

生成式数据增强(GDA)已成为缓解机器学习应用中数据稀缺问题的有前景技术。本论文提供了GDA领域的全面综述和统一框架。首先,我们简要介绍GDA,讨论其动机、分类法和与合成数据生成的主要区别。接下来,我们系统地分析了GDA的关键方面 - 选择生成模型、使用它们的技术、数据选择方法、验证方法以及各种应用。我们提议的统一框架对广泛的GDA文献进行了分类,揭示了例如缺乏通用基准的缺口。这篇论文总结了有前景的研究方向,包括有效的数据选择、大规模模型在GDA中的应用的理论发展和为GDA建立基准。通过建立一个结构化的基础,本论文旨在促进生成式数据增强这一重要领域的更有凝聚力的发展和加快进展。
在当代机器学习领域中,深度学习算法已经成为众多任务的强大工具,展示了前所未有的准确性和能力[1; 2; 3]。然而,它们效能的关键基石在于它们能够访问大量的数据[4; 5; 6]。在当今的数字环境中,收集如此广泛和原始的数据集,矛盾地,证明是复杂的,并可能昂贵得令人望而却步。这种数据收集的复杂性源于多方面的挑战,包括但不限于隐私关注[7; 8],多样化的数据来源,以及需要费劲标注的需求[9]。 因此,科学界已经转向数据增强技术,作为一个务实的解决方案,以抵消可用数据的匮乏。数据增强是指一套用于人为扩大数据集的容量和多样性的技术,通过对其现有条目进行控制修改,而不改变它们的固有语义解释[11; 12]。传统的数据增强方法[10],虽然很好,但主要围绕线性变换或初级的非线性修改。尽管这些方法有益,但它们已经显示出了局限性,尤其是在它们显著提高模型性能的能力方面,特别是当底层数据多样化时。
认识到这些局限性,研究人员越来越感兴趣于探索更为复杂的数据增强途径。在这一追求中的一个显著方向是集成生成模型进行数据增强,即生成式数据增强(GDA)。生成模型的吸引力在于它们固有的模拟数据复杂概率分布的能力[13; 14; 15],从而提供了更为细致和广泛的增强景观。通过挖掘这种潜力,生成式数据增强为改进深度学习模型性能提供了一个有前景的视野,特别是在数据有限的情境中。 本文提供了关于生成式数据增强(GDA)的全面综述。虽然该领域已经见证了众多的方法和方法论,但这些技术的结构化和统一的理解通常是难以捉摸的。许多作品将GDA应用于某个数据集,但在GDA的发展上鲜有创新和贡献。统一的框架可以通过提供清晰的结构和分类来解决这个问题,使研究人员更容易识别缺口并基于现有方法进行构建。
为了解决这个缺口,我们提出了一个统一框架,系统地对GDA的广泛景观进行了分类。这个框架作为一个路线图,指导读者了解GDA的多方面:从选择生成模型,到利用它们的技术,选择高质量合成数据的策略,验证这些数据的方法,以及GDA被证明是关键的各种应用。
