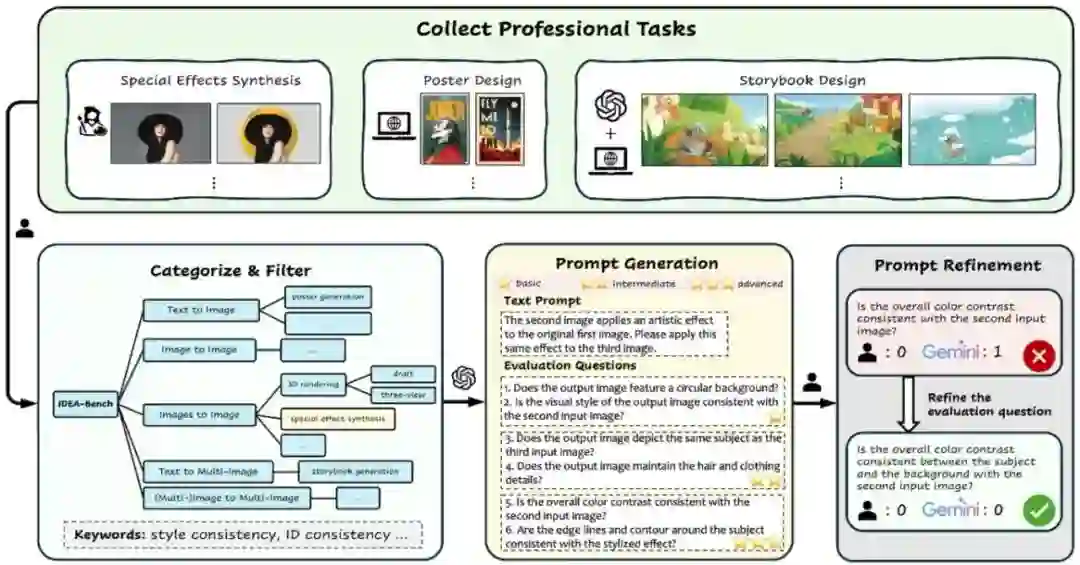
图2. IDEA-Bench从专业设计网站和设计师的任务数据中进行分类和构建,并根据生成模型的能力分配相应的能力关键词。针对每个具体任务,设计图像生成提示词和层次化评测问题。评测人员随后在一个具有代表性的数据子集中优化这些评测问题,以确保评测标准的合理性和一致性。
**16. **DriveDreamer4D:以世界模型为数据引擎的4D驾驶场景表征方法
DriveDreamer4D: World Models Are Effective Data Machines for 4D Driving Scene Representation **作者:**赵国盛,倪超骏,王啸峰,朱政,张学阳,王一达,黄冠,陈新泽,王泊远,张友谊,梅文俊,王欣刚 闭环仿真对于推进端到端自动驾驶系统至关重要。当前的传感器仿真方法,例如NeRF和3DGS,主要依赖与训练数据分布高度一致的条件,这些条件大多局限于前向驾驶场景。因此,这些方法在渲染复杂驾驶操作(如变道、加速、减速)时存在局限性。近期,自动驾驶世界模型的进展展示了生成多样化驾驶视频的潜力。然而,这些方法仍局限于2D视频生成,本质上缺乏捕捉动态驾驶环境复杂细节所需的时空一致性。在本文中,我们提出了DriveDreamer4D,该方法利用世界模型先验知识增强了4D驾驶场景表征能力。具体而言,我们利用世界模型作为数据引擎,合成新轨迹视频,并显式利用结构化条件来控制交通元素的时空一致性。此外,我们提出了“堂兄数据”训练策略,以促进真实数据与合成数据的融合,从而优化4DGS。据我们所知,DriveDreamer4D是首个利用视频生成模型改进驾驶场景中4D重建的方法。