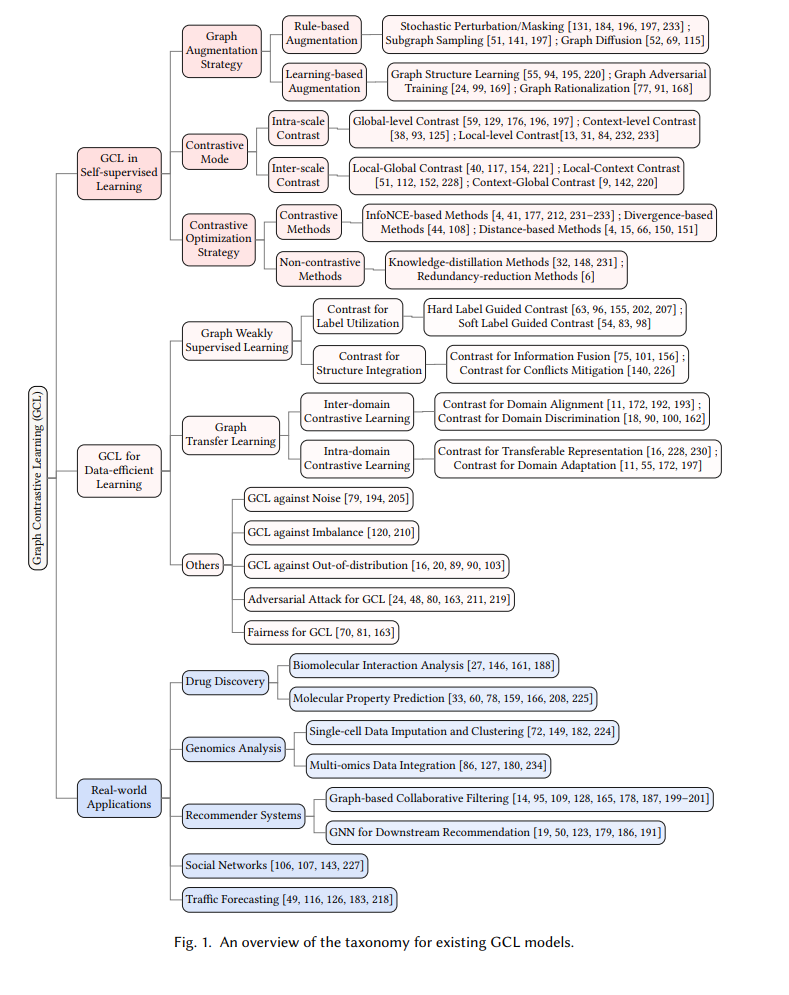
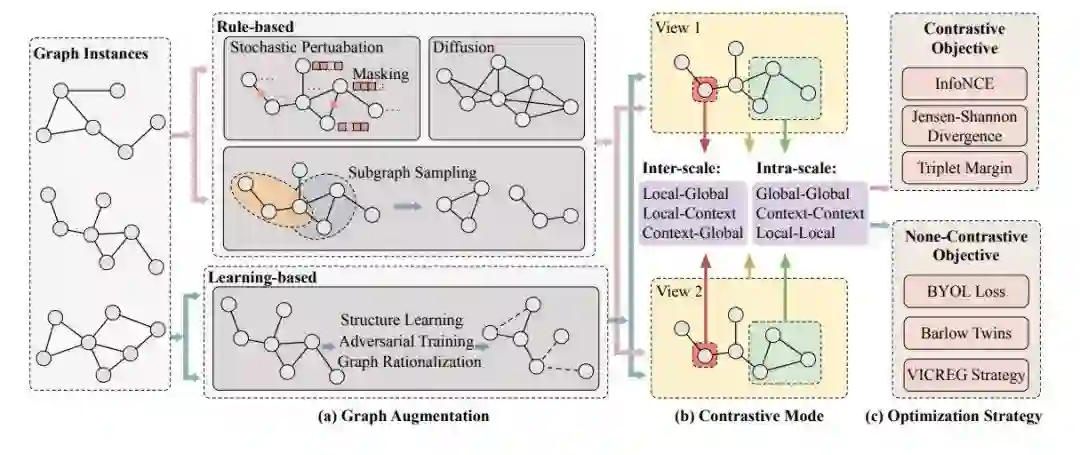
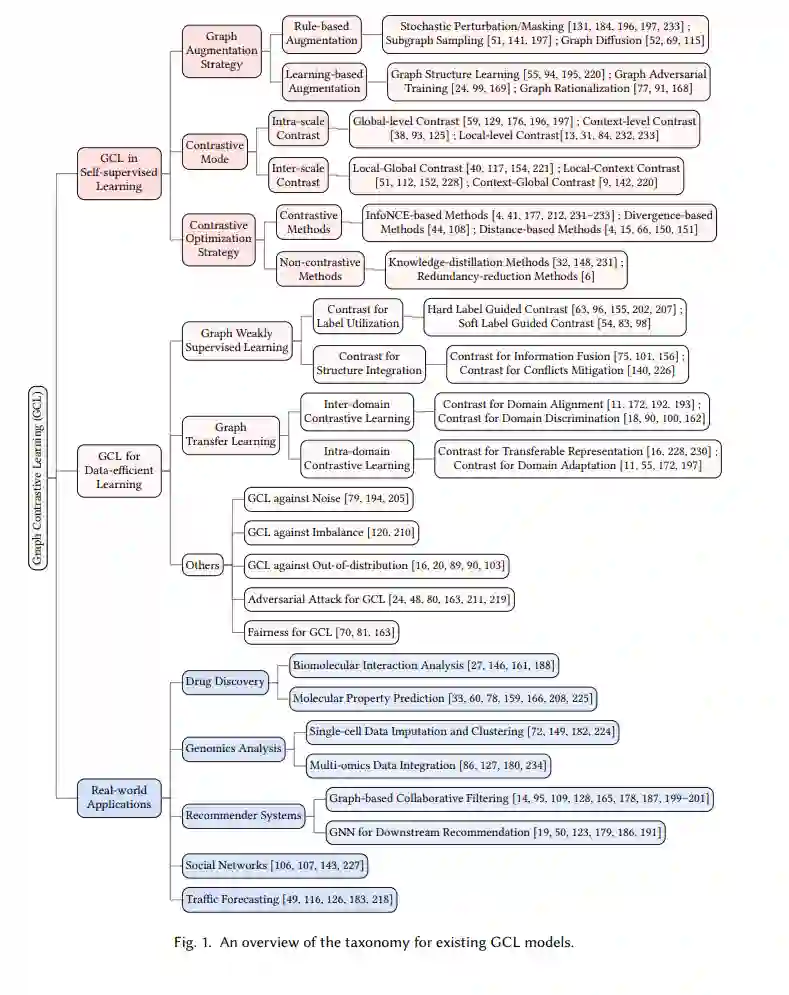
近年来,深度学习在图数据上的应用在多个领域取得了显著成功。然而,由于注释图数据的成本高昂且耗时,其依赖性仍然是一个重要的瓶颈。为了解决这一挑战,图数据上的自监督学习(自监督学习)引起了越来越多的关注,并取得了显著进展。自监督学习使机器学习模型能够从未标注的图数据中生成有信息量的表示,从而减少对昂贵标注数据的依赖。尽管自监督学习在图数据上得到了广泛应用,但一个关键组件——图对比学习(Graph Contrastive Learning, GCL)在现有文献中尚未得到充分研究。因此,本综述旨在填补这一空白,提供关于GCL的专题综述。我们对GCL的基本原理进行全面概述,包括数据增强策略、对比模式和对比优化目标。此外,我们探讨了GCL在其他数据高效图学习中的扩展,如弱监督学习、迁移学习和相关场景。我们还讨论了GCL在药物发现、基因组学分析、推荐系统等领域的实际应用,最后概述了该领域的挑战和未来可能的发展方向。
图结构数据在各个领域中广泛存在,从社交网络[3, 136]到推荐系统[62, 122, 173]、生物网络[23, 220]和知识图谱[12, 185]。随着图神经网络(Graph Neural Networks, GNNs)受欢迎程度的提升和取得的显著成功,图上的深度学习在诸多领域引起了极大关注[57, 65, 67, 175]。然而,尽管GNNs得到了广泛采用,一个基本挑战仍然存在——大多数GNN模型都针对(半)监督学习场景[30, 66, 67, 104]进行定制。这需要大量标注数据的支持,这极大地限制了图深度学习方法在实际中的应用。这一限制在医疗和分子化学等领域尤为明显。在这些领域中,获取标注数据需要专业知识和大量手工注释工作。此外,这些领域中的图数据通常有限、获取成本高或难以获取。例如,在医疗领域,构建患者交互网络或疾病进展图可能需要对医疗程序和病情有深入了解,并进行详尽的文档记录和注释工作[76]。同样,在分子化学中,识别化合物的性质需要化学合成和实验验证方面的专业知识,以及大量的数据收集和分析资源[60]。
