

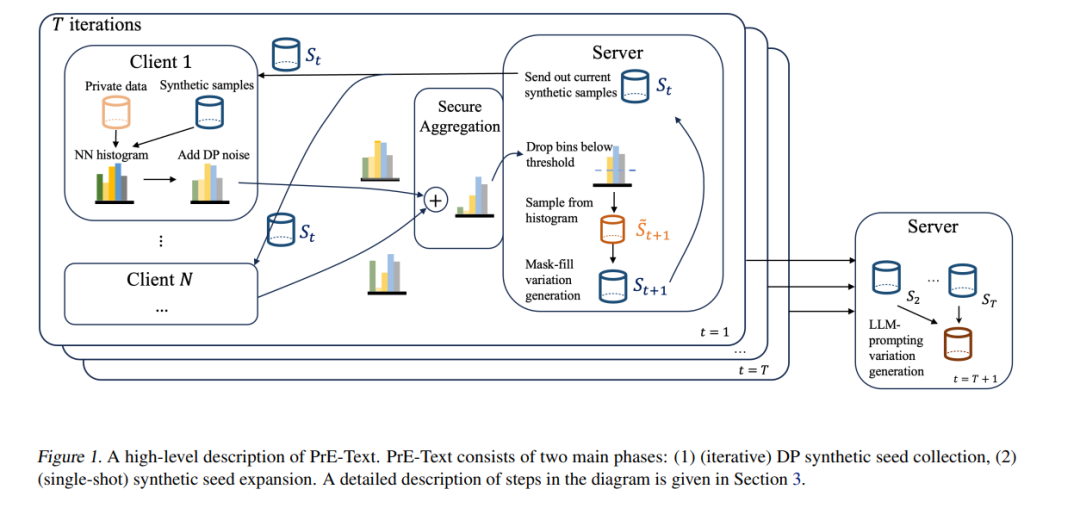
设备上的训练是目前在私人、分布式用户数据上训练机器学习(ML)模型的最常见方法。尽管如此,设备上的训练存在几个缺点:(1)大多数用户设备太小,无法在设备上训练大型模型,(2)设备上的训练对通信和计算资源需求很高,(3)设备上的训练难以调试和部署。为了解决这些问题,我们提出了Private Evolution-Text(PrE-Text),一种生成差分隐私(DP)合成文本数据的方法。首先,我们展示了在多个数据集上,使用PrE-Text合成数据训练的小模型(适合在用户设备上运行的模型)在实际隐私制度下(ϵ = 1.29,ϵ = 7.58)优于在设备上训练的小模型。我们在使用9倍更少的轮次、每轮次6倍更少的客户端计算和每轮次100倍更少的通信的情况下实现了这些结果。其次,在PrE-Text的DP合成数据上微调大型模型提高了大型语言模型(LLM)在相同隐私预算范围内的私人数据上的性能。总而言之,这些结果表明,在DP合成数据上训练可以比在设备上对私人分布式数据进行模型训练更优。
代码可在https://github.com/houcharlie/PrE-Text获得。
成为VIP会员查看完整内容
相关内容
专知会员服务
27+阅读 · 2022年3月22日
专知会员服务
99+阅读 · 2020年7月3日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日


相关VIP内容
专知会员服务
27+阅读 · 2022年3月22日
专知会员服务
99+阅读 · 2020年7月3日
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日