

本文对多语言大型语言模型(Multilingual Large Language Models, MLLMs)的最新研究进行了全面综述。MLLMs不仅能够跨语言边界理解和生成语言,还代表了人工智能领域的重要进步。 首先,我们探讨了MLLMs的架构和预训练目标,重点分析了支持其多语言能力的关键组成部分和方法。随后,我们讨论了多语言预训练与对齐数据集的构建,强调数据质量与多样性在提升MLLM性能中的重要作用。 本文的一个重要关注点是MLLM的评估方法。我们提出了一个详细的分类体系和路线图,涵盖了MLLM在跨语言知识、推理、人类价值对齐、安全性、可解释性及特定领域应用方面的评估。具体而言,我们广泛讨论了多语言评估基准与数据集,并探讨了将LLMs本身作为多语言评估工具的可能性。 为了从黑箱转向白箱理解MLLM,我们还深入研究了多语言能力的可解释性、跨语言迁移以及模型中的语言偏差问题。
最后,我们全面回顾了MLLM在多个领域中的实际应用,包括生物学、医学、计算机科学、数学和法律。我们展示了这些模型如何在专业领域推动创新与改进,同时强调了在多语言社区和应用场景中部署MLLM所面临的挑战与机遇。与本综述相关的论文列表已整理并公开发布在Github仓库中。
简介
科学进步和技术创新是推动人类社会发展的重要动力,而语言科学与技术的最新进展是其中不可或缺的一部分。语言作为人类沟通的关键媒介,不仅促进了知识的积累和文化的传承,还因全球多语言环境的存在,成为经济、文化、政治等交流活动中的核心因素。随着全球化的不断深入,语言技术的发展以及对多语言理解的探索也在不断加速。 在当今的信息社会和人工智能(AI)时代,我们正处于知识可及性和认知革命的前沿。生成式大型语言模型(LLMs)作为这一转型的核心因素,以其卓越的语言处理能力推动了“语言智能”(Chang等,2024)的新维度。尽管仍处于起步阶段,这种智能形式正在迅速席卷科学研究和技术创新的各个领域。尤其当其涵盖不同语言和文化时,我们正在见证一种有可能超越人类认知极限的新型智能能力的诞生。因此,为LLMs赋予多语言能力已成为实现其全部潜能的关键任务。 多语言大型语言模型(Multilingual Large Language Model, MLLM)是一种旨在通过单一模型学习多语言能力的LLM。赋予AI模型多语言能力的努力可以追溯到基于统计方法的机器翻译系统,例如IBM的Candide系统(Hutchins, 1999),甚至更早期的基于规则的方法,这些方法依赖于人工设计的语言间表达对应关系。 十多年前,随着计算能力的快速提升和大数据时代的到来,基于神经网络的端到端多语言语言模型开始出现。2014年,Cho等(2014)提出了一种基于注意力机制的神经机器翻译模型,大幅提升了翻译质量。2016年,谷歌研究团队推出了GNMT神经机器翻译系统,该系统基于大规模语料库构建,在多种语言对之间实现了最先进的性能。 这些早期的多语言模型通常需要针对每对语言单独训练和优化,缺乏可扩展性和泛化能力。