实验结果表明,DriveDreamer4D在新轨迹视图下的生成质量显著提升,在FID指标上分别比PVG、S3Gaussian和Deformable-GS提高了32.1%、46.4%和16.3%。此外,DriveDreamer4D显著提升了驾驶代理的时空一致性,这一结论通过全面的用户研究以及NTA-IoU指标分别提升22.6%、43.5%和15.6%得到了验证。

图1. 以往的4D高斯点云方法(如PVG、S3Gaussian、Deformable-GS)在渲染新轨迹(如变道)时面临挑战。DriveDreamer4D通过整合世界模型的先验知识,增强了4D驾驶场景的表征能力,从而显著提升了复杂场景和新轨迹视角下的渲染质量。
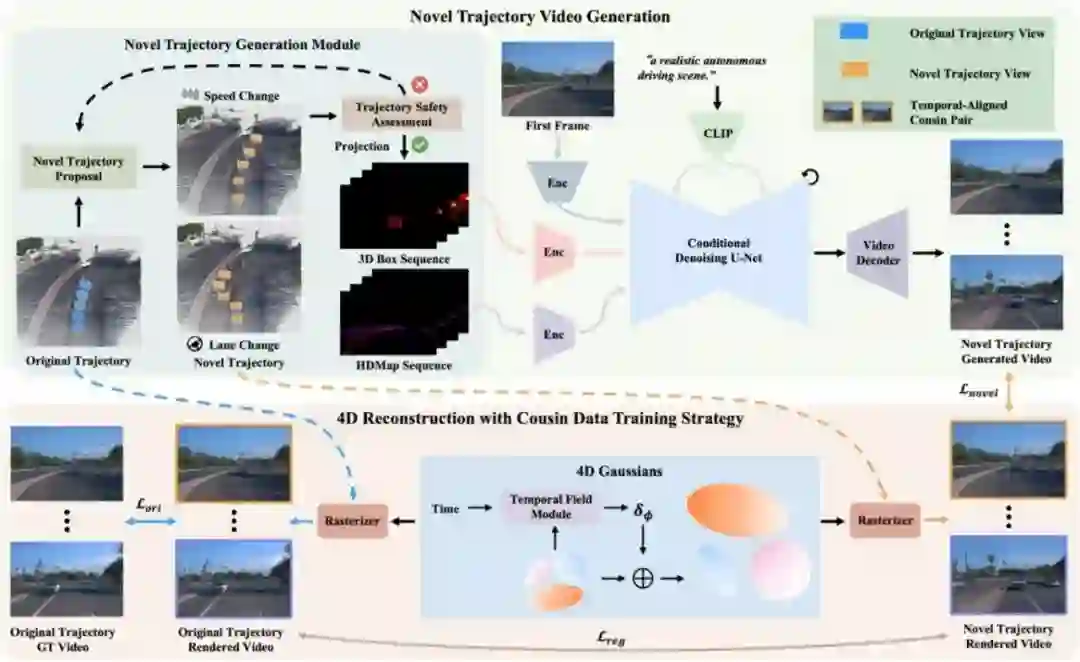
图2. DriveDreamer4D的整体框架。首先,通过改变原始轨迹的动作(例如,转向角度、速度),可以获得新的轨迹。在第一帧和新轨迹的结构化信息(如3D边界框、高清地图)的条件下,生成对应的新轨迹视频。随后,将时间对齐的cousin pair(原始轨迹视频与新轨迹视频)进行融合,以优化4D高斯点云模型,并通过计算正则化损失来确保感知一致性。
17. 视觉生成式模型的高效人类偏好评估
K-Sort Arena: Efficient and Reliable Benchmarking for Generative Models via K-wise Human Preferences **作者:**李志凯,刘学文,Dongrong Joe Fu,李建权,顾庆毅,Kurt Keutzer,Zhen Dong 视觉生成式模型的快速发展需要高效且可靠的评估方法。Arena 平台收集用户对模型比较的投票,可以根据人类偏好对模型进行排名。