CVPR 2020 论文大盘点-动作检测与动作分割篇
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文继 CVPR 2020 论文大盘点-动作识别篇 之后继续总结CVPR 2020 中动作(action)相关的论文。
涉及的方向包括:
动作检测(Action Detection)
动作分割(Action Segmentation)
重点动作识别(Action Spotting)
动作解析 (Action Parsing)
上一篇中动作识别(Action Recognition)指对剪辑后的一段包含特定动作的视频进行分类,但大部分情况下视频是未经剪辑的。
在视频中定位动作并分类就是动作检测(Action Detection),也被称为动作定位(Action Localization)。其任务为找到动作的开始帧和结束帧并进行分类。
动作分割(Action Segmentation)则更进一步,为对一段未剪辑视频进行分段,并对每一段视频分配预先定于的动作标签。
重点动作识别(Action Spotting) 为CVPR 2018提出的任务,多用于足球比赛视频分析,即在大量视频中找到出现次数极少的“重要”事件,比如进球、红牌罚下等。
动作解析(Action Parsing)为今年CVPR 商汤等新提出的任务,在一段动作视频中,定义一连串子动作(sub-action),动作解析即定位这些子动作的开始帧。该任务可更好的进行动作间和动作内部的视频理解。
以上检测、分割、识别、解析等概念在计算机视觉领域并不新鲜,只是在视频理解领域,它们各自有了新内涵。
随着视频应用的大爆发,海量视频分析与理解的需求也越来越强烈,各大互联网公司几乎都有在研究,感兴趣的小伙伴不妨探索。
大家可以在:
http://openaccess.thecvf.com/CVPR2020.py
按照题目下载这些论文。
如果想要下载所有CVPR 2020论文,请点击这里:
CVPR 2020 论文全面开放下载,含主会和workshop
动作检测(Action Detection)
学习鉴别信息进行在线动作检测
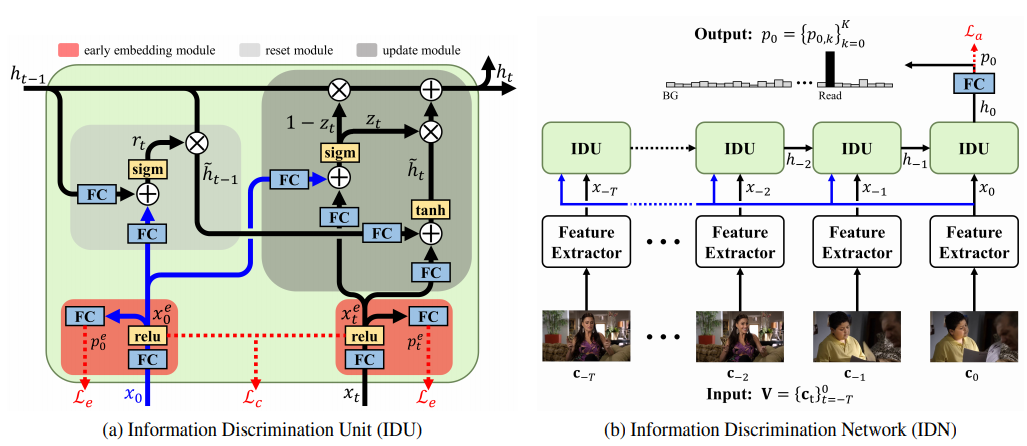
Learning to Discriminate Information for Online Action Detection
作者 | Hyunjun Eun, Jinyoung Moon, Jongyoul Park, Chanho Jung, Changick Kim
单位 | KAIST;ETRI;国立韩巴大学;SK Telecom
代码 | https://github.com/hjeun/idu
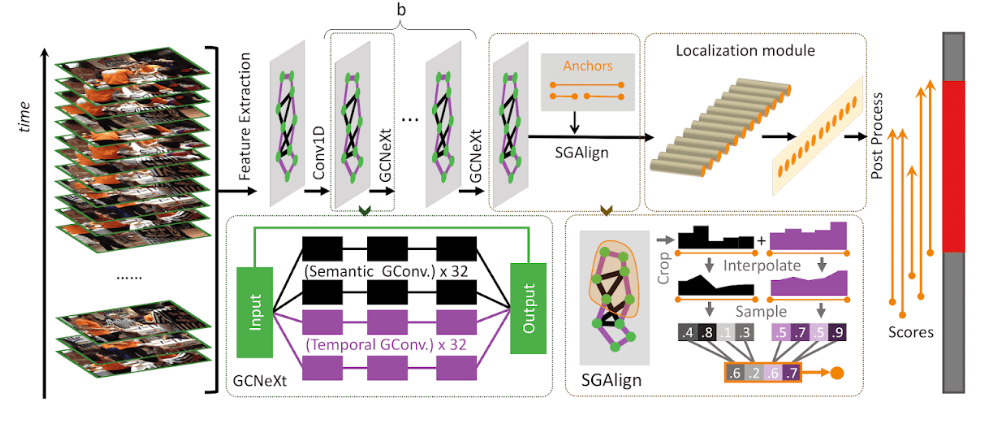
G-TAD: Sub-Graph Localization for Temporal Action Detection
作者 | Mengmeng Xu, Chen Zhao, David S. Rojas, Ali Thabet, Bernard Ghanem
单位 | KAUST
代码 | https://github.com/frostinassiky/gtad
主页 | https://www.deepgcns.org/app/g-tad
通过生成式注意力模型实现弱监督动作定位方法
Weakly-Supervised Action Localization by Generative Attention Modeling
作者 | Baifeng Shi, Qi Dai, Yadong Mu, Jingdong Wang
单位 | 北大;微软亚洲研究院
代码 | https://github.com/bfshi/DGAM-Weakly-Supervised-Action-Localization