为了解决这一瓶颈,新一代预训练多语言语言模型逐步涌现。2019年,Devlin等(2019)提出了BERT模型,通过在大规模多语言语料库上进行预训练,显著提升了跨语言迁移能力。此后,一系列多语言预训练语言模型相继问世,包括XLM(Conneau & Lample, 2019a)、mBART(Liu等,2020)等,进一步拓展了多语言建模的潜力。研究者开始不再将多语言处理视为机器翻译的延伸,而是作为理解和处理跨语言语义的一种整体能力。 为了提高模型在海量多语言数据上的训练效率,创新的训练目标和架构不断被提出,例如XLM-R(Conneau等,2020a)的去噪自动编码和mT5(Xue等,2021)的多任务架构,仅举几例。 ChatGPT(OpenAI, 2022)的迅速普及,仅两个月就吸引了超过一亿用户,进一步凸显了LLMs的变革潜力。这些模型的能力,包括自然文本生成、代码生成和工具使用,以及其令人惊讶的多语言能力,既引发了热情也提出了批判性问题(Zhang等,2024c;Tars等,2022)。 MLLM的发展之路并非一帆风顺。尽管许多综述探讨了MLLM的某些具体方面(Xu等,2024e;Qin等,2024),例如其训练数据、架构或应用,但对其多语言能力、局限性和挑战的全面研究尚属缺乏。此外,与负责任AI相关的关键问题,如公平性和有害性,在这一背景下尚未得到充分关注(Philippy等,2023;Tang等,2024)。 本综述旨在填补这一空白,全面审视MLLM的研究现状。我们将分析MLLM在处理语言多样性(包括非英语和低资源语言)方面面临的具体挑战,探索数据构建策略、模型训练和微调方法,以及负责任AI的核心问题。此外,我们还将深入研究MLLM在现实语言社区和应用领域中的部署面临的实际挑战。 通过本综述,我们希望为研究人员提供关于MLLM发展最前沿的视角,分析其在实现语言智能全部潜力方面的机遇与挑战。我们的目标是促进更包容和更负责任的语言技术开发,确保这些强大的工具能够为全球不同语言社区所用并从中受益。 通过探索多语言的复杂性,包括语言多样性、语言变体和多语言知识迁移,我们致力于弥合LLM研究现状与全球范围内公平高效语言理解之间的差距。通过对MLLM的全面审视,我们希望为语言智能赋能全球交流、促进文化理解,并释放多样化知识体系的潜能。
2 分类体系与路线图
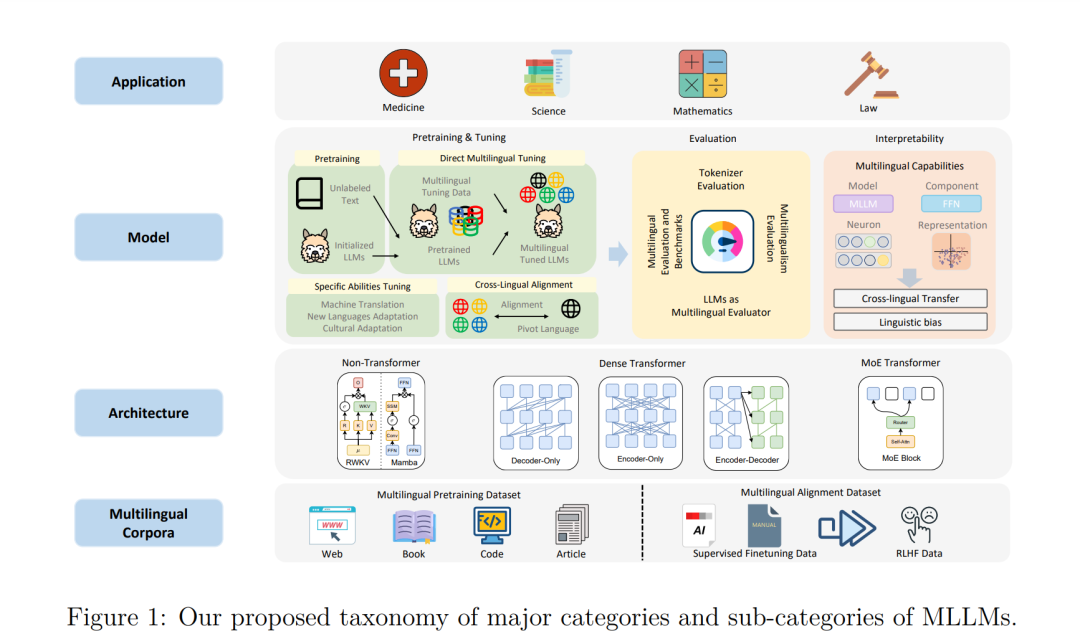
为全面概述快速发展的多语言大型语言模型(MLLMs)领域,本综述采用了一个结构化的分类体系,将研究范围分为六个基本且相互关联的领域:
- 多语言数据
本综述首先讨论多语言数据这一基础要素,涉及多样的数据来源,例如网络爬取数据、书籍和代码仓库。
- 神经网络架构
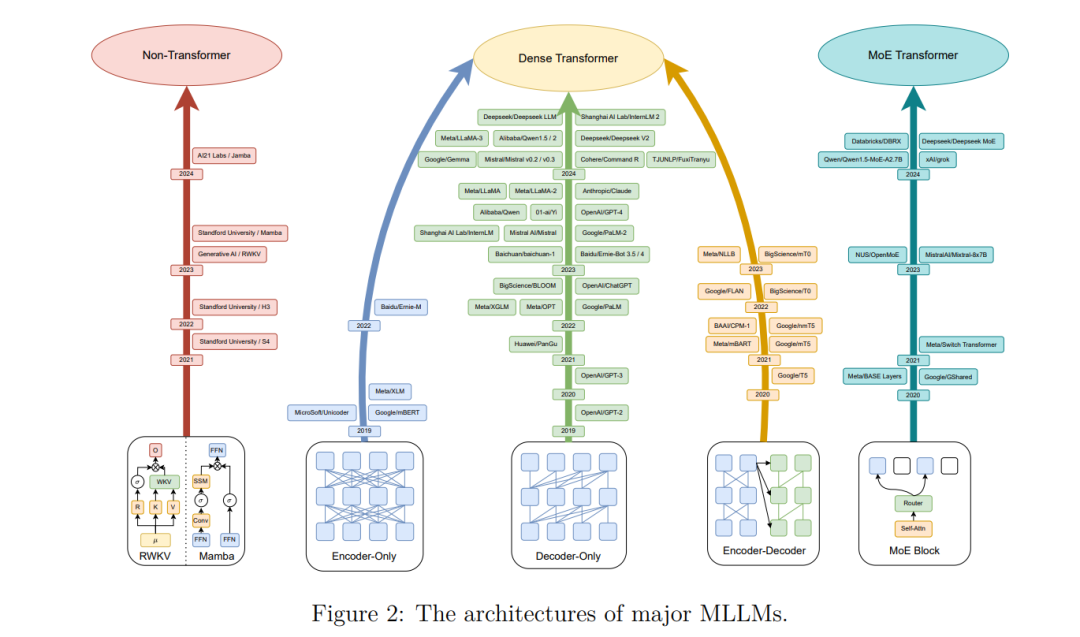
探讨用于构建高效MLLMs的神经网络架构选择,分析常见架构(如仅解码器和编码器-解码器架构)的优劣。
- 预训练与微调方法
