

关键词**:**静5前沿讲座

编者按
2022年12月23日,美国卡耐基梅隆大学智能安全实验室(CMU-Safe AI Lab)的副教授赵鼎博士受邀带来题为“On the Safety and Generalizability of Trustworthy Intelligent Autonomy”的在线报告。报告由中心助理教授董豪老师主持,相关内容通过蔻享学术、Bilibili 同步直播,线上数百人观看。

赵鼎教授做线上报告
讲座开始,赵老师首先介绍了可信赖智能(Trustworthy AI)的重要性。随着 AI 发展的场景越来越贴近人的生活,AI 的可信赖性成为了部署 AI 策略到现实世界中的关键障碍。因此,AI 的可信赖性正受到从企业到高校机构越来越高的重视。赵老师领导的 Safe AI Lab 实验室的宗旨就是发展理论上可靠同时高效实用的可信赖的 AI 技术。为此,赵老师本次讲座将主要介绍他研究的两个方向,安全性(Safety)与泛化性(Generalization)。

左:Safe AI Lab实验室的研究目标。右:赵老师在可信赖智能(Trustworthy AI)上的研究方向。
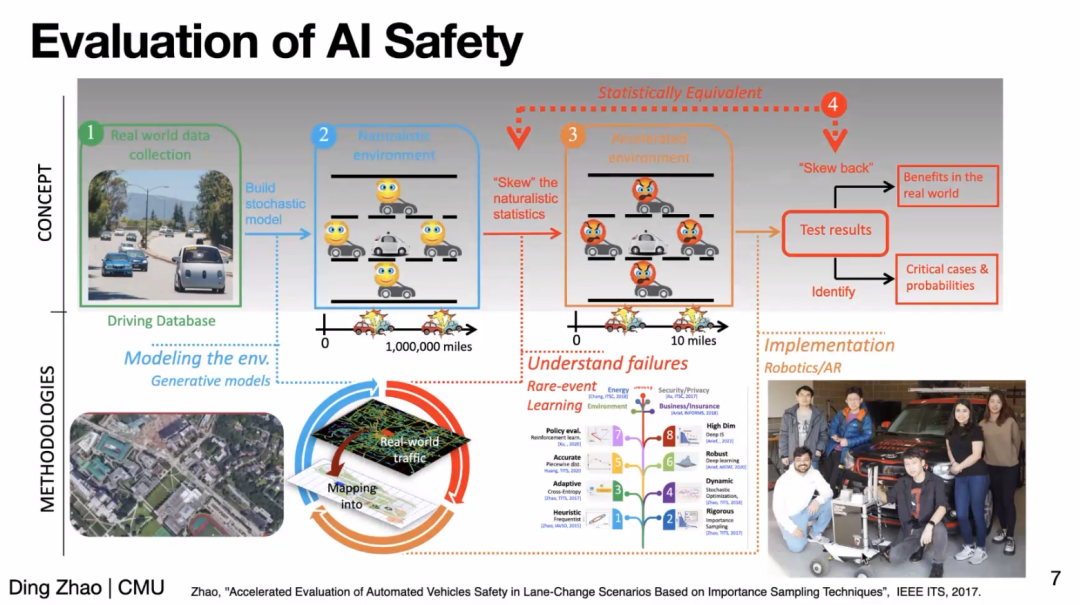
在安全性(Safety)方面,赵老师先以无人驾驶场景为例介绍了如何高效评估 AI 策略安全性能的工作。赵老师指出,无人驾驶场景中的危险事件是稀疏(rare)的,例如北美可能平均100万英里才会发生一次车祸。为了高效地评估(evaluation),赵老师提出加速环境(accelerated environment)基于 importance sampling 增加危险事件的密度,从而高效地获得和实际环境中等价的结果。
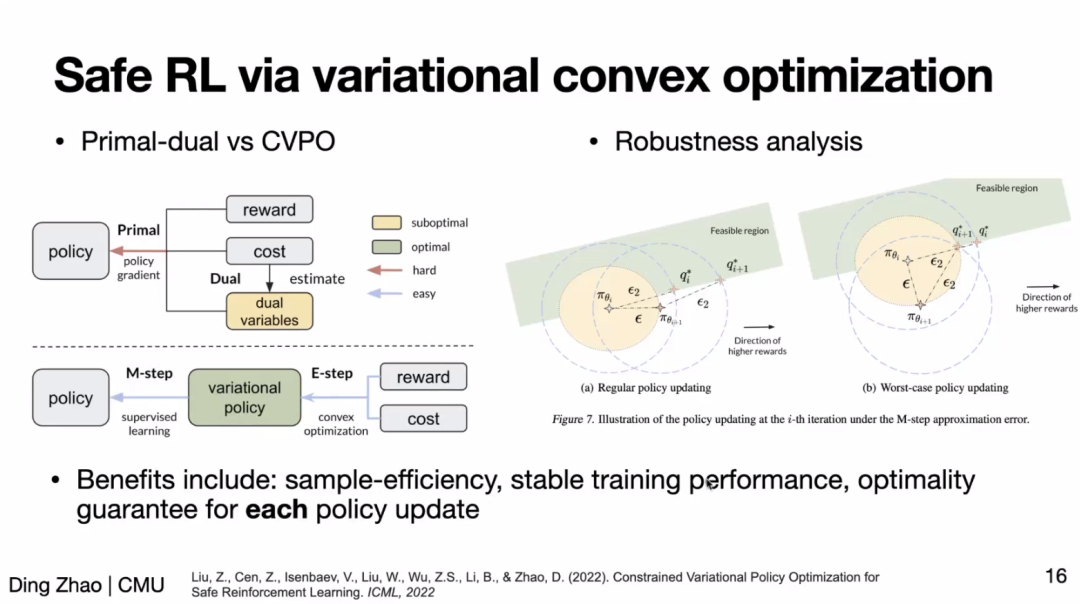
进一步地,为了获得一个安全的任务策略,目前主要的范式是通过安全强化学习(Safe RL)。然而,Safe RL 的主流方法之一——基于拉格朗日对偶的方法——对超参(如拉格朗日乘子的学习率)很敏感,更新不稳定。为此,赵老师介绍了基于变分凸优化的 Safe RL 方法,该方法将用 E-M 更新取代了拉格朗日优化。