为了解决标注数据稀缺和难以获取的问题,自监督学习(自监督学习)作为一种有前途的解决方案应运而生[15, 17, 32, 42, 132]。自监督学习通过使用前置任务从未标注数据中自动提取有意义的表示,从而减少对人工标注的依赖。通过设计利用数据本身内在结构的前置任务,自监督学习可以从未注释的数据集中挖掘出丰富的信息,从而提高模型性能和泛化能力[56, 88]。近年来,自监督学习在计算机视觉(CV)和自然语言处理(NLP)领域取得了显著进展,展示了未来应用的广阔前景。
在计算机视觉领域,自监督学习方法利用图像变换下的语义不变性来学习视觉特征。例如,像SimCLR[15]和Moco[42]这样的模型,关注于最大化同一图像的不同增强视图之间的一致性,使模型能够捕捉到跨变换的稳健和不变特征。在自然语言处理领域,自监督学习依赖于语言前置任务进行预训练。最近的进展,尤其以BERT[17]等模型为代表,利用大规模语言模型在掩蔽语言建模和下一个句子预测等任务上进行训练,在多个任务上实现了最先进的性能。
继承自监督学习在计算机视觉和自然语言处理中的成功,越来越多的兴趣延伸到了图结构数据的自监督学习[40, 46, 47, 102, 125, 154, 198]。然而,将自监督学习直接应用于图结构数据面临着重大挑战。首先,计算机视觉和自然语言处理主要处理欧几里得数据,而图结构数据引入了非欧几里得复杂性,使得传统的自监督学习方法效果较差[175]。其次,与计算机视觉和自然语言处理中的数据点独立性不同,图数据通过复杂的拓扑结构交织在一起,需要创新的方法来有效利用这些关系[57, 64]。因此,设计能够无缝集成节点特征和图结构的图特定前置任务成为一个关键且具有挑战性的课题。
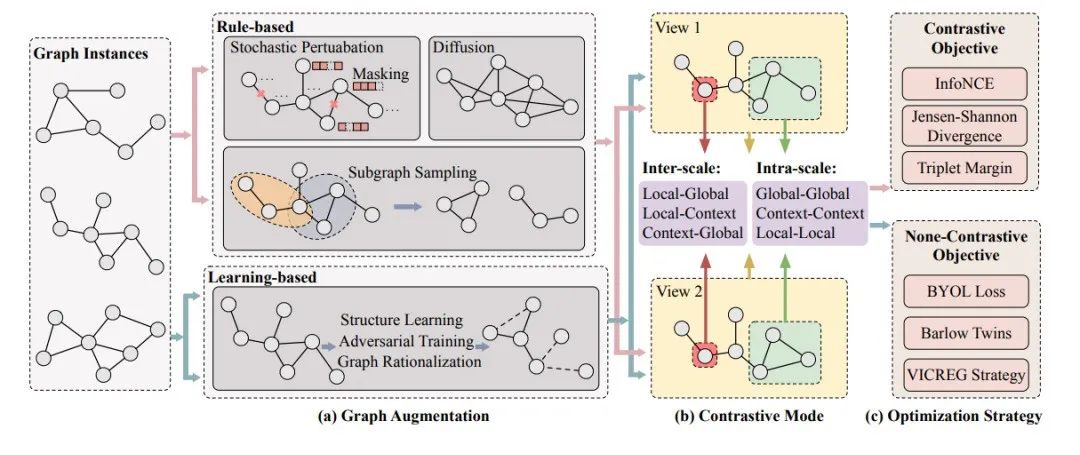