在此基础上,综述了MLLMs的预训练和微调方法,涵盖了掩码语言建模、翻译语言建模等预训练目标,以及指令微调和偏好微调等微调技术。
- 性能评估
针对MLLMs的性能评估进行了全面回顾,重点探讨多语言评估基准和数据集,特别是如何在不同语言(包括低资源语言)之间实现平衡评估。
- 模型的可解释性与偏差
关注MLLMs的“黑箱”特性,讨论可解释性技术,研究模型如何实现其多语言能力,以及如何识别和缓解潜在的语言偏差(Gurgurov等,2024;Blevins等,2024;Nezhad & Agrawal,2024;Kojima等,2024b;Liu等,2024b)。
- 实际应用
展示MLLMs在现实世界中的多样化应用,重点分析其在不同领域的实践。
综述的总体目标是从这六个基本领域出发,如图1所示,提供对MLLMs领域的全面理解。
路线图概览
**第3节:架构与预训练目标
MLLMs通常采用仅解码器或编码器-解码器架构,其多语言知识的获取依赖于多语言语料库的训练。与单语言LLMs的主要架构区别在于,MLLMs需要更大的词汇表来应对“超出词汇表”的问题。在预训练目标方面,MLLMs既使用与单语言模型相似的技术(如掩码语言建模),也探索了增强跨语言能力的新目标,如翻译语言建模。
**第4节:训练数据
MLLMs的预训练阶段需要大量未标注的文本数据,而对齐阶段则需要带有平行数据的监督微调和基于反馈数据的强化学习。我们总结了多种预训练数据(如网络数据、书籍数据、代码数据和学术论文数据)的特点,并详细阐述了监督微调数据的生成方法,包括人工生成和模型辅助生成,以及强化学习反馈数据的收集过程。
**第5节:预训练过程
本节探讨了MLLMs预训练中的数据筛选过程、预训练目标的设定,以及文献中探索的预训练策略。
**第6节:多语言微调策略
为了将MLLMs的通用能力调整为特定目标,本节讨论了直接扩展LLMs到多语言环境的微调方法,重点关注多语言数据收集和跨语言迁移。此外,还介绍了在多语言微调过程中进一步增强跨语言对齐的策略,并阐述了用于提升特定多语言能力的专门微调技术。
**第7节:性能评估
本节深入探讨了MLLMs的评估方法,包括从多语言分词到数据集和基准的评估,用以衡量MLLMs在多语言上下文中完成不同任务的能力。此外,还分析了用于确定MLLMs多语言性能的评估方法,并探索将MLLMs自身用作评估工具的可能性。
**第8节:从黑箱到白箱
为将MLLMs从“黑箱”转变为“白箱”,本节探讨了模型如何表征其多语言能力,并解决了高级问题,如跨语言迁移和语言偏差的成因。
**第9节:应用与实践
最后,本节对MLLMs在不同学科领域的进化路径和最新突破进行了深入研究,特别关注其实际应用与实施。
核心问题
通过这一分类体系与路线图,我们希望解答以下关键问题:
-
MLLMs的能力是什么?
-
MLLMs的语言边界在哪里?
-
构建和微调MLLMs时需要考虑哪些因素?
-
如何评估MLLMs的多语言迁移能力?
本综述旨在为研究人员提供一幅清晰的MLLMs研究全景图,为推动多语言智能的全面发展奠定基础。