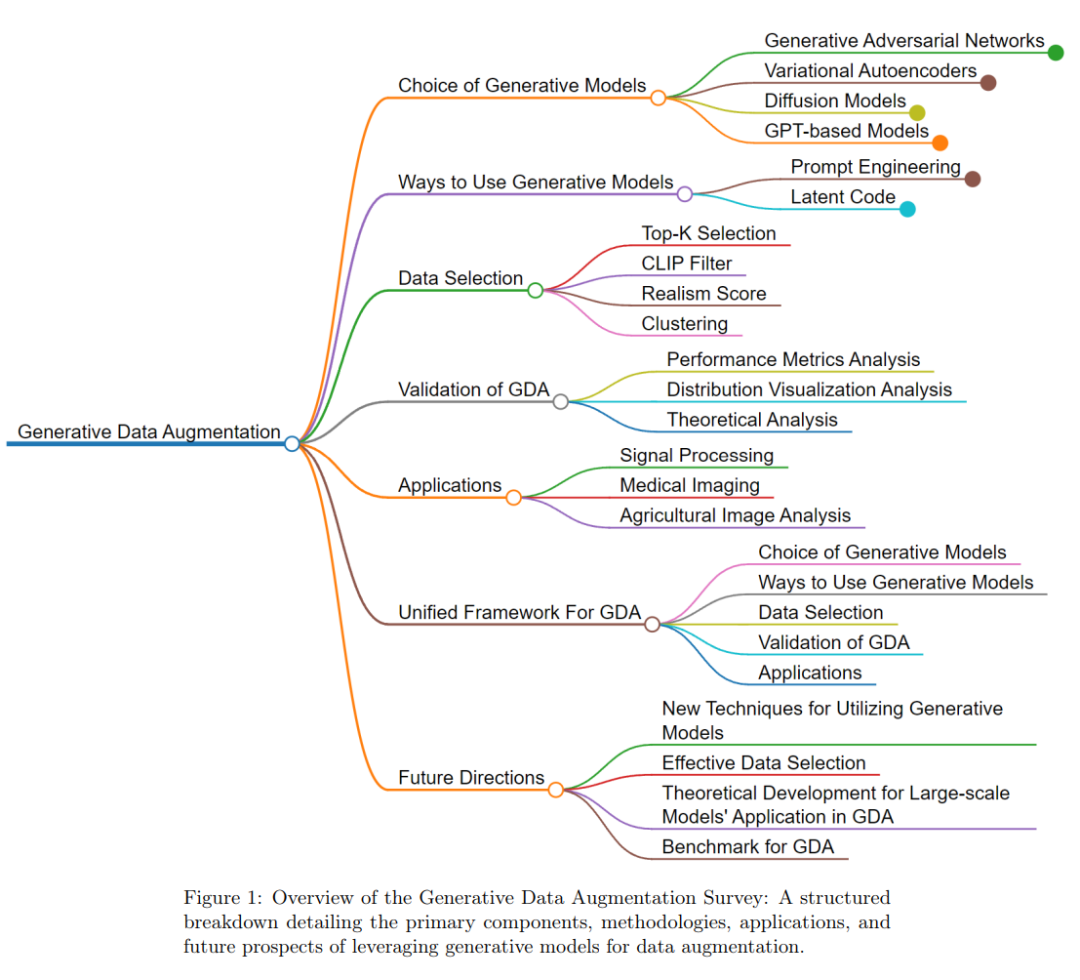
总数组织
第2节:初步 - 本节提供了关于生成式数据增强(GDA)的基础知识。本文中使用的核心概念、关键术语、符号和概念都将在此处呈现。第3节:选择生成模型 - 在此,我们深入探讨了我们可用的各种生成结构。从传统的VAEs[16; 17; 18; 19; 20; 21]和GANs[22; 23; 24; 25; 26; 27; 28; 29; 30],到新兴的基于GPT[31; 32; 33; 34; 35; 36; 37; 38; 39; 40]和基于扩散的创新[41; 42; 43; 44; 45; 46; 47],我们阐明了它们的机制、优点、缺点和使用场景。第4节:利用技术 - 本段专门探讨如何有效利用选定的生成模型。我们探索了潜在空间操作和提示工程,评估它们对数据质量和相关性的影响。第5节:合成数据的选择策略 - 考虑到生成的大量合成数据,我们如何筛选最好的数据?本节深入探讨了帮助提高合成数据质量的技术,无论是既定的还是新兴的。第6节:合成数据的验证 - GDA的一个关键方面是验证生成样本的可靠性。在此,我们涵盖了确定合成数据集的质量和相关性的理论和实证方法。第7节:GDA的应用 - 在这一部分,GDA的多功能性是首要的。我们概述了其在多个领域的变革潜力,从医疗保健的医学成像到农业等领域的应用。第8节:生成式数据增强的统一框架 - 基于前几节的见解,我们介绍并详细描述了我们提议的统一框架。本节阐明了框架结构背后的理念以及如何简化从模型选择到应用的GDA过程。第9节:当前挑战和未来方向 - 当我们接近综述的结束时,本节对GDA的持续挑战进行了反思,并设想了潜在的突破。它为希望进一步拓展GDA边界的研究者提供了指导。统一框架也可以视为本文的流程,在图1中可以直观地看到。本综述的主要贡献如下:
广泛且最新的编译:从过去三年中的230多部开创性工作中摘录,本综述提供了关于生成式数据增强(GDA)的最全面的评论,有效地捕捉了该领域的快速进展。
统一框架提案:我们引入了一个结构化和有凝聚力的GDA框架,包括模型选择、利用技术、合成数据选择、验证和应用。这为研究者和实践者提供了一个系统的指南,用于改进GDA并在各种背景下实施GDA。
深入选择和验证:我们的综述深入探讨了合成数据选择和验证的细微差别,这在以前的研究中很少受到关注,强调了GDA技术的有效部署中它们的重要性。
未来路线图:从广泛的文献综述中受益,我们辨别并讨论了现有的挑战和潜在的突破途径,为GDA的未来研究提供了一个有远见的路线图。