然而,传统Arena的成对对比方式、模型匹配策略以及模型能力建模方法使其在效率和可靠性上面临挑战,这会影响对新模型能力的快速评估和排行榜的及时更新。为此,本文提出K-Sort Arena,采用 K-wise 比较,允许 K 个模型参与自由混战,提供比成对比较更丰富的信息,并设计基于探索-利用的匹配算法和概率建模,从而实现更高效和更可靠的模型排名。目前,K-Sort Arena 已收集几千次高质量投票并构建了全面的模型排行榜,已用于评估几十种最先进的视觉生成模型,包括文生图和文生视频模型。K-Sort Arena已经历数月的项目内测,期间收到来自加州大学伯克利分校, 新加坡国立大学, 卡内基梅隆大学, 斯坦福大学, 普林斯顿大学, 北京大学等数十家机构的专业人员的技术反馈,现已公开线上发布。
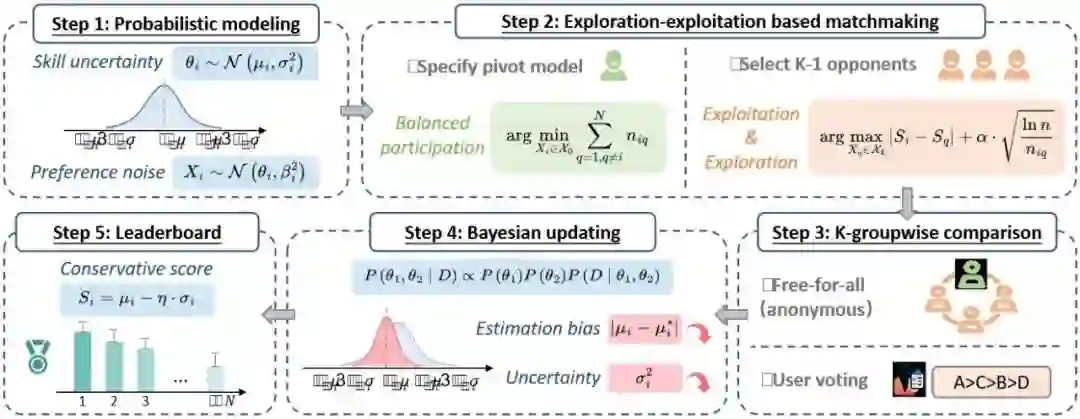
K-Sort Arena总体流程
**18. **CacheQuant:全面加速扩散模型
CacheQuant: Comprehensively Accelerated Diffusion Models **作者:**刘学文,李志凯,顾庆毅 扩散模型在图像生成领域展现出卓越的能力。然而,由于时序和结构层面的冗余,其推理速度较慢且网络复杂,限制了在低延迟应用中的实际部署。现有的加速方法通常分别针对时序和结构两个层面进行优化,但单独优化各层面往往导致显著的性能下降,而联合优化虽然能增强加速效果,却并非完全正交,简单整合两层面的优化方法往往难以取得理想的性能表现。 为此,我们提出了一种全新的CacheQuant范式,该方法无需额外训练,通过联合优化模型缓存与量化技术,实现对扩散模型时序和结构层面的全面加速。具体而言,我们采用动态规划方法优化模型缓存调度,在充分考虑缓存与量化特性的基础上,减少加速引入的误差。此外,我们提出解耦误差校正机制,进一步缓解累积误差的影响。实验结果表明,CacheQuant 在Stable Diffusion 任务中实现了 5.18× 加速和 4× 模型压缩,而CLIP 分数仅下降 0.02。