其中 E-step 通过一个凸优化过程更新变分策略,M-step 则通过监督过程更新目标策略。实验结果表明,该方法取得了更好的样本效率(sample-efficiency)和更稳定的训练过程。
然而,更稳定的训练并不意味着策略对观测的噪声是足够鲁棒的。为此,赵老师继续介绍了在提升 Safe RL 鲁棒性方面的工作。对抗训练是被广泛采用的提升策略鲁棒性的方法,但是传统的对抗攻击在 Safe RL 场景并不那么有效:当策略受攻击性能降低的同时,往往也因不够激进而变得安全了。因此,该工作找到了在 Safe RL 场景下足够有效的攻击方法,并通过对抗训练,获得了显著鲁棒的策略。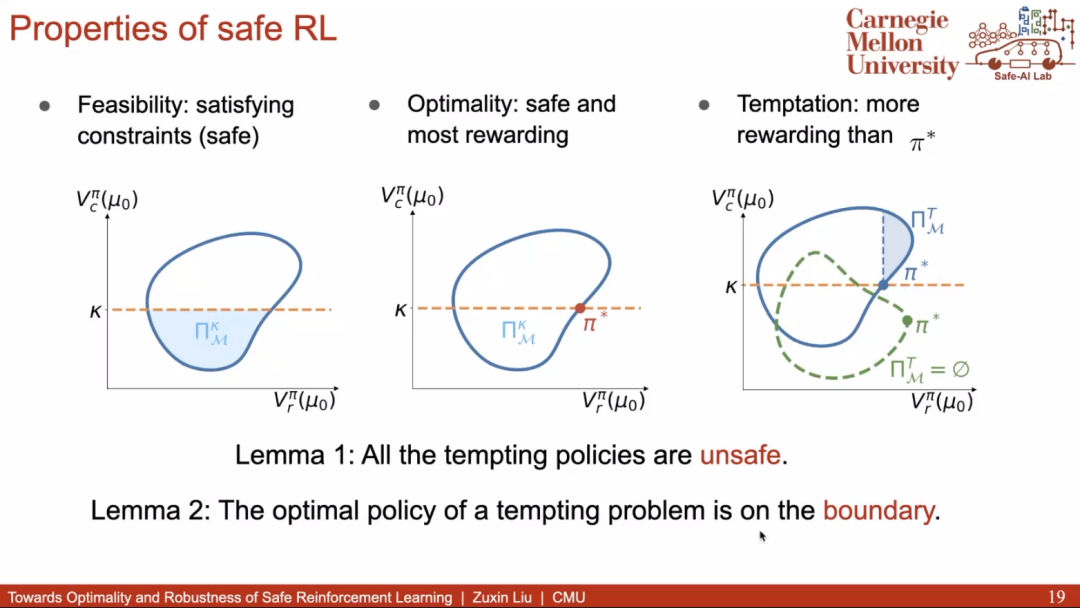

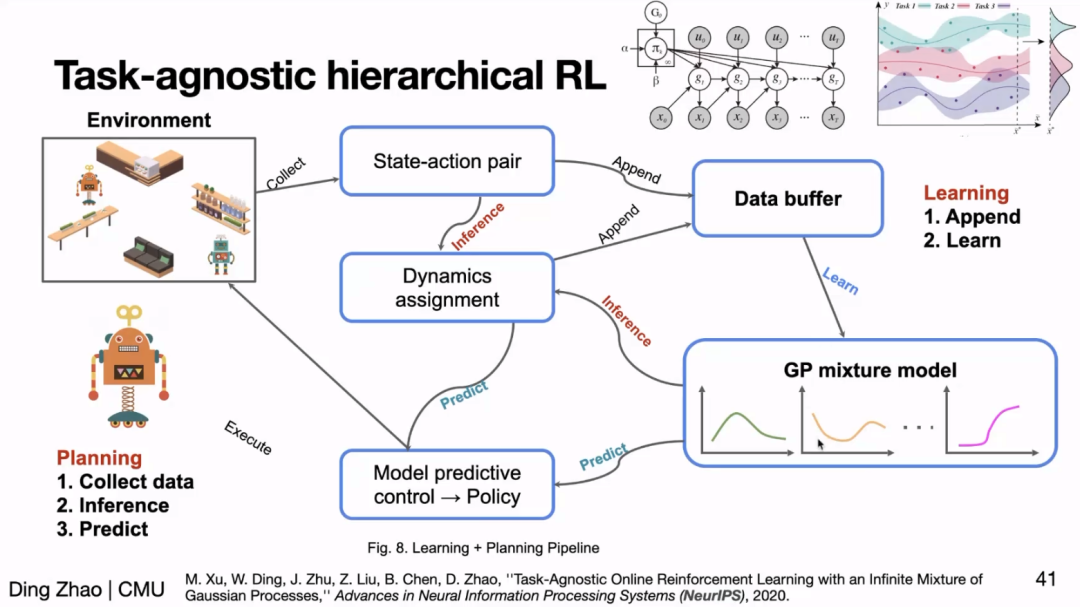
可信赖智能应当能应对变化丰富的场景,例如自动驾驶策略应该能应对每天不同时段的车况,这就要求 AI 策略要有很强的泛化性。在泛化性方面,赵老师首先介绍了基于分层强化学习(Hierarchical RL)的方法,它的底层可以自动学会任务不同场景下的策略,因此遇到新场景时,它也将自动切换为对应场景的策略从而实现泛化。