ActionBytes: Learning From Trimmed Videos to Localize Actions
作者 | Mihir Jain, Amir Ghodrati, Cees G. M. Snoek
单位 | Qualcomm AI Research,高通公司;阿姆斯特丹大学
无监督视频动作定位
Learning Temporal Co-Attention Models for Unsupervised Video Action Localization
作者 | Guoqiang Gong, Xinghan Wang, Yadong Mu, Qi Tian
单位 | 北大;华为诺亚方舟实验室
动作分割(Action Segmentation)
SCT: Set Constrained Temporal Transformer for Set Supervised Action Segmentation
作者 | Mohsen Fayyaz, Jurgen Gall
单位 | 波恩大学
代码 | https://github.com/MohsenFayyaz89/SCT
(即将)
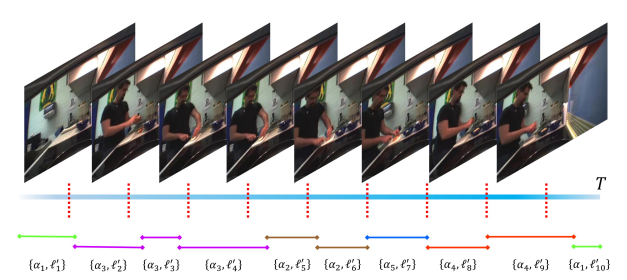
Set-Constrained Viterbi for Set-Supervised Action Segmentation
作者 | Jun Li, Sinisa Todorovic
单位 | 俄勒冈州立大学
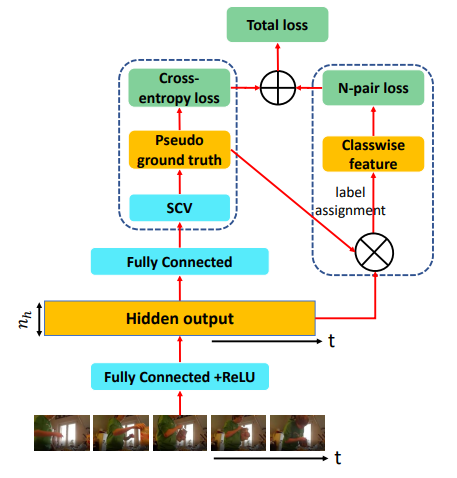
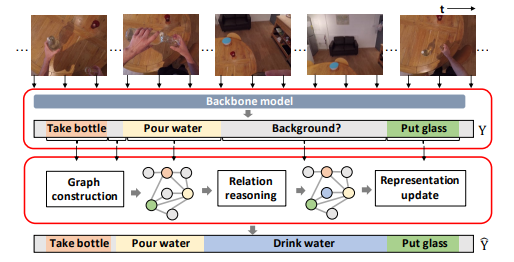
Improving Action Segmentation via Graph-Based Temporal Reasoning
作者 | Yifei Huang, Yusuke Sugano, Yoichi Sato
单位 | 东京大学
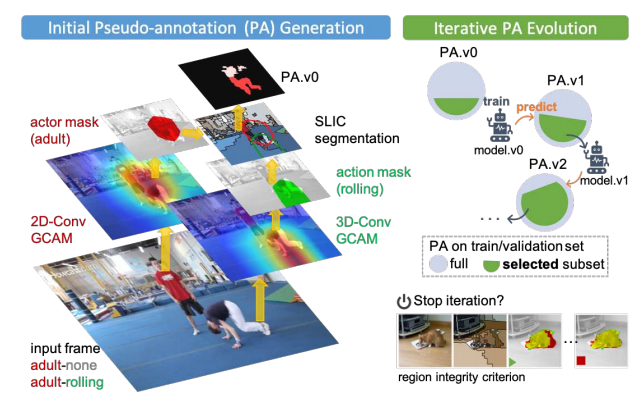
Learning a Weakly-Supervised Video Actor-Action Segmentation Model With a Wise Selection
作者 | Jie Chen, Zhiheng Li, Jiebo Luo, Chenliang Xu
单位 | 罗切斯特大学
Action Spotting
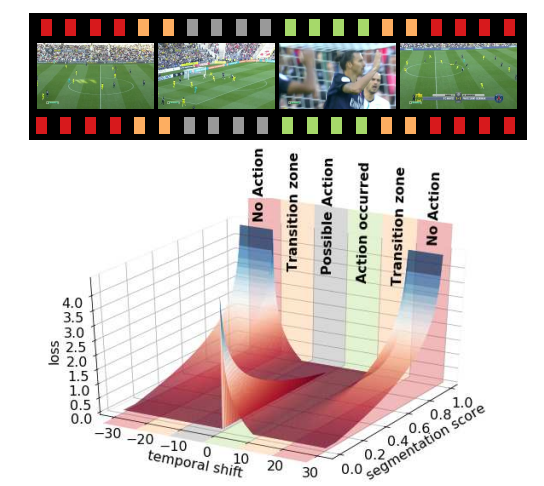
一个用于足球视频中重点动作识别的上下文感知损失函数
A Context-Aware Loss Function for Action Spotting in Soccer Videos
作者 | Anthony Cioppa, Adrien Deliege, Silvio Giancola, Bernard Ghanem, Marc Van Droogenbroeck, Rikke Gade, Thomas B. Moeslund
单位 | KAUST;列日大学;奥尔堡大学
代码 | https://github.com/cioppaanthony/context-aware-loss
Action Parsing
通过时序动作解析实现动作内和动作间的理解
Intra- and Inter-Action Understanding via Temporal Action Parsing
作者 | Dian Shao, Yue Zhao, Bo Dai, Dahua Lin
单位 | 香港中文大学与商汤联合实验室
主页 | https://sdolivia.github.io/TAPOS/

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life