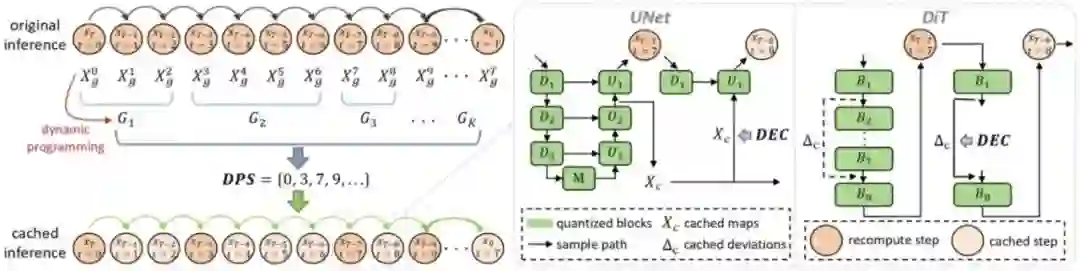
本研究提出方法的总览图。我们采用动态规划方法(DPS)获得引入加速误差最小的模型缓存序列表,进一步通过解耦误差校正机制(DEC)缓解累积的误差。
**19. **HumanDreamer:通过解耦生成生成可控的人体运动视频
HumanDreamer: Generating Controllable Human-Motion Videos via Decoupled Generation **作者:**王泊远,王啸峰,倪超骏,赵国盛,杨智钦,朱政,张沐阳,周钰坤,陈新泽,黄冠,刘丽红,王欣刚 人体运动视频生成一直是一项具有挑战性的任务,主要是由于学习人体运动固有的困难。虽然一些方法已经尝试通过姿态控制来明确地驱动以人为中心的视频生成,但是这些方法通常依赖于从现有视频导出的姿态,从而缺乏灵活性。为了解决这个问题,我们提出了HumanDreamer,一个解耦的人类视频生成框架,首先从文本提示生成不同的姿势,然后利用这些姿势来生成人类运动视频。具体来说,我们提出了MotionVid,这是用于人体运动姿态生成的最大数据集。基于数据集,我们提出了MotionDiT,它被训练成从文本提示中生成结构化的人体运动姿势。此外,引入了一种新的LAMA损耗,这两种损耗共同导致FID显著提高62.4%,沿着,top1、top2和top3的R精度分别提高41.8%、26.3%和18.3%,从而提高了文本到姿态控制精度和FID指标。我们在各种姿势到视频基线的实验表明,我们的方法生成的姿势可以产生多样化和高质量的人体运动视频。此外,我们的模型可以促进其他下游任务,如姿势序列预测和2D-3D姿态升维。