此外,赵老师还介绍了实现可泛化策略的另一途径:学习任务蕴含的本质因果关系(causal relationship)来帮助策略学习。随后,赵老师简单介绍了近期发表于 CoRL、NeurIPS 的系列工作,这些工作表明因果学习能显著帮助 RL 学习可泛化的策略、解决 RL 中的组合泛化性问题等。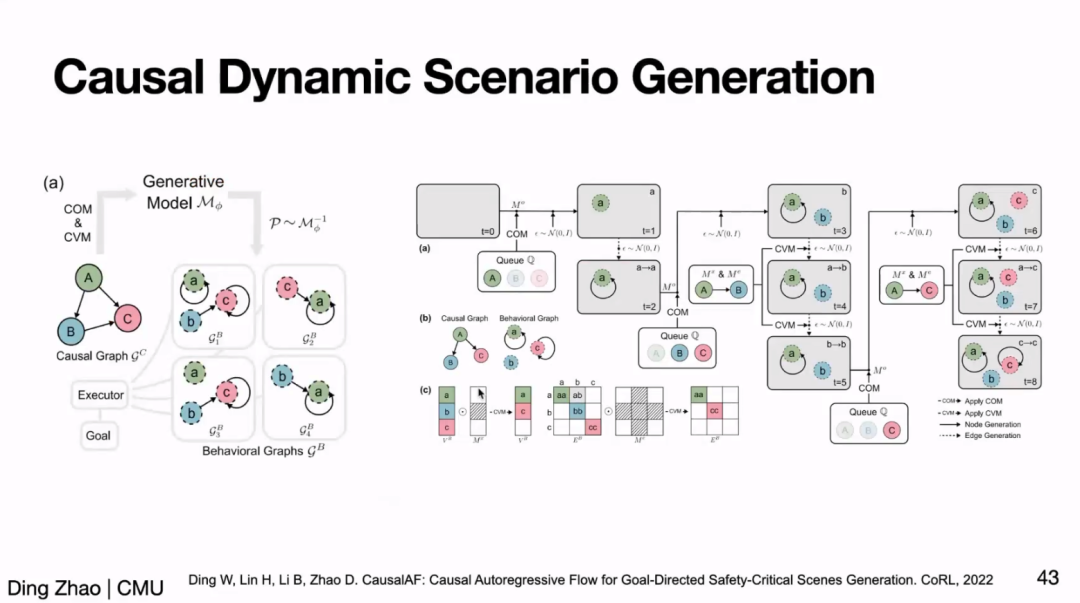
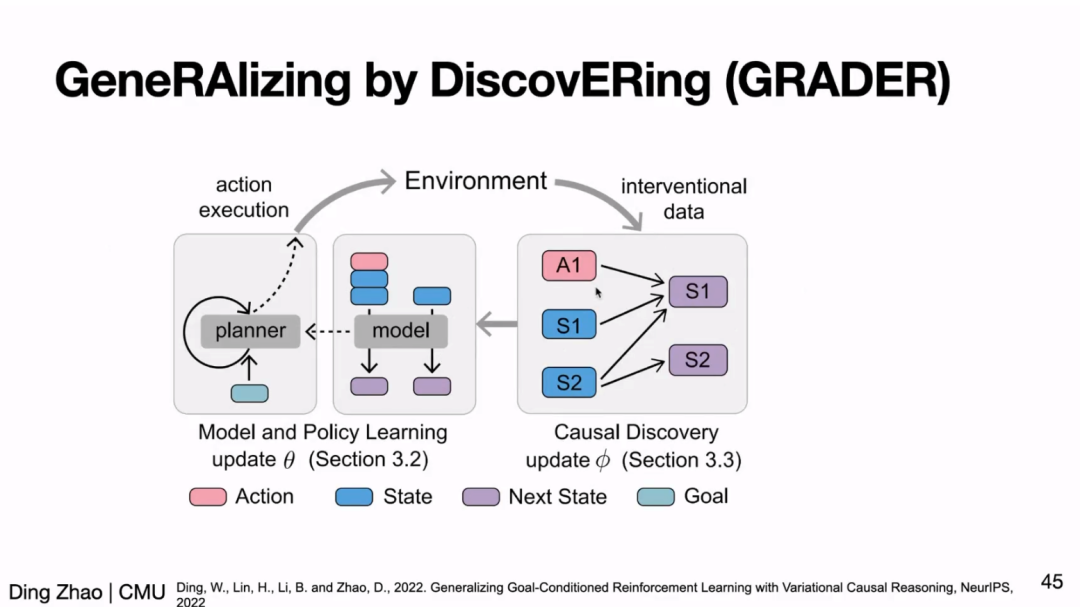
最后,赵老师总结了自己近年来在可信赖智能上的耕耘历程,并在 Q&A 阶段与参会同学们讨论了当前工作的局限和未来工作的方向。
报告视频回放:
报告概要及报告人简介:
On the Safety and Generalizability of Trustworthy Intelligent Autonomy

图文 | 吴铭东 PKU Hyperplane Lab