近年来,一些关于图自监督学习的文献综述提出了一个全面的框架[53, 92, 171, 181]。这些综述总结了一种新颖的范式,强调通过精心设计的前置任务来高效提取有意义的图表示。这些综述将前置任务分类为各种类型,如基于对比的、基于生成的和基于预测的方法。基于对比的自监督学习方法旨在通过在嵌入空间中比较正例和负例来学习有效的表示[40, 125, 154]。基于生成的自监督学习方法则专注于重构输入数据,并利用其作为监督信号,旨在生成能够捕捉图数据中潜在结构和模式的表示[47, 198]。基于预测的自监督学习技术涉及预测图结构或节点属性的某些方面,作为辅助任务来指导表示学习[46, 118]。
尽管现有文献综述对图自监督学习范式提供了全面覆盖,但它们往往缺乏对具体方面的深入分析。这种不足可能源于该领域的广泛范围和同时开发的多种技术。例如,图对比学习(Graph Contrastive Learning, GCL)目前是研究最广泛的范式之一。然而,现有的图自监督学习文献通常只涵盖了GCL的基本原理,而没有充分探索其在各种情境和下游应用中的潜力。 为此,在本综述中,我们的主要关注点是提供对GCL的全面概述。重要的是,据我们所知,目前尚无专门研究GCL的专题综述。本文的整体结构如图1所示。技术上,我们首先总结了GCL在自监督学习中的基本原理,包括增强策略、对比模式和对比优化目标。随后,我们探讨了GCL在其他数据高效学习方面的扩展,如弱监督学习、迁移学习和其他相关情境。此外,我们讨论了GCL的实际应用,并概述了该领域的挑战和未来可能的发展方向。本综述的核心贡献可以总结如下:
图对比学习(Graph Contrastive Learning, GCL)的研究广泛且不断获得动力。然而,目前缺乏专门聚焦于GCL研究的综合性综述。通过提供本概述,我们的目标是填补文献中的一个关键空白,并提供宝贵的见解。
我们对GCL在自监督学习中的基本原理进行了详细阐述。这包括对增强策略、对比模式和优化目标的深入探索,揭示了驱动GCL有效性的核心机制。
我们进一步扩展探讨了GCL在弱监督学习、迁移学习和多样的数据高效学习环境中的应用,强调了GCL在提高学习效率和效果方面的能力。
我们讨论了GCL成功应用的实际案例,涵盖了药物发现、基因组分析、推荐系统、社交网络和交通预测等领域,展示了其实际相关性和影响。
我们指出了GCL领域面临的挑战,同时概述了未来研究和发展的有前景方向,展示了前方激动人心的研究前景。