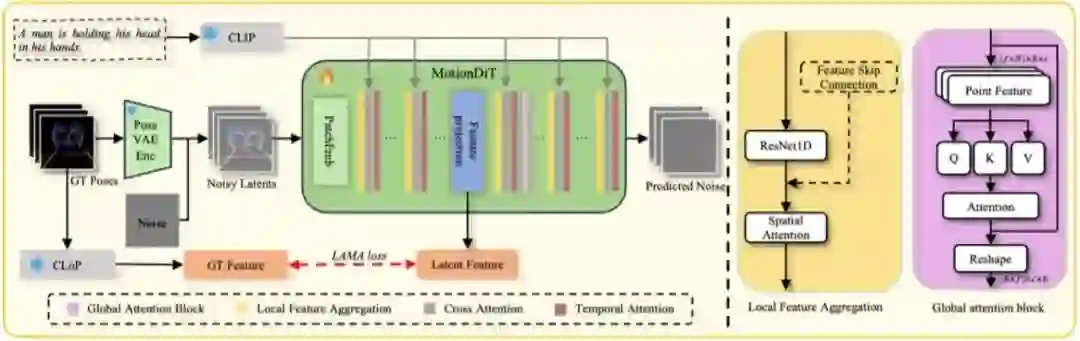
所提出的文本到姿态生成的训练流程。姿态数据通过姿态变分自编码器(Pose VAE)在潜在空间中编码,随后这些数据被提出的MotionDiT处理,在此过程中利用局部特征聚合和全局注意力来捕捉整个姿态序列的信息。最后,通过提出的CLoP计算LAMA损失,这增强了MotionDiT的训练。
**20. **基于贝叶斯提示流学习的零样本异常检测
Bayesian Prompt Flow Learning for Zero-Shot Anomaly Detection **作者:**屈震,陶显,宫新一,曲世辰,陈麒宇,张正涛,王欣刚,丁贵广 近年来,视觉-语言模型在零样本异常检测中表现卓越,可利用辅助数据训练后直接执行跨类别异常检测,如工业缺陷识别或医疗病灶检测。现有方法通常通过手工设计文本提示或优化可学习的提示向量来构建文本输入。然而,这些方法面临以下挑战:1) 手工设计的提示需要大量专家知识和反复试验;2) 单一形式的可学习提示难以捕捉复杂的异常语义;3) 无约束的提示空间限制了模型对未见类别的泛化能力。为了解决这些问题,我们提出贝叶斯提示流学习(Bayes-PFL),从贝叶斯视角将提示空间建模为可学习的概率分布。具体而言,我们设计了一种提示流模块,用于学习图像特定和图像无关的分布,并将二者结合以对文本提示空间进行正则化,从而提升模型在未见类别上的泛化能力。这些学习到的分布随后用于采样生成多样化的文本提示,从而有效覆盖提示空间。此外,我们引入了一种残差跨模态注意力 (RCA) 模块,以更好地对齐动态文本嵌入与细粒度图像特征。
