

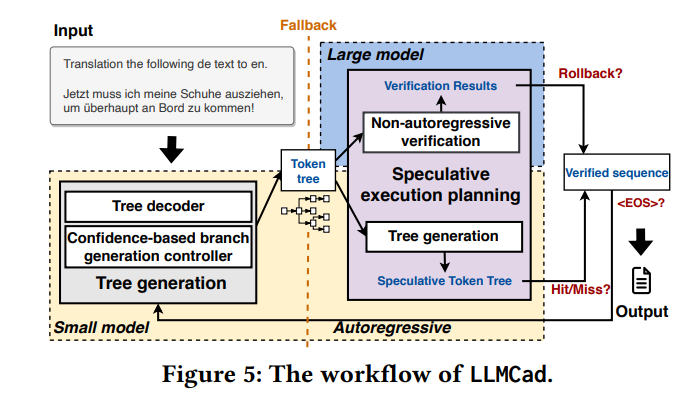
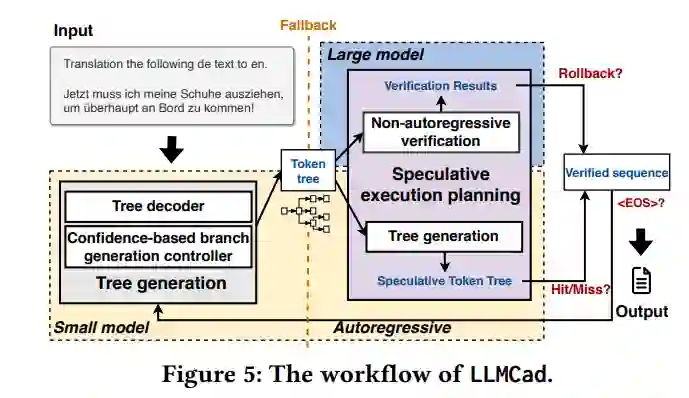
生成性任务,如文本生成和问答,在移动应用领域占据着关键地位。由于对隐私问题的敏感性,对它们在移动设备上直接执行的需求正在增长。目前,执行这些生成性任务在很大程度上依赖于大型语言模型(LLMs)。然而,这些设备的有限内存容量对这些模型的可扩展性构成了严峻挑战。在我们的研究中,我们介绍了LLMCad,一种专门设计用于高效生成自然语言处理(NLP)任务的创新型设备内推理引擎。LLMCad的核心思想围绕模型协作展开:一个位于内存中的紧凑型LLM负责生成最直接的标记,而一个高精度的LLM则负责验证这些标记并纠正任何已识别的错误。LLMCad引入了三种新技术:(1)与按顺序生成候选标记不同,LLMCad利用较小的LLM构建标记树,包含更广泛的可信标记路径。随后,较大的LLM可以高效地同时验证所有这些路径。(2)它采用了一种自动调整的回退策略,当较小的LLM生成错误的标记时,迅速启动验证过程。(3)为了确保标记的连续生成流,LLMCad在验证过程中通过实施计算-IO流水线来猜测生成标记。通过一系列广泛的实验,LLMCad展示了印象深刻的标记生成速度,达到了比现有推理引擎快9.3倍的速度。
成为VIP会员查看完整内容

相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日