

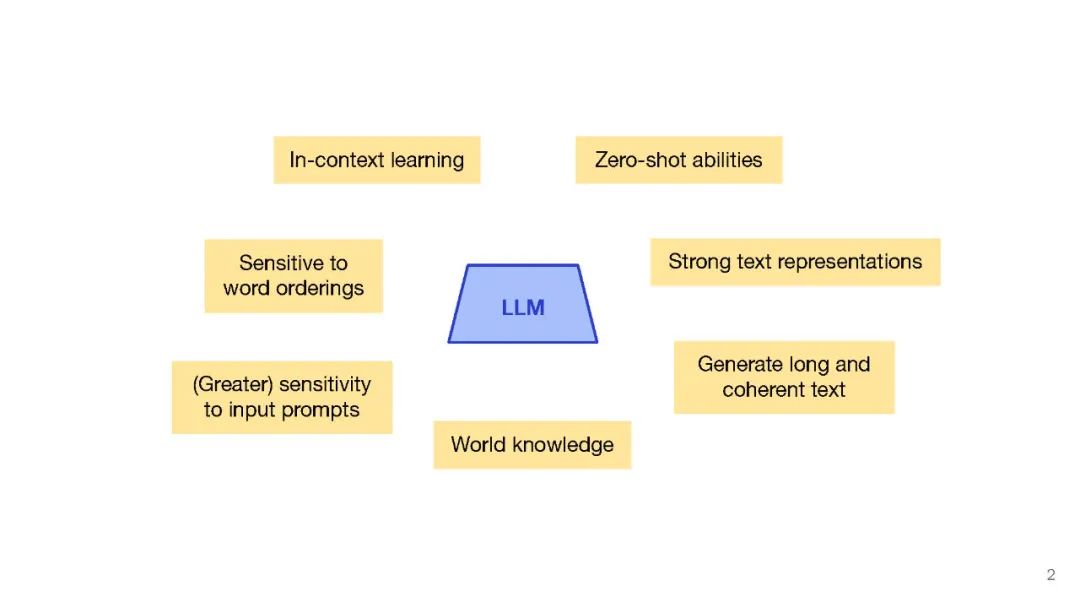
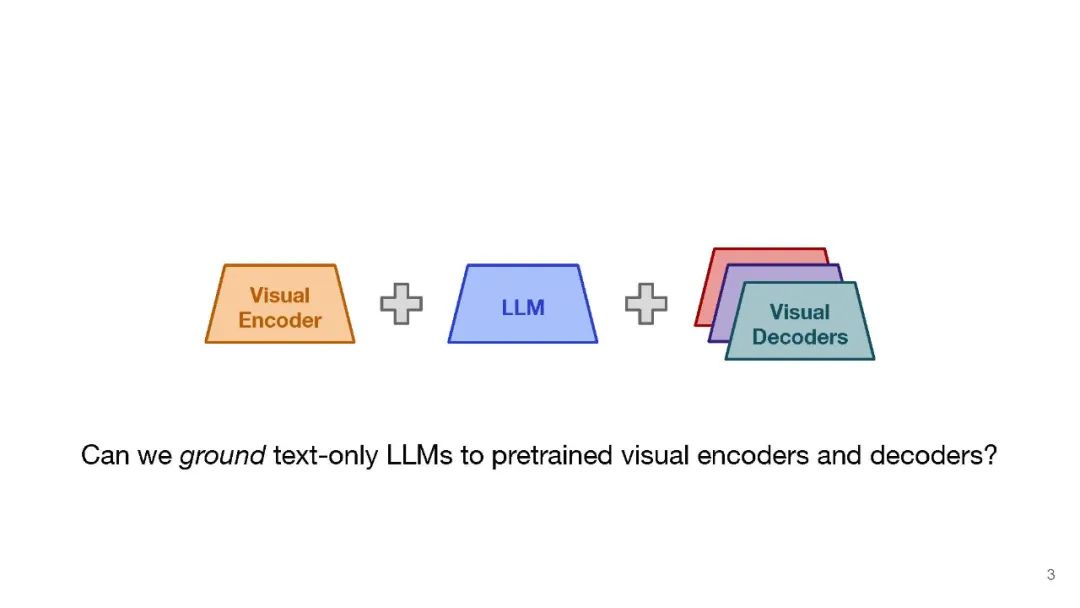
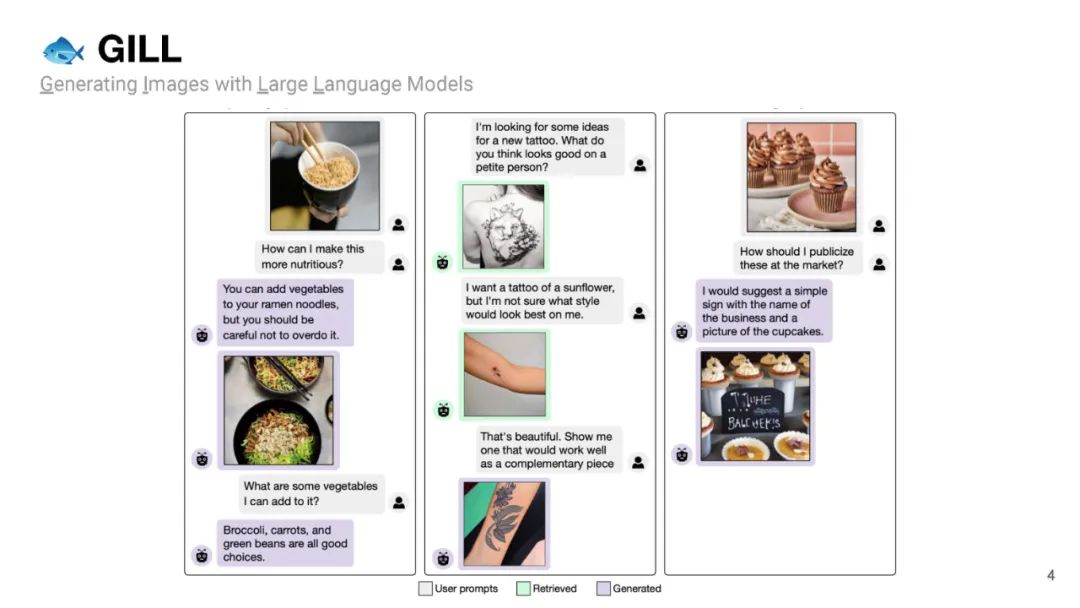
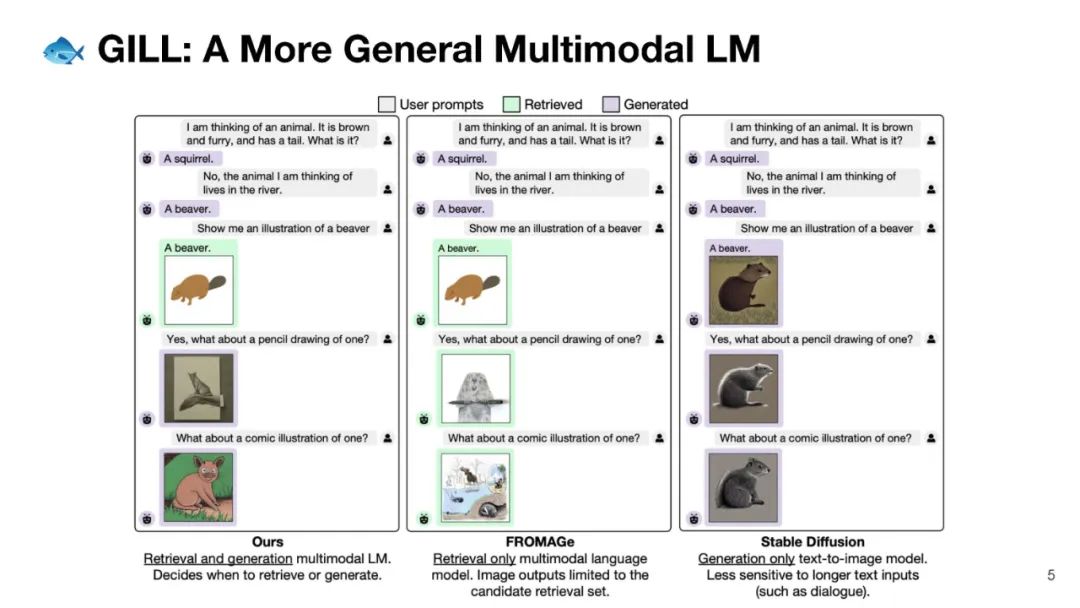
我们提出了一种方法,将冻结的仅文本大型语言模型(LLMs)与预训练的图像编码器和解码器模型融合,通过在它们的嵌入空间之间进行映射。我们的模型展示了一系列多模态功能:图像检索、新颖的图像生成和多模态对话。我们的方法是首个能够根据任意交错的图像和文本输入生成连贯的图像(和文本)输出的方法。为了在图像生成上取得强大的性能,我们提出了一个高效的映射网络,将LLM与现成的文本到图像生成模型相连接。这个映射网络将文本的隐藏表示转换为视觉模型的嵌入空间,使我们能够利用LLM的强大文本表示来进行视觉输出。我们的方法在涉及更长和更复杂语言的任务上超越了基线生成模型。除了新颖的图像生成,我们的模型还能够从预先指定的数据集中检索图像,并在推理时决定是检索还是生成。这是通过一个基于LLM的隐藏表示进行条件化的学习决策模块完成的。与之前的多模态语言模型相比,我们的模型展现了更广泛的功能。它可以处理图像和文本输入,并生成检索到的图像、生成的图像和生成的文本——在测量上下文依赖性的几项文本到图像任务中,超越了非LLM基础的生成模型。


成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日