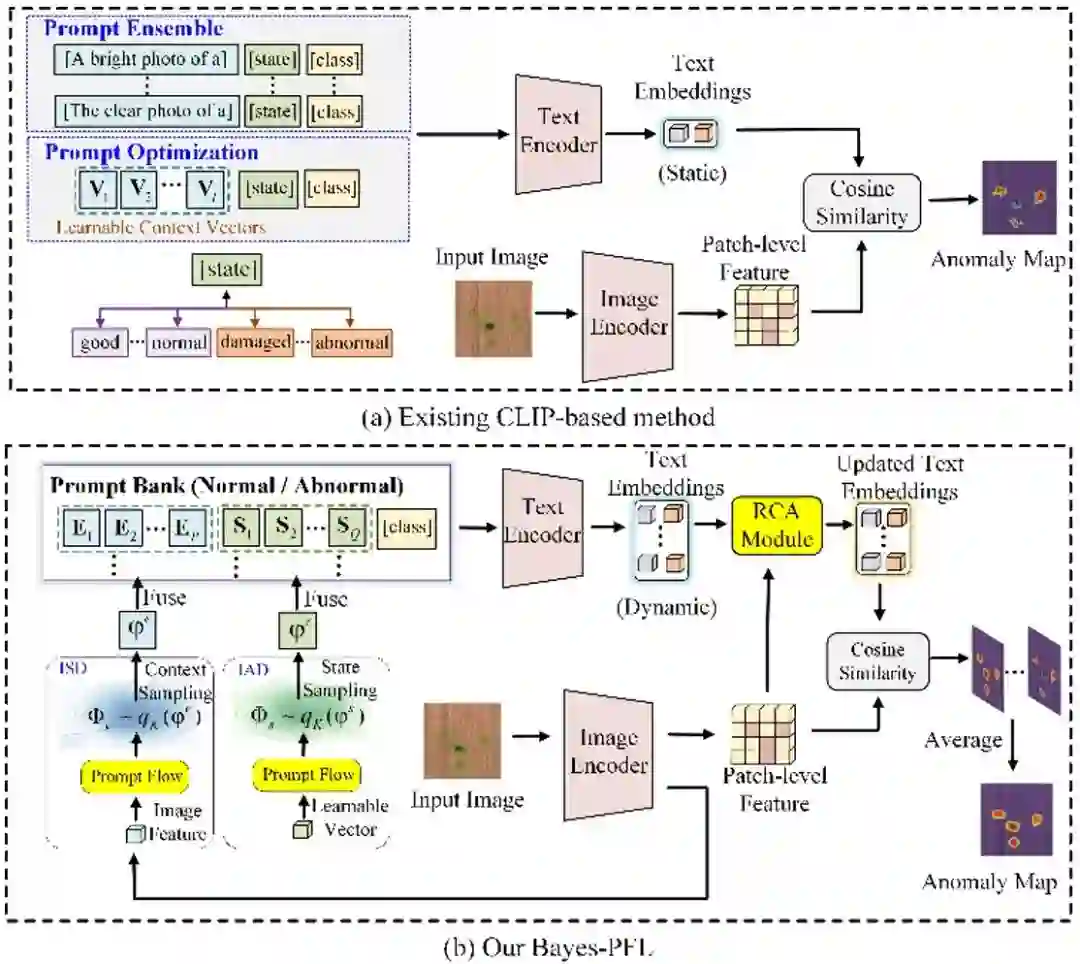
**21. **BWFormer: 基于Transformer的机载雷达点云建筑物线框重建方法
BWFormer: Building Wireframe Reconstruction from Airborne LiDAR Point Cloud with Transformer **作者:**刘昱州,朱灵杰,叶翰樵,黄尚锋,高翔,郑先伟,申抒含 本文提出了一种基于Transformer结构从机载激光雷达点云重建建筑物线框结构的新模型:BWFormer。本方法采用自下而上的方式进行求解,首先在2D平面上检测建筑角点,然后将其提升到3D空间并进行连接关系的检测,同时通过引入额外的数据增强来增强模型的泛化性。由于机载雷达点云的2.5D特性,本方法通过将点云投影到地面平面来生成2D高度图从而简化问题。在高度图的基础上,本方法首先预测一个像素级角点概率图,以确定可能的2D角点。接着,基于 Transformer网络,将2D角点与额外的高度嵌入结合进行初始化,从而预测3D角点。这种2D-3D相结合的角点检测策略显著减少了角点检测的搜索空间。为了恢复角点之间的拓扑连接,本方法提出了新的边注意力机制,从而利用高度图中的几何和视觉特征进行边预测。该机制能够同时提取全局特征并保留局部细节。此外,考虑到该领域可用数据集有限且点云分布不规则的数据特性,本方法采用了条件隐变量扩散模型进行激光雷达扫描模拟从而实现数据增强。实验结果表明,BWFormer在建筑物线框重建指标尤其是完整性方面明显优于其他最新的主流方法。
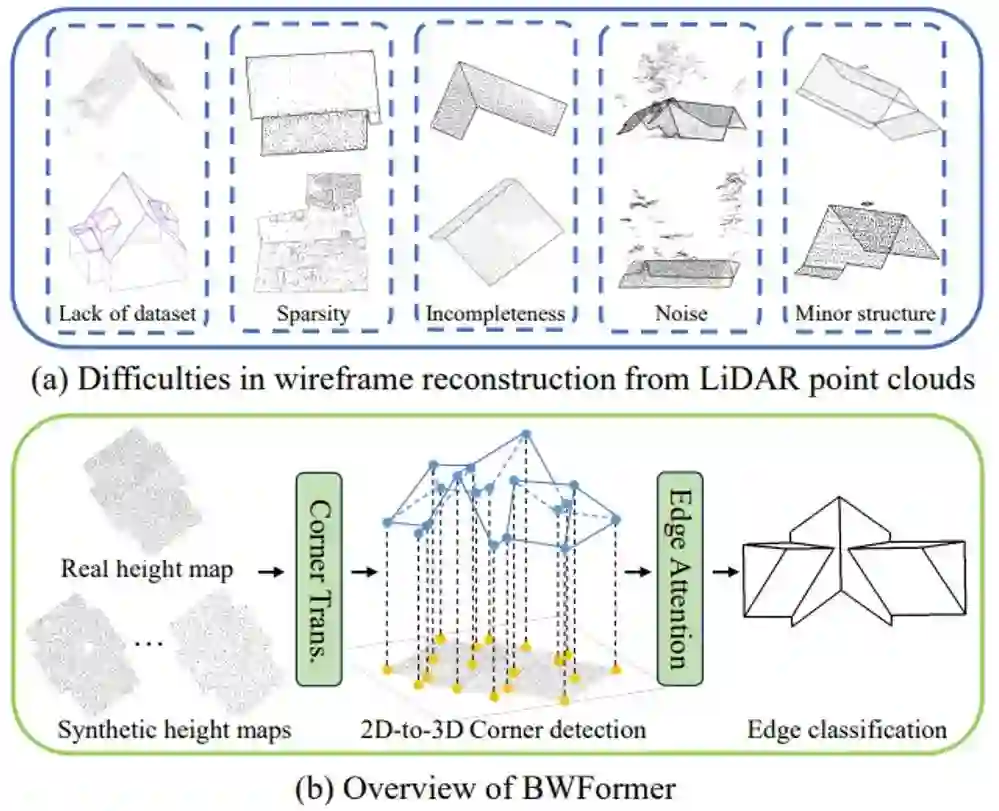
激光雷达点云线框重建面临的挑战与BWFormer流程图
